In computer science, fractional cascading is a technique to speed up a sequence of binary searches for the same value in a sequence of related data structures. The first binary search in the sequence takes a logarithmic amount of time, as is standard for binary searches, but successive searches in the sequence are faster. The original version of fractional cascading, introduced in two papers by Chazelle and Guibas in 1986 (Chazelle & Guibas 1986a; Chazelle & Guibas 1986b), combined the idea of cascading, originating in range searching data structures of Lueker (1978) and Willard (1978), with the idea of fractional sampling, which originated in Chazelle (1983). Later authors introduced more complex forms of fractional cascading that allow the data structure to be maintained as the data changes by a sequence of discrete insertion and deletion events.
As a simple example of fractional cascading, consider the following problem. We are given as input a collection of k ordered lists Li of numbers, such that the total length Σ|Li| of all lists is n, and must process them so that we can perform binary searches for a query value q in each of the k lists. For instance, with k = 4 and n = 17,
L1 = 24, 64, 65, 80, 93
L2 = 23, 25, 26
L3 = 13, 44, 62, 66
L4 = 11, 35, 46, 79, 81
The simplest solution to this searching problem is just to store each list separately. If we do so, the space requirement is O(n), but the time to perform a query is O(k log(n/k)), as we must perform a separate binary search in each of k lists. The worst case for querying this structure occurs when each of the k lists has equal size n/k, so each of the k binary searches involved in a query takes time O(log(n/k)).
A second solution allows faster queries at the expense of more space: we may merge all the k lists into a single big list L, and associate with each item x of L a list of the results of searching for x in each of the smaller lists Li. If we describe an element of this merged list as x[a,b,c,d] where x is the numerical value and a, b, c, and d are the positions (the first number has position 0) of the next element at least as large as x in each of the original input lists (or the position after the end of the list if no such element exists), then we would have
L = 11[0,0,0,0], 13[0,0,0,1], 23[0,0,1,1], 24[0,1,1,1], 25[1,1,1,1], 26[1,2,1,1],
This merged solution allows a query in time O(log n+k): simply search for q in L and then report the results stored at the item x found by this search. For instance, if q = 50, searching for q in L finds the item 62[1,3,2,3], from which we return the results L1[1] = 64, L2[3] (a flag value indicating that q is past the end of L2), L3[2] = 62, and L4[3] = 79. However, this solution pays a high penalty in space complexity: it uses space O(kn) as each of the n items in L must store a list of k search results.
Fractional cascading allows this same searching problem to be solved with time and space bounds meeting the best of both worlds: query time O(log n+k), and space O(n). The fractional cascading solution is to store a new sequence of lists Mi. The final list in this sequence, Mk, is equal to Lk; each earlier list Mi is formed by merging Li with every second item from Mi+1. With each item x in this merged list, we store two numbers: the position resulting from searching for x in Li and the position resulting from searching for x in Mi+1. For the data above, this would give us the following lists:
Suppose we wish to perform a query in this structure, for q = 50. We first do a standard binary search for q in M1, finding the value 64[1,5]. The "1" in 64[1,5], tells us that the search for q in L1 should return L1[1] = 64. The "5" in 64[1,5] tells us that the approximate location of q in M2 is position 5. More precisely, binary searching for q in M2 would return either the value 79[3,5] at position 5, or the value 62[3,3] one place earlier. By comparing q to 62, and observing that it is smaller, we determine that the correct search result in M2 is 62[3,3]. The first "3" in 62[3,3] tells us that the search for q in L2 should return L2[3], a flag value meaning that q is past the end of list L2. The second "3" in 62[3,3] tells us that the approximate location of q in M3 is position 3. More precisely, binary searching for q in M3 would return either the value 62[2,3] at position 3, or the value 44[1,2] one place earlier. A comparison of q with the smaller value 44 shows us that the correct search result in M3 is 62[2,3]. The "2" in 62[2,3] tells us that the search for q in L3 should return L3[2] = 62, and the "3" in 62[2,3] tells us that the result of searching for q in M4 is either M4[3] = 79[3,0] or M4[2] = 46[2,0]; comparing q with 46 shows that the correct result is 79[3,0] and that the result of searching for q in L4 is L4[3] = 79. Thus, we have found q in each of our four lists, by doing a binary search in the single list M1 followed by a single comparison in each of the successive lists.
More generally, for any data structure of this type, we perform a query by doing a binary search for q in M1, and determining from the resulting value the position of q in L1. Then, for each i > 1, we use the known position of q in Mi to find its position in Mi+1. The value associated with the position of q in Mi points to a position in Mi+1 that is either the correct result of the binary search for q in Mi+1 or is a single step away from that correct result, so stepping from i to i+1 requires only a single comparison. Thus, the total time for a query is O(log n+k).
In our example, the fractionally cascaded lists have a total of 25 elements, less than twice that of the original input. In general, the size of Mi in this data structure is at most
as may easily be proven by induction. Therefore, the total size of the data structure is at most
as may be seen by regrouping the contributions to the total size coming from the same input list Li together with each other.
The general problem
In general, fractional cascading begins with a catalog graph, a directed graph in which each vertex is labeled with an ordered list. A query in this data structure consists of a path in the graph and a query value q; the data structure must determine the position of q in each of the ordered lists associated with the vertices of the path. For the simple example above, the catalog graph is itself a path, with just four nodes. It is possible for later vertices in the path to be determined dynamically as part of a query, in response to the results found by the searches in earlier parts of the path.
To handle queries of this type, for a graph in which each vertex has at most d incoming and at most d outgoing edges for some constant d, the lists associated with each vertex are augmented by a fraction of the items from each outgoing neighbor of the vertex; the fraction must be chosen to be smaller than 1/d, so that the total amount by which all lists are augmented remains linear in the input size. Each item in each augmented list stores with it the position of that item in the unaugmented list stored at the same vertex, and in each of the outgoing neighboring lists. In the simple example above, d = 1, and we augmented each list with a 1/2 fraction of the neighboring items.
A query in this data structure consists of a standard binary search in the augmented list associated with the first vertex of the query path, together with simpler searches at each successive vertex of the path. If a 1/r fraction of items are used to augment the lists from each neighboring item, then each successive query result may be found within at most r steps of the position stored at the query result from the previous path vertex, and therefore may be found in constant time without having to perform a full binary search.
Dynamic fractional cascading
In dynamic fractional cascading, the list stored at each node of the catalog graph may change dynamically, by a sequence of updates in which list items are inserted and deleted. This causes several difficulties for the data structure.
First, when an item is inserted or deleted at a node of the catalog graph, it must be placed within the augmented list associated with that node, and may cause changes to propagate to other nodes of the catalog graph. Instead of storing the augmented lists in arrays, they should be stored as binary search trees, so that these changes can be handled efficiently while still allowing binary searches of the augmented lists.
Second, an insertion or deletion may cause a change to the subset of the list associated with a node that is passed on to neighboring nodes of the catalog graph. It is no longer feasible, in the dynamic setting, for this subset to be chosen as the items at every dth position of the list, for some d, as this subset would change too drastically after every update. Rather, a technique closely related to B-trees allows the selection of a fraction of data that is guaranteed to be smaller than 1/d, with the selected items guaranteed to be spaced a constant number of positions apart in the full list, and such that an insertion or deletion into the augmented list associated with a node causes changes to propagate to other nodes for a fraction of the operations that is less than 1/d. In this way, the distribution of the data among the nodes satisfies the properties needed for the query algorithm to be fast, while guaranteeing that the average number of binary search tree operations per data insertion or deletion is constant.
Third, and most critically, the static fractional cascading data structure maintains, for each element x of the augmented list at each node of the catalog graph, the index of the result that would be obtained when searching for x among the input items from that node and among the augmented lists stored at neighboring nodes. However, this information would be too expensive to maintain in the dynamic setting. Inserting or deleting a single value x could cause the indexes stored at an unbounded number of other values to change. Instead, dynamic versions of fractional cascading maintain several data structures for each node:
A mapping of the items in the augmented list of the node to small integers, such that the ordering of the positions in the augmented list is equivalent to the comparison ordering of the integers, and a reverse map from these integers back to the list items. A technique of Dietz (1982) allows this numbering to be maintained efficiently.
An integer searching data structure such as a van Emde Boas tree for the numbers associated with the input list of the node. With this structure, and the mapping from items to integers, one can efficiently find for each element x of the augmented list, the item that would be found on searching for x in the input list.
For each neighboring node in the catalog graph, a similar integer searching data structure for the numbers associated with the subset of the data propagated from the neighboring node. With this structure, and the mapping from items to integers, one can efficiently find for each element x of the augmented list, a position within a constant number of steps of the location of x in the augmented list associated with the neighboring node.
These data structures allow dynamic fractional cascading to be performed at a time of O(logn) per insertion or deletion, and a sequence of k binary searches following a path of length k in the catalog graph to be performed in time O(logn+kloglogn).
Applications
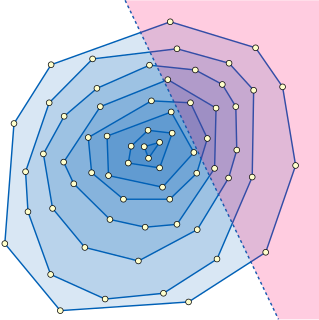
The convex layers of a point set, part of an efficient fractionally cascaded data structure for half-plane range reporting.
Typical applications of fractional cascading involve range search data structures in computational geometry. For example, consider the problem of half-plane range reporting: that is, intersecting a fixed set of n points with a query half-plane and listing all the points in the intersection. The problem is to structure the points in such a way that a query of this type may be answered efficiently in terms of the intersection size h. One structure that can be used for this purpose is the convex layers of the input point set, a family of nested convex polygons consisting of the convex hull of the point set and the recursively-constructed convex layers of the remaining points. Within a single layer, the points inside the query half-plane may be found by performing a binary search for the half-plane boundary line's slope among the sorted sequence of convex polygon edge slopes, leading to the polygon vertex that is inside the query half-plane and farthest from its boundary, and then sequentially searching along the polygon edges to find all other vertices inside the query half-plane. The whole half-plane range reporting problem may be solved by repeating this search procedure starting from the outermost layer and continuing inwards until reaching a layer that is disjoint from the query halfspace. Fractional cascading speeds up the successive binary searches among the sequences of polygon edge slopes in each layer, leading to a data structure for this problem with space O(n) and query time O(logn+h). The data structure may be constructed in time O(nlogn) by an algorithm of Chazelle (1985). As in our example, this application involves binary searches in a linear sequence of lists (the nested sequence of the convex layers), so the catalog graph is just a path.
Another application of fractional cascading in geometric data structures concerns point location in a monotone subdivision, that is, a partition of the plane into polygons such that any vertical line intersects any polygon in at most two points. As Edelsbrunner, Guibas & Stolfi (1986) showed, this problem can be solved by finding a sequence of polygonal paths that stretch from left to right across the subdivision, and binary searching for the lowest of these paths that is above the query point. Testing whether the query point is above or below one of the paths can itself be solved as a binary search problem, searching for the x coordinate of the points among the x coordinates of the path vertices to determine which path edge might be above or below the query point. Thus, each point location query can be solved as an outer layer of binary search among the paths, each step of which itself performs a binary search among x coordinates of vertices. Fractional cascading can be used to speed up the time for the inner binary searches, reducing the total time per query to O(logn) using a data structure with space O(n). In this application the catalog graph is a tree representing the possible search sequences of the outer binary search.
In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.
In computer science, a search algorithm is an algorithm which solves a search problem. Search algorithms work to retrieve information stored within some data structure, or calculated in the search space of a problem domain, either with discrete or continuous values.
In computer science, a tree is a widely used abstract data type that simulates a hierarchical tree structure, with a root value and subtrees of children with a parent node, represented as a set of linked nodes.
Dijkstra's algorithm is an algorithm for finding the shortest paths between nodes in a graph, which may represent, for example, road networks. It was conceived by computer scientist Edsger W. Dijkstra in 1956 and published three years later.
In mathematics, particularly graph theory, and computer science, a directed acyclic graph is a directed graph with no directed cycles. That is, it consists of vertices and edges, with each edge directed from one vertex to another, such that following those directions will never form a closed loop. A directed graph is a DAG if and only if it can be topologically ordered, by arranging the vertices as a linear ordering that is consistent with all edge directions. DAGs have numerous scientific and computational applications, ranging from biology to sociology to computation (scheduling).
In computer science, a self-balancingbinary search tree is any node-based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions.
The point location problem is a fundamental topic of computational geometry. It finds applications in areas that deal with processing geometrical data: computer graphics, geographic information systems (GIS), motion planning, and computer aided design (CAD).
In computing, a persistent data structure or not ephemeral data structure is a data structure that always preserves the previous version of itself when it is modified. Such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead always yield a new updated structure. The term was introduced in Driscoll, Sarnak, Sleator, and Tarjans' 1986 article.
In computer science, a topological sort or topological ordering of a directed graph is a linear ordering of its vertices such that for every directed edge uv from vertex u to vertex v, u comes before v in the ordering. For instance, the vertices of the graph may represent tasks to be performed, and the edges may represent constraints that one task must be performed before another; in this application, a topological ordering is just a valid sequence for the tasks. Precisely, a topological sort is a graph traversal in which each node v is visited only after all its dependencies are visited. A topological ordering is possible if and only if the graph has no directed cycles, that is, if it is a directed acyclic graph (DAG). Any DAG has at least one topological ordering, and algorithms are known for constructing a topological ordering of any DAG in linear time. Topological sorting has many applications especially in ranking problems such as feedback arc set. Topological sorting is possible even when the DAG has disconnected components.
In computer science, an interval tree is a tree data structure to hold intervals. Specifically, it allows one to efficiently find all intervals that overlap with any given interval or point. It is often used for windowing queries, for instance, to find all roads on a computerized map inside a rectangular viewport, or to find all visible elements inside a three-dimensional scene. A similar data structure is the segment tree.
In graph theory and computer science, the lowest common ancestor (LCA) of two nodes v and w in a tree or directed acyclic graph (DAG) T is the lowest node that has both v and w as descendants, where we define each node to be a descendant of itself.
In data structures, the range searching problem most generally consists of preprocessing a set S of objects, in order to determine which objects from S intersect with a query object, called a range. For example, if S is a set of points corresponding to the coordinates of several cities, a geometric variant of the problem is to find cities within a certain latitude and longitude range.
In computer science, a succinct data structure is a data structure which uses an amount of space that is "close" to the information-theoretic lower bound, but still allows for efficient query operations. The concept was originally introduced by Jacobson to encode bit vectors, (unlabeled) trees, and planar graphs. Unlike general lossless data compression algorithms, succinct data structures retain the ability to use them in-place, without decompressing them first. A related notion is that of a compressed data structure, in which the size of the data structure depends upon the particular data being represented.
In computer science, a range tree is an ordered tree data structure to hold a list of points. It allows all points within a given range to be reported efficiently, and is typically used in two or higher dimensions. Range trees were introduced by Jon Louis Bentley in 1979. Similar data structures were discovered independently by Lueker, Lee and Wong, and Willard. The range tree is an alternative to the k-d tree. Compared to k-d trees, range trees offer faster query times of but worse storage of , where n is the number of points stored in the tree, d is the dimension of each point and k is the number of points reported by a given query.
In computer science, a Cartesian tree is a binary tree derived from a sequence of numbers; it can be uniquely defined from the properties that it is heap-ordered and that a symmetric (in-order) traversal of the tree returns the original sequence. Introduced by Vuillemin (1980) in the context of geometric range searching data structures, Cartesian trees have also been used in the definition of the treap and randomized binary search tree data structures for binary search problems. The Cartesian tree for a sequence may be constructed in linear time using a stack-based algorithm for finding all nearest smaller values in a sequence.
In computer science and probability theory, a random binary tree is a binary tree selected at random from some probability distribution on binary trees. Two different distributions are commonly used: binary trees formed by inserting nodes one at a time according to a random permutation, and binary trees chosen from a uniform discrete distribution in which all distinct trees are equally likely. It is also possible to form other distributions, for instance by repeated splitting. Adding and removing nodes directly in a random binary tree will in general disrupt its random structure, but the treap and related randomized binary search tree data structures use the principle of binary trees formed from a random permutation in order to maintain a balanced binary search tree dynamically as nodes are inserted and deleted.
In computer science, finger search trees are a type of binary search tree that keeps pointers to interior nodes, called fingers. The fingers speed up searches, insertions, and deletions for elements close to the fingers, giving amortized O(log n) lookups, and amortized O(1) insertions and deletions. It should not be confused with a finger tree nor a splay tree, although both can be used to implement finger search trees.
In computer science, a finger search on a data structure is an extension of any search operation that structure supports, where a reference (finger) to an element in the data structure is given along with the query. While the search time for an element is most frequently expressed as a function of the number of elements in a data structure, finger search times are a function of the distance between the element and the finger.
In computational geometry, the convex layers of a set of points in the Euclidean plane are a sequence of nested convex polygons having the points as their vertices. The outermost one is the convex hull of the points and the rest are formed in the same way recursively. The innermost layer may be degenerate, consisting only of one or two points. The problem of constructing convex layers has also been called onion peeling or onion decomposition.
Buddhikot, Milind M.; Suri, Subhash; Waldvogel, Marcel (1999), "Space Decomposition Techniques for Fast Layer-4 Switching"(PDF), Proceedings of the IFIP TC6 WG6.1 & WG6.4 / IEEE ComSoc TC on Gigabit Networking Sixth International Workshop on Protocols for High Speed Networks VI, pp.25–42, archived from the original(PDF) on 2004-10-20.
Lakshman, T. V.; Stiliadis, D. (1998), "High-speed policy-based packet forwarding using efficient multi-dimensional range matching", Proceedings of the ACM SIGCOMM '98 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, pp.203–214, CiteSeerX10.1.1.39.697, doi:10.1145/285237.285283, ISBN978-1-58113-003-4, S2CID15363397 .
Lueker, George S. (1978), "A data structure for orthogonal range queries", Proc. 19th Symp. Foundations of Computer Science, IEEE, pp.28–34, doi:10.1109/SFCS.1978.1, S2CID14970942 .
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.