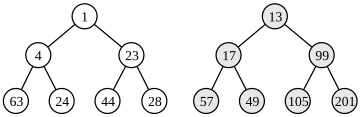
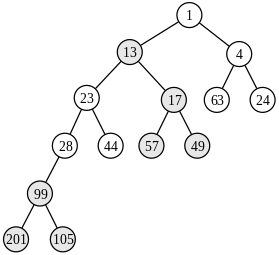
In computer science, an AVL tree is a self-balancing binary search tree. In an AVL tree, the heights of the two child subtrees of any node differ by at most one; if at any time they differ by more than one, rebalancing is done to restore this property. Lookup, insertion, and deletion all take O(log n) time in both the average and worst cases, where is the number of nodes in the tree prior to the operation. Insertions and deletions may require the tree to be rebalanced by one or more tree rotations.

In computer science, a binary tree is a tree data structure in which each node has at most two children, referred to as the left child and the right child. That is, it is a k-ary tree with k = 2. A recursive definition using set theory is that a binary tree is a tuple (L, S, R), where L and R are binary trees or the empty set and S is a singleton set containing the root.
In computer science, a red–black tree is a specialised binary search tree data structure noted for fast storage and retrieval of ordered information, and a guarantee that operations will complete within a known time. Compared to other self-balancing binary search trees, the nodes in a red-black tree hold an extra bit called "color" representing "red" and "black" which is used when re-organising the tree to ensure that it is always approximately balanced.

A binary heap is a heap data structure that takes the form of a binary tree. Binary heaps are a common way of implementing priority queues. The binary heap was introduced by J. W. J. Williams in 1964, as a data structure for heapsort.

In computer science, the treap and the randomized binary search tree are two closely related forms of binary search tree data structures that maintain a dynamic set of ordered keys and allow binary searches among the keys. After any sequence of insertions and deletions of keys, the shape of the tree is a random variable with the same probability distribution as a random binary tree; in particular, with high probability its height is proportional to the logarithm of the number of keys, so that each search, insertion, or deletion operation takes logarithmic time to perform.
In computer science, a binomial heap is a data structure that acts as a priority queue. It is an example of a mergeable heap, as it supports merging two heaps in logarithmic time. It is implemented as a heap similar to a binary heap but using a special tree structure that is different from the complete binary trees used by binary heaps. Binomial heaps were invented in 1978 by Jean Vuillemin.
In computer science, tree traversal is a form of graph traversal and refers to the process of visiting each node in a tree data structure, exactly once. Such traversals are classified by the order in which the nodes are visited. The following algorithms are described for a binary tree, but they may be generalized to other trees as well.
In computer science, a search tree is a tree data structure used for locating specific keys from within a set. In order for a tree to function as a search tree, the key for each node must be greater than any keys in subtrees on the left, and less than any keys in subtrees on the right.
An AA tree in computer science is a form of balanced tree used for storing and retrieving ordered data efficiently. AA trees are named after their originator, Swedish computer scientist Arne Andersson.
In computer science, a leftist tree or leftist heap is a priority queue implemented with a variant of a binary heap. Every node x has an s-value which is the distance to the nearest leaf in subtree rooted at x. In contrast to a binary heap, a leftist tree attempts to be very unbalanced. In addition to the heap property, leftist trees are maintained so the right descendant of each node has the lower s-value.
A pairing heap is a type of heap data structure with relatively simple implementation and excellent practical amortized performance, introduced by Michael Fredman, Robert Sedgewick, Daniel Sleator, and Robert Tarjan in 1986. Pairing heaps are heap-ordered multiway tree structures, and can be considered simplified Fibonacci heaps. They are considered a "robust choice" for implementing such algorithms as Prim's MST algorithm, and support the following operations :
In computer science, weight-balanced binary trees (WBTs) are a type of self-balancing binary search trees that can be used to implement dynamic sets, dictionaries (maps) and sequences. These trees were introduced by Nievergelt and Reingold in the 1970s as trees of bounded balance, or BB[α] trees. Their more common name is due to Knuth.
In computer science, a range tree is an ordered tree data structure to hold a list of points. It allows all points within a given range to be reported efficiently, and is typically used in two or higher dimensions. Range trees were introduced by Jon Louis Bentley in 1979. Similar data structures were discovered independently by Lueker, Lee and Wong, and Willard. The range tree is an alternative to the k-d tree. Compared to k-d trees, range trees offer faster query times of but worse storage of , where n is the number of points stored in the tree, d is the dimension of each point and k is the number of points reported by a given query.

In computer science, a Cartesian tree is a binary tree derived from a sequence of distinct numbers. To construct the Cartesian tree, set its root to be the minimum number in the sequence, and recursively construct its left and right subtrees from the subsequences before and after this number. It is uniquely defined as a min-heap whose symmetric (in-order) traversal returns the original sequence.
In computer science, a min-max heap is a complete binary tree data structure which combines the usefulness of both a min-heap and a max-heap, that is, it provides constant time retrieval and logarithmic time removal of both the minimum and maximum elements in it. This makes the min-max heap a very useful data structure to implement a double-ended priority queue. Like binary min-heaps and max-heaps, min-max heaps support logarithmic insertion and deletion and can be built in linear time. Min-max heaps are often represented implicitly in an array; hence it's referred to as an implicit data structure.
In computer science, a skew binomial heap is a data structure for priority queue operations. It is a variant of the binomial heap that supports constant-time insertion operations in the worst case, rather than amortized time.
In computer science, a randomized meldable heap is a priority queue based data structure in which the underlying structure is also a heap-ordered binary tree. However, there are no restrictions on the shape of the underlying binary tree.
In the mathematical field of graph theory, an agreement forest for two given trees is any forest which can, informally speaking, be obtained from both trees by removing a common number of edges.
In computer science, a weak heap is a data structure for priority queues, combining features of the binary heap and binomial heap. It can be stored in an array as an implicit binary tree like a binary heap, and has the efficiency guarantees of binomial heaps.
In computer science, join-based tree algorithms are a class of algorithms for self-balancing binary search trees. This framework aims at designing highly-parallelized algorithms for various balanced binary search trees. The algorithmic framework is based on a single operation join. Under this framework, the join operation captures all balancing criteria of different balancing schemes, and all other functions join have generic implementation across different balancing schemes. The join-based algorithms can be applied to at least four balancing schemes: AVL trees, red–black trees, weight-balanced trees and treaps.