Related Research Articles
ISO 639 is a standard by the International Organization for Standardization (ISO) concerned with representation of languages and language groups. It currently consists of four sets of code, named after each part which formerly described respective set ; a part 6 was published but withdrawn. It was first approved in 1967 as a single-part ISO Recommendation, ISO/R 639, superseded in 2002 by part 1 of the new series, ISO 639-1, followed by additional parts. All existing parts of the series were consolidated into a single standard in 2023, largely based on the text of ISO 639-4.
This is a partial index of Wikipedia articles treating natural languages, arranged alphabetically and with (sub-) families mentioned. The list also includes extinct languages.

Southern Min, Minnan or Banlam, is a group of linguistically similar and historically related Chinese languages that form a branch of Min Chinese spoken in Fujian, most of Taiwan, Eastern Guangdong, Hainan, and Southern Zhejiang. Southern Min dialects are also spoken by descendants of emigrants from these areas in diaspora, most notably in Southeast Asia, such as Singapore, Malaysia, the Philippines, Indonesia, Brunei, Southern Thailand, Myanmar, Cambodia, Southern and Central Vietnam, San Francisco, Los Angeles and New York City. Minnan is the most widely-spoken branch of Min, with approximately 48 million speakers as of 2017–2018.
ISO 639-1:2002, Codes for the representation of names of languages—Part 1: Alpha-2 code, is the first part of the ISO 639 series of international standards for language codes. Part 1 covers the registration of two-letter codes. There are 183 two-letter codes registered as of June 2021. The registered codes cover the world's major languages.
In computing, a locale is a set of parameters that defines the user's language, region and any special variant preferences that the user wants to see in their user interface. Usually a locale identifier consists of at least a language code and a country/region code. Locale is an important aspect of i18n.

The South Slavic languages are one of three branches of the Slavic languages. There are approximately 30 million speakers, mainly in the Balkans. These are separated geographically from speakers of the other two Slavic branches by a belt of German, Hungarian and Romanian speakers.
The Linguasphere Observatory is a non-profit transnational research network, devoted to the gathering, study, classification, editing and free distribution online of the updatable text of a fully indexed and comprehensive Linguasphere Register of the World's Languages and Speech Communities.
ISO 639-3:2007, Codes for the representation of names of languages – Part 3: Alpha-3 code for comprehensive coverage of languages, is an international standard for language codes in the ISO 639 series. It defines three-letter codes for identifying languages. The standard was published by International Organization for Standardization (ISO) on 1 February 2007.
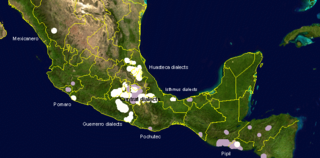
The Nahuan or Aztecan languages are those languages of the Uto-Aztecan language family that have undergone a sound change, known as Whorf's law, that changed an original *t to before *a. Subsequently, some Nahuan languages have changed this to or back to, but it can still be seen that the language went through a stage. The best known Nahuan language is Nahuatl. Nahuatl is spoken by about 1.7 million Nahua peoples.
ISO 639-6, Codes for the representation of names of languages — Part 6: Alpha-4 code for comprehensive coverage of language variants, was a proposed international standard in the ISO 639 series, developed by ISO/TC 37/SC 2. It contained four-letter codes that denote variants of languages and language families. This allowed one to differentiate between, for example, historical (glvx) versus revived (rvmx) Manx, while ISO 639-3 only includes glv for Manx.
Language localisation is the process of adapting a product's translation to a specific country or region. It is the second phase of a larger process of product translation and cultural adaptation to account for differences in distinct markets, a process known as internationalisation and localisation.
An IETF BCP 47 language tag is a standardized code or tag that is used to identify human languages in the Internet. The tag structure has been standardized by the Internet Engineering Task Force (IETF) in Best Current Practice (BCP) 47; the subtags are maintained by the IANA Language Subtag Registry.
This page is a list of lists of languages.
The Ojibwe language is spoken in a series of dialects occupying adjacent territories, forming a language complex in which mutual intelligibility between adjacent dialects may be comparatively high but declines between some non-adjacent dialects. Mutual intelligibility between some non-adjacent dialects, notably Ottawa, Severn Ojibwe, and Algonquin, is low enough that they could be considered distinct languages. There is no single dialect that is considered the most prestigious or most prominent, and no standard writing system that covers all dialects. The relative autonomy of the regional dialects of Ojibwe is associated with an absence of linguistic or political unity among Ojibwe-speaking groups.
This is a list of ISO 639 codes and IETF language tags for individual constructed languages, complete as of January 2023.

Emilian is a Gallo-Italic unstandardised language spoken in the historical region of Emilia, which is now in the northwestern part of Emilia-Romagna, Northern Italy.

Varieties of Arabic are the linguistic systems that Arabic speakers speak natively. Arabic is a Semitic language within the Afroasiatic family that originated in the Arabian Peninsula. There are considerable variations from region to region, with degrees of mutual intelligibility that are often related to geographical distance and some that are mutually unintelligible. Many aspects of the variability attested to in these modern variants can be found in the ancient Arabic dialects in the peninsula. Likewise, many of the features that characterize the various modern variants can be attributed to the original settler dialects as well as local native languages and dialects. Some organizations, such as SIL International, consider these approximately 30 different varieties to be separate languages, while others, such as the Library of Congress, consider them all to be dialects of Arabic.

Spanish is the most-widely spoken language in Ecuador, though great variations are present depending on several factors, the most important one being the geographical region where it is spoken. The three main regional variants are:
Spurious languages are languages that have been reported as existing in reputable works, while other research has reported that the language in question did not exist. Some spurious languages have been proven to not exist. Others have very little evidence supporting their existence, and have been dismissed in later scholarship. Others still are of uncertain existence due to limited research.
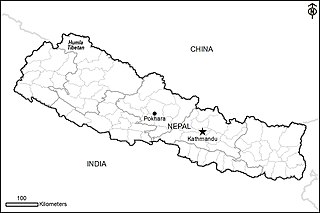
Humla Tibetan, also known as Humla Bhotiya, and Humli Tamang, is the Sino-Tibetan language of the Tibetan people of Humla district in Nepal.
References
- ↑ "Information on BCP 47 » RFC Editor".
- ↑ Best Current Practice 47 – Tags for Identifying Languages, IETF
- ↑ "The Linguasphere Register in PDF". l’Observatoire linguistique (Linguasphere Observatory). Archived from the original on 27 April 2015. Retrieved 20 April 2015.
- ↑ "Linguasphere Register hierarchy" . Retrieved 8 June 2016.
- ↑ Verbix language codes Archived 2009-04-01 at the Wayback Machine , Verbix