
In digital computers, an interrupt is a request for the processor to interrupt currently executing code, so that the event can be processed in a timely manner. If the request is accepted, the processor will suspend its current activities, save its state, and execute a function called an interrupt handler to deal with the event. This interruption is often temporary, allowing the software to resume normal activities after the interrupt handler finishes, although the interrupt could instead indicate a fatal error.
An operating system (OS) is system software that manages computer hardware and software resources, and provides common services for computer programs.
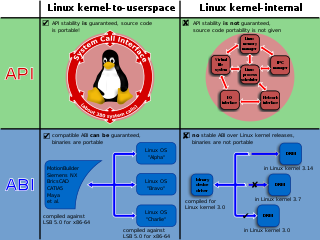
In computing, a system call is the programmatic way in which a computer program requests a service from the operating system on which it is executed. This may include hardware-related services, creation and execution of new processes, and communication with integral kernel services such as process scheduling. System calls provide an essential interface between a process and the operating system.
In computer architecture, 64-bit integers, memory addresses, or other data units are those that are 64 bits wide. Also, 64-bit central processing units (CPU) and arithmetic logic units (ALU) are those that are based on processor registers, address buses, or data buses of that size. A computer that uses such a processor is a 64-bit computer.

x86-64 is a 64-bit version of the x86 instruction set, first released in 1999. It introduced two new modes of operation, 64-bit mode and compatibility mode, along with a new 4-level paging mode.

In computing, a crash, or system crash, occurs when a computer program such as a software application or an operating system stops functioning properly and exits. On some operating systems or individual applications, a crash reporting service will report the crash and any details relating to it, usually to the developer(s) of the application. If the program is a critical part of the operating system, the entire system may crash or hang, often resulting in a kernel panic or fatal system error.

A general protection fault (GPF) in the x86 instruction set architectures (ISAs) is a fault initiated by ISA-defined protection mechanisms in response to an access violation caused by some running code, either in the kernel or a user program. The mechanism is first described in Intel manuals and datasheets for the Intel 80286 CPU, which was introduced in 1983; it is also described in section 9.8.13 in the Intel 80386 programmer's reference manual from 1986. A general protection fault is implemented as an interrupt. Some operating systems may also classify some exceptions not related to access violations, such as illegal opcode exceptions, as general protection faults, even though they have nothing to do with memory protection. If a CPU detects a protection violation, it stops executing the code and sends a GPF interrupt. In most cases, the operating system removes the failing process from the execution queue, signals the user, and continues executing other processes. If, however, the operating system fails to catch the general protection fault, i.e. another protection violation occurs before the operating system returns from the previous GPF interrupt, the CPU signals a double fault, stopping the operating system. If yet another failure occurs, the CPU is unable to recover; since 80286, the CPU enters a special halt state called "Shutdown", which can only be exited through a hardware reset. The IBM PC AT, the first PC-compatible system to contain an 80286, has hardware that detects the Shutdown state and automatically resets the CPU when it occurs. All descendants of the PC AT do the same, so in a PC, a triple fault causes an immediate system reset.
The High Precision Event Timer (HPET) is a hardware timer available in modern x86-compatible personal computers. Compared to older types of timers available in the x86 architecture, HPET allows more efficient processing of highly timing-sensitive applications, such as multimedia playback and OS task switching. It was developed jointly by Intel and Microsoft and has been incorporated in PC chipsets since 2005. Formerly referred to by Intel as a Multimedia Timer, the term HPET was selected to avoid confusion with the software multimedia timers introduced in the MultiMedia Extensions to Windows 3.0.
System Management Mode is an operating mode of x86 central processor units (CPUs) in which all normal execution, including the operating system, is suspended. An alternate software system which usually resides in the computer's firmware, or a hardware-assisted debugger, is then executed with high privileges.
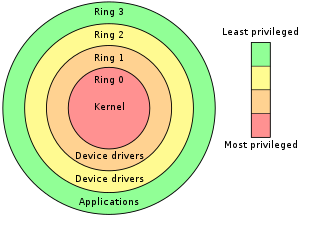
In computer science, hierarchical protection domains, often called protection rings, are mechanisms to protect data and functionality from faults and malicious behavior.
In computer security, executable-space protection marks memory regions as non-executable, such that an attempt to execute machine code in these regions will cause an exception. It makes use of hardware features such as the NX bit, or in some cases software emulation of those features. However, technologies that emulate or supply an NX bit will usually impose a measurable overhead while using a hardware-supplied NX bit imposes no measurable overhead.
ntoskrnl.exe, also known as the kernel image, contains the kernel and executive layers of the Microsoft Windows NT kernel, and is responsible for hardware abstraction, process handling, and memory management. In addition to the kernel and executive mentioned earlier, it contains the cache manager, security reference monitor, memory manager, scheduler (Dispatcher), and blue screen of death.

Error correction code memory is a type of computer data storage that uses an error correction code (ECC) to detect and correct n-bit data corruption which occurs in memory. ECC memory is used in most computers where data corruption cannot be tolerated, like industrial control applications, critical databases, and infrastructural memory caches.
The following is a timeline of virtualization development. In computing, virtualization is the use of a computer to simulate another computer. Through virtualization, a host simulates a guest by exposing virtual hardware devices, which may be done through software or by allowing access to a physical device connected to the machine.

VMware ESXi is an enterprise-class, type-1 hypervisor developed by VMware for deploying and serving virtual computers. As a type-1 hypervisor, ESXi is not a software application that is installed on an operating system (OS); instead, it includes and integrates vital OS components, such as a kernel.
In computing, Machine Check Architecture (MCA) is an Intel and AMD mechanism in which the CPU reports hardware errors to the operating system.
In computing, the term 3 GB barrier refers to a limitation of some 32-bit operating systems running on x86 microprocessors. It prevents the operating systems from using all of 4 GiB (4 × 10243 bytes) of main memory. The exact barrier varies by motherboard and I/O device configuration, particularly the size of video RAM; it may be in the range of 2.75 GB to 3.5 GB. The barrier is not present with a 64-bit processor and 64-bit operating system, or with certain x86 hardware and an operating system such as Linux or certain versions of Windows Server and macOS that allow use of Physical Address Extension (PAE) mode on x86 to access more than 4 GiB of RAM.

GPU switching is a mechanism used on computers with multiple graphic controllers. This mechanism allows the user to either maximize the graphic performance or prolong battery life by switching between the graphic cards. It is mostly used on gaming laptops which usually have an integrated graphic device and a discrete video card.
Windows Hardware Error Architecture (WHEA) is an operating system hardware error handling mechanism introduced with Windows Vista SP1 and Windows Server 2008 as a successor to Machine Check Architecture (MCA) on previous versions of Windows. The architecture consists of several software components that interact with the hardware and firmware of a given platform to handle and notify regarding hardware error conditions. Collectively, these components provide: a generic means of discovering errors, a common error report format for those errors, a way of preserving error records, and an error event model based up on Event Tracing for Windows (ETW).

Meltdown is one of the two original transient execution CPU vulnerabilities. Meltdown affects Intel x86 microprocessors, IBM POWER processors, and some ARM-based microprocessors. It allows a rogue process to read all memory, even when it is not authorized to do so.