Related Research Articles
In computer science, an abstract data type (ADT) is a mathematical model for data types, defined by its behavior (semantics) from the point of view of a user of the data, specifically in terms of possible values, possible operations on data of this type, and the behavior of these operations. This mathematical model contrasts with data structures, which are concrete representations of data, and are the point of view of an implementer, not a user. For example, a stack has push/pop operations that follow a Last-In-First-Out rule, and can be concretely implemented using either a list or an array. Another example is a set which stores values, without any particular order, and no repeated values. Values themselves are not retrieved from sets, rather one tests a value for membership to obtain a Boolean "in" or "not in".
Distributed computing is a field of computer science that studies distributed systems, defined as computer systems whose inter-communicating components are located on different networked computers.

In computer science, a data structure is a data organization, and storage format that is usually chosen for efficient access to data. More precisely, a data structure is a collection of data values, the relationships among them, and the functions or operations that can be applied to the data, i.e., it is an algebraic structure about data.
In computer science, a priority queue is an abstract data-type similar to a regular queue or stack data structure. Each element in a priority queue has an associated priority. In a priority queue, elements with high priority are served before elements with low priority. In some implementations, if two elements have the same priority, they are served in the same order in which they were enqueued. In other implementations, the order of elements with the same priority is undefined.
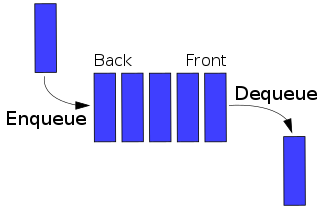
In computer science, a queue is a collection of entities that are maintained in a sequence and can be modified by the addition of entities at one end of the sequence and the removal of entities from the other end of the sequence. By convention, the end of the sequence at which elements are added is called the back, tail, or rear of the queue, and the end at which elements are removed is called the head or front of the queue, analogously to the words used when people line up to wait for goods or services.
In computer science, mutual exclusion is a property of concurrency control, which is instituted for the purpose of preventing race conditions. It is the requirement that one thread of execution never enters a critical section while a concurrent thread of execution is already accessing said critical section, which refers to an interval of time during which a thread of execution accesses a shared resource or shared memory.

In computer science, a semaphore is a variable or abstract data type used to control access to a common resource by multiple threads and avoid critical section problems in a concurrent system such as a multitasking operating system. Semaphores are a type of synchronization primitive. A trivial semaphore is a plain variable that is changed depending on programmer-defined conditions.
Multiversion concurrency control, is a non-locking concurrency control method commonly used by database management systems to provide concurrent access to the database and in programming languages to implement transactional memory.
In computer science, amortized analysis is a method for analyzing a given algorithm's complexity, or how much of a resource, especially time or memory, it takes to execute. The motivation for amortized analysis is that looking at the worst-case run time can be too pessimistic. Instead, amortized analysis averages the running times of operations in a sequence over that sequence. As a conclusion: "Amortized analysis is a useful tool that complements other techniques such as worst-case and average-case analysis."
Theoretical computer science (TCS) is a subset of general computer science and mathematics that focuses on mathematical aspects of computer science such as the theory of computation (TOC), formal language theory, the lambda calculus and type theory.
In computer science, an algorithm is called non-blocking if failure or suspension of any thread cannot cause failure or suspension of another thread; for some operations, these algorithms provide a useful alternative to traditional blocking implementations. A non-blocking algorithm is lock-free if there is guaranteed system-wide progress, and wait-free if there is also guaranteed per-thread progress. "Non-blocking" was used as a synonym for "lock-free" in the literature until the introduction of obstruction-freedom in 2003.

In concurrent programming, an operation is linearizable if it consists of an ordered list of invocation and response events, that may be extended by adding response events such that:
- The extended list can be re-expressed as a sequential history.
- That sequential history is a subset of the original unextended list.
In computer science, software transactional memory (STM) is a concurrency control mechanism analogous to database transactions for controlling access to shared memory in concurrent computing. It is an alternative to lock-based synchronization. STM is a strategy implemented in software, rather than as a hardware component. A transaction in this context occurs when a piece of code executes a series of reads and writes to shared memory. These reads and writes logically occur at a single instant in time; intermediate states are not visible to other (successful) transactions. The idea of providing hardware support for transactions originated in a 1986 paper by Tom Knight. The idea was popularized by Maurice Herlihy and J. Eliot B. Moss. In 1995, Nir Shavit and Dan Touitou extended this idea to software-only transactional memory (STM). Since 2005, STM has been the focus of intense research and support for practical implementations is growing.
Eventual consistency is a consistency model used in distributed computing to achieve high availability that informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. Eventual consistency, also called optimistic replication, is widely deployed in distributed systems and has origins in early mobile computing projects. A system that has achieved eventual consistency is often said to have converged, or achieved replica convergence. Eventual consistency is a weak guarantee – most stronger models, like linearizability, are trivially eventually consistent.
In computer science, gang scheduling is a scheduling algorithm for parallel systems that schedules related threads or processes to run simultaneously on different processors. Usually these will be threads all belonging to the same process, but they may also be from different processes, where the processes could have a producer-consumer relationship or come from the same MPI program.
Concurrent computing is a form of computing in which several computations are executed concurrently—during overlapping time periods—instead of sequentially—with one completing before the next starts.
Replication in computing involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
In computer science, a concurrent data structure is a particular way of storing and organizing data for access by multiple computing threads on a computer.
In computer science, integer sorting is the algorithmic problem of sorting a collection of data values by integer keys. Algorithms designed for integer sorting may also often be applied to sorting problems in which the keys are floating point numbers, rational numbers, or text strings. The ability to perform integer arithmetic on the keys allows integer sorting algorithms to be faster than comparison sorting algorithms in many cases, depending on the details of which operations are allowed in the model of computing and how large the integers to be sorted are.
This glossary of computer science is a list of definitions of terms and concepts used in computer science, its sub-disciplines, and related fields, including terms relevant to software, data science, and computer programming.
References
- ↑ "active data structure". xlinux.nist.gov.
- ↑ Andrews, Gregory R.; Dobkin, David P. (9 March 1981). Active data structures. 5th International Conference on Software Engineering, ICSE 1981. IEEE Computer Society. pp. 354–362.
- ↑ Tangwongsan, Kanat (5 May 2006). Active Data Structures and Applications to Dynamic and Kinetic Algorithms (PDF) (Thesis).
![]() This article incorporates public domain material from Paul E. Black. "Active Data Structure". Dictionary of Algorithms and Data Structures . NIST.
This article incorporates public domain material from Paul E. Black. "Active Data Structure". Dictionary of Algorithms and Data Structures . NIST.