In computer science, an instruction set architecture (ISA) is a part of the abstract model of a computer, which generally defines how software controls the CPU. A device that executes instructions described by that ISA, such as a central processing unit (CPU), is called an implementation.
IA-64 is the instruction set architecture (ISA) of the discontinued Itanium family of 64-bit Intel microprocessors. The basic ISA specification originated at Hewlett-Packard (HP), and was subsequently implemented by Intel in collaboration with HP. The first Itanium processor, codenamed Merced, was released in 2001.
Speculative execution is an optimization technique where a computer system performs some task that may not be needed. Work is done before it is known whether it is actually needed, so as to prevent a delay that would have to be incurred by doing the work after it is known that it is needed. If it turns out the work was not needed after all, most changes made by the work are reverted and the results are ignored.
In computer architecture, a branch predictor is a digital circuit that tries to guess which way a branch will go before this is known definitively. The purpose of the branch predictor is to improve the flow in the instruction pipeline. Branch predictors play a critical role in achieving high performance in many modern pipelined microprocessor architectures.
A CPU cache is a hardware cache used by the central processing unit (CPU) of a computer to reduce the average cost to access data from the main memory. A cache is a smaller, faster memory, located closer to a processor core, which stores copies of the data from frequently used main memory locations. Most CPUs have a hierarchy of multiple cache levels, with different instruction-specific and data-specific caches at level 1. The cache memory is typically implemented with static random-access memory (SRAM), in modern CPUs by far the largest part of them by chip area, but SRAM is not always used for all levels, or even any level, sometimes some latter or all levels are implemented with eDRAM.
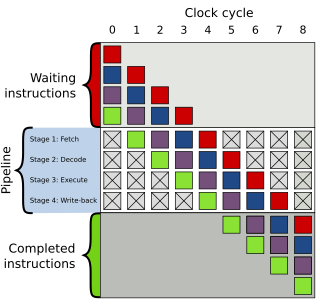
In computer engineering, out-of-order execution is a paradigm used in high-performance central processing units to make use of instruction cycles that would otherwise be wasted. In this paradigm, a processor executes instructions in an order governed by the availability of input data and execution units, rather than by their original order in a program. In doing so, the processor can avoid being idle while waiting for the preceding instruction to complete and can, in the meantime, process the next instructions that are able to run immediately and independently.

The AMD Am29000, commonly shortened to 29k, is a family of 32-bit RISC microprocessors and microcontrollers developed and fabricated by Advanced Micro Devices (AMD). Based on the seminal Berkeley RISC, the 29k added a number of significant improvements. They were, for a time, the most popular RISC chips on the market, widely used in laser printers from a variety of manufacturers.

In electronics, computer science and computer engineering, microarchitecture, also called computer organization and sometimes abbreviated as µarch or uarch, is the way a given instruction set architecture (ISA) is implemented in a particular processor. A given ISA may be implemented with different microarchitectures; implementations may vary due to different goals of a given design or due to shifts in technology.

In computer central processing units, micro-operations are detailed low-level instructions used in some designs to implement complex machine instructions.
In computer architecture, memory-level parallelism (MLP) is the ability to have pending multiple memory operations, in particular cache misses or translation lookaside buffer (TLB) misses, at the same time.
Hardware scout is a technique that uses otherwise idle processor execution resources to perform prefetching during cache misses. When a thread is stalled by a cache miss, the processor pipeline checkpoints the register file, switches to runahead mode, and continues to issue instructions from the thread that is waiting for memory. The thread of execution in run-ahead mode is known as a scout thread. When the data returns from memory, the processor restores the register file contents from the checkpoint, and switches back to normal execution mode.
The SPARC64 V (Zeus) is a SPARC V9 microprocessor designed by Fujitsu. The SPARC64 V was the basis for a series of successive processors designed for servers, and later, supercomputers.
An instruction window in computer architecture refers to the set of instructions which can execute out-of-order in a speculative processor.

The IEEE/ACM International Symposium on Microarchitecture® (MICRO) is an annual academic conference on microarchitecture, generally viewed as the top-tier academic conference on computer architecture. It is not to be confused with a micro-conference. Particularly within the domains of microarchitecture and Code generation (compiler), MICRO is unrivaled and esteemed as the premier forum. Association for Computing Machinery's Special Interest Group on Microarchitecture and Institute of Electrical and Electronics Engineers Computer Society are technical sponsors.

Fermi is the codename for a graphics processing unit (GPU) microarchitecture developed by Nvidia, first released to retail in April 2010, as the successor to the Tesla microarchitecture. It was the primary microarchitecture used in the GeForce 400 series and GeForce 500 series. It was followed by Kepler, and used alongside Kepler in the GeForce 600 series, GeForce 700 series, and GeForce 800 series, in the latter two only in mobile GPUs. In the workstation market, Fermi found use in the Quadro x000 series, Quadro NVS models, as well as in Nvidia Tesla computing modules. All desktop Fermi GPUs were manufactured in 40nm, mobile Fermi GPUs in 40nm and 28nm. Fermi is the oldest microarchitecture from NVIDIA that received support for Microsoft's rendering API Direct3D 12 feature_level 11.
Cache prefetching is a technique used by computer processors to boost execution performance by fetching instructions or data from their original storage in slower memory to a faster local memory before it is actually needed. Most modern computer processors have fast and local cache memory in which prefetched data is held until it is required. The source for the prefetch operation is usually main memory. Because of their design, accessing cache memories is typically much faster than accessing main memory, so prefetching data and then accessing it from caches is usually many orders of magnitude faster than accessing it directly from main memory. Prefetching can be done with non-blocking cache control instructions.

In computer architecture, a trace cache or execution trace cache is a specialized instruction cache which stores the dynamic stream of instructions known as trace. It helps in increasing the instruction fetch bandwidth and decreasing power consumption by storing traces of instructions that have already been fetched and decoded. A trace processor is an architecture designed around the trace cache and processes the instructions at trace level granularity. The formal mathematical theory of traces is described by trace monoids.
Intel microcode is microcode that runs inside x86 processors made by Intel. Since the P6 microarchitecture introduced in the mid-1990s, the microcode programs can be patched by the operating system or BIOS firmware to work around bugs found in the CPU after release. Intel had originally designed microcode updates for processor debugging under its design for testing (DFT) initiative.
The ARM Cortex-A77 is a central processing unit implementing the ARMv8.2-A 64-bit instruction set designed by ARM Holdings' Austin design centre. ARM announced an increase of 23% and 35% in integer and floating point performance, respectively. Memory bandwidth increased 15% relative to the A76.
Trevor Mudge is a computer scientist, academic and researcher. He is the Bredt Family Chair of Computer Science and Engineering, and Professor of Electrical Engineering and Computer Science at the University of Michigan.