
Non-uniform memory access (NUMA) is a computer memory design used in multiprocessing, where the memory access time depends on the memory location relative to the processor. Under NUMA, a processor can access its own local memory faster than non-local memory. The benefits of NUMA are limited to particular workloads, notably on servers where the data is often associated strongly with certain tasks or users.

Symmetric multiprocessing or shared-memory multiprocessing (SMP) involves a multiprocessor computer hardware and software architecture where two or more identical processors are connected to a single, shared main memory, have full access to all input and output devices, and are controlled by a single operating system instance that treats all processors equally, reserving none for special purposes. Most multiprocessor systems today use an SMP architecture. In the case of multi-core processors, the SMP architecture applies to the cores, treating them as separate processors.
Multiprocessing is the use of two or more central processing units (CPUs) within a single computer system. The term also refers to the ability of a system to support more than one processor or the ability to allocate tasks between them. There are many variations on this basic theme, and the definition of multiprocessing can vary with context, mostly as a function of how CPUs are defined.

The Scalable Coherent Interface or Scalable Coherent Interconnect (SCI), is a high-speed interconnect standard for shared memory multiprocessing and message passing. The goal was to scale well, provide system-wide memory coherence and a simple interface; i.e. a standard to replace existing buses in multiprocessor systems with one with no inherent scalability and performance limitations.
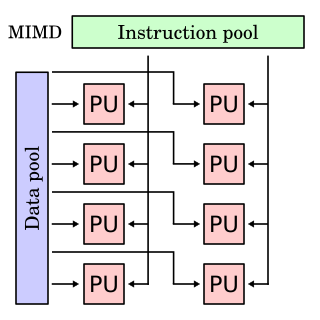
In computing, multiple instruction, multiple data (MIMD) is a technique employed to achieve parallelism. Machines using MIMD have a number of processors that function asynchronously and independently. At any time, different processors may be executing different instructions on different pieces of data.

In computer architecture, cache coherence is the uniformity of shared resource data that ends up stored in multiple local caches. When clients in a system maintain caches of a common memory resource, problems may arise with incoherent data, which is particularly the case with CPUs in a multiprocessing system.
Sequent Computer Systems was a computer company that designed and manufactured multiprocessing computer systems. They were among the pioneers in high-performance symmetric multiprocessing (SMP) open systems, innovating in both hardware and software.
Cache only memory architecture (COMA) is a computer memory organization for use in multiprocessors in which the local memories at each node are used as cache. This is in contrast to using the local memories as actual main memory, as in NUMA organizations.
K42 is a discontinued open-source research operating system (OS) for cache-coherent 64-bit multiprocessor systems. It was developed primarily at IBM Thomas J. Watson Research Center in collaboration with the University of Toronto and University of New Mexico. The main focus of this OS is to address performance and scalability issues of system software on large-scale, shared memory, non-uniform memory access (NUMA) multiprocessing computers.

Binary Modular Dataflow Machine (BMDFM) is a software package that enables running an application in parallel on shared memory symmetric multiprocessing (SMP) computers using the multiple processors to speed up the execution of single applications. BMDFM automatically identifies and exploits parallelism due to the static and mainly dynamic scheduling of the dataflow instruction sequences derived from the formerly sequential program.

A multi-core processor is a microprocessor on a single integrated circuit with two or more separate processing units, called cores, each of which reads and executes program instructions. The instructions are ordinary CPU instructions but the single processor can run instructions on separate cores at the same time, increasing overall speed for programs that support multithreading or other parallel computing techniques. Manufacturers typically integrate the cores onto a single integrated circuit die or onto multiple dies in a single chip package. The microprocessors currently used in almost all personal computers are multi-core.
Uniform memory access (UMA) is a shared memory architecture used in parallel computers. All the processors in the UMA model share the physical memory uniformly. In an UMA architecture, access time to a memory location is independent of which processor makes the request or which memory chip contains the transferred data. Uniform memory access computer architectures are often contrasted with non-uniform memory access (NUMA) architectures. In the NUMA architecture, each processor may use a private cache. Peripherals are also shared in some fashion. The UMA model is suitable for general purpose and time sharing applications by multiple users. It can be used to speed up the execution of a single large program in time-critical applications.
Scratchpad memory (SPM), also known as scratchpad, scratchpad RAM or local store in computer terminology, is an internal memory, usually high-speed, used for temporary storage of calculations, data, and other work in progress. In reference to a microprocessor, scratchpad refers to a special high-speed memory used to hold small items of data for rapid retrieval. It is similar to the usage and size of a scratchpad in life: a pad of paper for preliminary notes or sketches or writings, etc. When the scratchpad is a hidden portion of the main memory then it is sometimes referred to as bump storage.
The PowerPC 600 family was the first family of PowerPC processors built. They were designed at the Somerset facility in Austin, Texas, jointly funded and staffed by engineers from IBM and Motorola as a part of the AIM alliance. Somerset was opened in 1992 and its goal was to make the first PowerPC processor and then keep designing general purpose PowerPC processors for personal computers. The first incarnation became the PowerPC 601 in 1993, and the second generation soon followed with the PowerPC 603, PowerPC 604 and the 64-bit PowerPC 620.

The SGI Origin 2000 is a family of mid-range and high-end server computers developed and manufactured by Silicon Graphics (SGI). They were introduced in 1996 to succeed the SGI Challenge and POWER Challenge. At the time of introduction, these ran the IRIX operating system, originally version 6.4 and later, 6.5. A variant of the Origin 2000 with graphics capability is known as the Onyx2. An entry-level variant based on the same architecture but with a different hardware implementation is known as the Origin 200. The Origin 2000 was succeeded by the Origin 3000 in July 2000, and was discontinued on June 30, 2002.

The UltraSPARC III, code-named "Cheetah", is a microprocessor that implements the SPARC V9 instruction set architecture (ISA) developed by Sun Microsystems and fabricated by Texas Instruments. It was introduced in 2001 and operates at 600 to 900 MHz. It was succeeded by the UltraSPARC IV in 2004. Gary Lauterbach was the chief architect.
Heterogeneous computing refers to systems that use more than one kind of processor or core. These systems gain performance or energy efficiency not just by adding the same type of processors, but by adding dissimilar coprocessors, usually incorporating specialized processing capabilities to handle particular tasks.

In computer science, shared memory is memory that may be simultaneously accessed by multiple programs with an intent to provide communication among them or avoid redundant copies. Shared memory is an efficient means of passing data between programs. Depending on context, programs may run on a single processor or on multiple separate processors.
Directory-based coherence is a mechanism to handle cache coherence problem in distributed shared memory (DSM) a.k.a. non-uniform memory access (NUMA). Another popular way is to use a special type of computer bus between all the nodes as a "shared bus". Directory-based coherence uses a special directory to serve instead of the shared bus in the bus-based coherence protocols. Both of these designs use the corresponding medium as a tool to facilitate the communication between different nodes, and to guarantee that the coherence protocol is working properly along all the communicating nodes. In directory based cache coherence, this is done by using this directory to keep track of the status of all cache blocks, the status of each block includes in which cache coherence "state" that block is, and which nodes are sharing that block at that time, which can be used to eliminate the need to broadcast all the signals to all nodes, and only send it to the nodes that are interested in this single block.
Examples of coherency protocols for cache memory are listed here. For simplicity, all "miss" Read and Write status transactions which obviously come from state "I", in the diagrams are not shown. They are shown directly on the new state. Many of the following protocols have only historical value. At the moment the main protocols used are the R-MESI type / MESIF protocols and the HRT-ST-MESI or a subset or an extension of these.








