In computing, online analytical processing, or OLAP, is an approach to quickly answer multi-dimensional analytical (MDA) queries. The term OLAP was created as a slight modification of the traditional database term online transaction processing (OLTP). OLAP is part of the broader category of business intelligence, which also encompasses relational databases, report writing and data mining. Typical applications of OLAP include business reporting for sales, marketing, management reporting, business process management (BPM), budgeting and forecasting, financial reporting and similar areas, with new applications emerging, such as agriculture.
Apache Hadoop is a collection of open-source software utilities that facilitates using a network of many computers to solve problems involving massive amounts of data and computation. It provides a software framework for distributed storage and processing of big data using the MapReduce programming model. Hadoop was originally designed for computer clusters built from commodity hardware, which is still the common use. It has since also found use on clusters of higher-end hardware. All the modules in Hadoop are designed with a fundamental assumption that hardware failures are common occurrences and should be automatically handled by the framework.
Microsoft SQL Server is a proprietary relational database management system developed by Microsoft. As a database server, it is a software product with the primary function of storing and retrieving data as requested by other software applications—which may run either on the same computer or on another computer across a network. Microsoft markets at least a dozen different editions of Microsoft SQL Server, aimed at different audiences and for workloads ranging from small single-machine applications to large Internet-facing applications with many concurrent users.
Dryad was a research project at Microsoft Research for a general purpose runtime for execution of data parallel applications. The research prototypes of the Dryad and DryadLINQ data-parallel processing frameworks are available in source form at GitHub.
HBase is an open-source non-relational distributed database modeled after Google's Bigtable and written in Java. It is developed as part of Apache Software Foundation's Apache Hadoop project and runs on top of HDFS or Alluxio, providing Bigtable-like capabilities for Hadoop. That is, it provides a fault-tolerant way of storing large quantities of sparse data.

Microsoft Azure, or just Azure, is the cloud computing platform developed by Microsoft. It has management, access and development of applications and services to individuals, companies, and governments through its global infrastructure. It also provides capabilities that are usually not included within other cloud platforms, including software as a service (SaaS), platform as a service (PaaS), and infrastructure as a service (IaaS). Microsoft Azure supports many programming languages, tools, and frameworks, including Microsoft-specific and third-party software and systems.

Apache Hive is a data warehouse software project. It is built on top of Apache Hadoop for providing data query and analysis. Hive gives an SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop. Traditional SQL queries must be implemented in the MapReduce Java API to execute SQL applications and queries over distributed data.
A cloud database is a database that typically runs on a cloud computing platform and access to the database is provided as-a-service. There are two common deployment models: users can run databases on the cloud independently, using a virtual machine image, or they can purchase access to a database service, maintained by a cloud database provider. Of the databases available on the cloud, some are SQL-based and some use a NoSQL data model.

SingleStore is a proprietary, cloud-native database designed for data-intensive applications. A distributed, relational, SQL database management system (RDBMS) that features ANSI SQL support, it is known for speed in data ingest, transaction processing, and query processing.

Apache Drill is an open-source software framework that supports data-intensive distributed applications for interactive analysis of large-scale datasets. Built chiefly by contributions from developers from MapR, Drill is inspired by Google's Dremel system. Drill is an Apache top-level project. Tom Shiran is the founder of the Apache Drill Project. It was designated an Apache Software Foundation top-level project in December 2016.
Sqoop is a command-line interface application for transferring data between relational databases and Hadoop.

Oracle NoSQL Database is a NoSQL-type distributed key-value database from Oracle Corporation. It provides transactional semantics for data manipulation, horizontal scalability, and simple administration and monitoring.
Apache Impala is an open source massively parallel processing (MPP) SQL query engine for data stored in a computer cluster running Apache Hadoop. Impala has been described as the open-source equivalent of Google F1, which inspired its development in 2012.
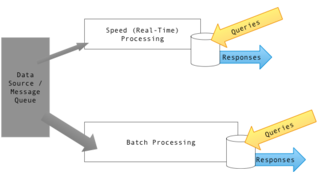
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation. The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce.

Azure Cosmos DB is a globally distributed, multi-model database service offered by Microsoft. It is designed to provide high availability, scalability, and low-latency access to data for modern applications. Unlike traditional relational databases, Cosmos DB is a NoSQL and vector database, which means it can handle unstructured, semi-structured, structured, and vector data types.

Apache Ignite is a distributed database management system for high-performance computing.
Alluxio is an open-source virtual distributed file system (VDFS). Initially as research project "Tachyon", Alluxio was created at the University of California, Berkeley's AMPLab as Haoyuan Li's Ph.D. Thesis, advised by Professor Scott Shenker & Professor Ion Stoica. Alluxio sits between computation and storage in the big data analytics stack. It provides a data abstraction layer for computation frameworks, enabling applications to connect to numerous storage systems through a common interface. The software is published under the Apache License.
Azure Data Explorer is a fully-managed big data analytics cloud platform and data-exploration service, developed by Microsoft, that ingests structured, semi-structured and unstructured data. The service then stores this data and answers analytic ad hoc queries on it with seconds of latency. It is a full-text indexing and retrieval database, including time series analysis capabilities and regular expression evaluation and text parsing.