
In probability theory, the expected value is a generalization of the weighted average. Informally, the expected value is the arithmetic mean of the possible values a random variable can take, weighted by the probability of those outcomes. Since it is obtained through arithmetic, the expected value sometimes may not even be included in the sample data set; it is not the value you would "expect" to get in reality.
A random variable is a mathematical formalization of a quantity or object which depends on random events. The term 'random variable' can be misleading as its mathematical definition is not actually random nor a variable, but rather it is a function from possible outcomes in a sample space to a measurable space, often to the real numbers.
Independence is a fundamental notion in probability theory, as in statistics and the theory of stochastic processes. Two events are independent, statistically independent, or stochastically independent if, informally speaking, the occurrence of one does not affect the probability of occurrence of the other or, equivalently, does not affect the odds. Similarly, two random variables are independent if the realization of one does not affect the probability distribution of the other.

In probability theory, a martingale is a sequence of random variables for which, at a particular time, the conditional expectation of the next value in the sequence is equal to the present value, regardless of all prior values.
In mathematics, Fatou's lemma establishes an inequality relating the Lebesgue integral of the limit inferior of a sequence of functions to the limit inferior of integrals of these functions. The lemma is named after Pierre Fatou.

In mathematics, Jensen's inequality, named after the Danish mathematician Johan Jensen, relates the value of a convex function of an integral to the integral of the convex function. It was proved by Jensen in 1906, building on an earlier proof of the same inequality for doubly-differentiable functions by Otto Hölder in 1889. Given its generality, the inequality appears in many forms depending on the context, some of which are presented below. In its simplest form the inequality states that the convex transformation of a mean is less than or equal to the mean applied after convex transformation; it is a simple corollary that the opposite is true of concave transformations.

In probability theory and statistics, the term Markov property refers to the memoryless property of a stochastic process, which means that its future evolution is independent of its history. It is named after the Russian mathematician Andrey Markov. The term strong Markov property is similar to the Markov property, except that the meaning of "present" is defined in terms of a random variable known as a stopping time.
The proposition in probability theory known as the law of total expectation, the law of iterated expectations (LIE), Adam's law, the tower rule, and the smoothing theorem, among other names, states that if is a random variable whose expected value is defined, and is any random variable on the same probability space, then
In probability theory and statistics, the conditional probability distribution is a probability distribution that describes the probability of an outcome given the occurrence of a particular event. Given two jointly distributed random variables and , the conditional probability distribution of given is the probability distribution of when is known to be a particular value; in some cases the conditional probabilities may be expressed as functions containing the unspecified value of as a parameter. When both and are categorical variables, a conditional probability table is typically used to represent the conditional probability. The conditional distribution contrasts with the marginal distribution of a random variable, which is its distribution without reference to the value of the other variable.
In mathematics, a π-system on a set is a collection of certain subsets of such that
This article discusses how information theory is related to measure theory.
In mathematics, uniform integrability is an important concept in real analysis, functional analysis and measure theory, and plays a vital role in the theory of martingales.
In probability theory, a random measure is a measure-valued random element. Random measures are for example used in the theory of random processes, where they form many important point processes such as Poisson point processes and Cox processes.
In probability theory, a standard probability space, also called Lebesgue–Rokhlin probability space or just Lebesgue space is a probability space satisfying certain assumptions introduced by Vladimir Rokhlin in 1940. Informally, it is a probability space consisting of an interval and/or a finite or countable number of atoms.
In mathematics – specifically, in the theory of stochastic processes – Doob's martingale convergence theorems are a collection of results on the limits of supermartingales, named after the American mathematician Joseph L. Doob. Informally, the martingale convergence theorem typically refers to the result that any supermartingale satisfying a certain boundedness condition must converge. One may think of supermartingales as the random variable analogues of non-increasing sequences; from this perspective, the martingale convergence theorem is a random variable analogue of the monotone convergence theorem, which states that any bounded monotone sequence converges. There are symmetric results for submartingales, which are analogous to non-decreasing sequences.
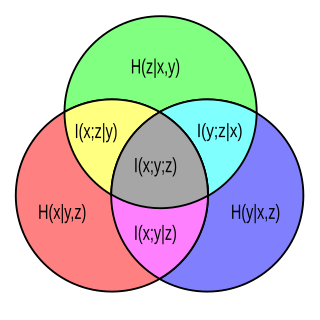
In probability theory, particularly information theory, the conditional mutual information is, in its most basic form, the expected value of the mutual information of two random variables given the value of a third.
In probability theory, regular conditional probability is a concept that formalizes the notion of conditioning on the outcome of a random variable. The resulting conditional probability distribution is a parametrized family of probability measures called a Markov kernel.
In probability theory, a Markov kernel is a map that in the general theory of Markov processes plays the role that the transition matrix does in the theory of Markov processes with a finite state space.
In probability theory, the Doob–Dynkin lemma, named after Joseph L. Doob and Eugene Dynkin, characterizes the situation when one random variable is a function of another by the inclusion of the -algebras generated by the random variables. The usual statement of the lemma is formulated in terms of one random variable being measurable with respect to the -algebra generated by the other.
In probability theory, the g-expectation is a nonlinear expectation based on a backwards stochastic differential equation (BSDE) originally developed by Shige Peng.
























































![Conditional expectation with respect to a s-algebra: in this example the probability space
(
O
,
F
,
P
)
{\displaystyle (\Omega ,{\mathcal {F}},P)}
is the [0,1] interval with the Lebesgue measure. We define the following s-algebras:
A
=
F
{\displaystyle {\mathcal {A}}={\mathcal {F}}}
;
B
{\displaystyle {\mathcal {B}}}
is the s-algebra generated by the intervals with end-points 0,
.mw-parser-output .frac{white-space:nowrap}.mw-parser-output .frac .num,.mw-parser-output .frac .den{font-size:80%;line-height:0;vertical-align:super}.mw-parser-output .frac .den{vertical-align:sub}.mw-parser-output .sr-only{border:0;clip:rect(0,0,0,0);clip-path:polygon(0px 0px,0px 0px,0px 0px);height:1px;margin:-1px;overflow:hidden;padding:0;position:absolute;width:1px}
1/4,
1/2,
3/4, 1; and
C
{\displaystyle {\mathcal {C}}}
is the s-algebra generated by the intervals with end-points 0,
1/2, 1. Here the conditional expectation is effectively the average over the minimal sets of the s-algebra. LokaleMittelwertbildung.svg](http://upload.wikimedia.org/wikipedia/commons/thumb/7/74/LokaleMittelwertbildung.svg/330px-LokaleMittelwertbildung.svg.png)








































































































































