
In mathematics, the associative property is a property of some binary operations that means that rearranging the parentheses in an expression will not change the result. In propositional logic, associativity is a valid rule of replacement for expressions in logical proofs.

Linear algebra is the branch of mathematics concerning linear equations such as:
In mathematics, a symmetric matrix with real entries is positive-definite if the real number is positive for every nonzero real column vector where is the row vector transpose of More generally, a Hermitian matrix is positive-definite if the real number is positive for every nonzero complex column vector where denotes the conjugate transpose of
In machine learning, the perceptron is an algorithm for supervised learning of binary classifiers. A binary classifier is a function which can decide whether or not an input, represented by a vector of numbers, belongs to some specific class. It is a type of linear classifier, i.e. a classification algorithm that makes its predictions based on a linear predictor function combining a set of weights with the feature vector.

In geometry, a normal is an object that is perpendicular to a given object. For example, the normal line to a plane curve at a given point is the line perpendicular to the tangent line to the curve at the point.
Unsupervised learning is a framework in machine learning where, in contrast to supervised learning, algorithms learn patterns exclusively from unlabeled data. Other frameworks in the spectrum of supervisions include weak- or semi-supervision, where a small portion of the data is tagged, and self-supervision. Some researchers consider self-supervised learning a form of unsupervised learning.
In statistics, canonical-correlation analysis (CCA), also called canonical variates analysis, is a way of inferring information from cross-covariance matrices. If we have two vectors X = (X1, ..., Xn) and Y = (Y1, ..., Ym) of random variables, and there are correlations among the variables, then canonical-correlation analysis will find linear combinations of X and Y that have a maximum correlation with each other. T. R. Knapp notes that "virtually all of the commonly encountered parametric tests of significance can be treated as special cases of canonical-correlation analysis, which is the general procedure for investigating the relationships between two sets of variables." The method was first introduced by Harold Hotelling in 1936, although in the context of angles between flats the mathematical concept was published by Camille Jordan in 1875.
Hebbian theory is a neuropsychological theory claiming that an increase in synaptic efficacy arises from a presynaptic cell's repeated and persistent stimulation of a postsynaptic cell. It is an attempt to explain synaptic plasticity, the adaptation of brain neurons during the learning process. It was introduced by Donald Hebb in his 1949 book The Organization of Behavior. The theory is also called Hebb's rule, Hebb's postulate, and cell assembly theory. Hebb states it as follows:
Let us assume that the persistence or repetition of a reverberatory activity tends to induce lasting cellular changes that add to its stability. ... When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A’s efficiency, as one of the cells firing B, is increased.
A Hopfield network is a form of recurrent neural network, or a spin glass system, that can serve as a content-addressable memory. The Hopfield network, named for John Hopfield, consists of a single layer of neurons, where each neuron is connected to every other neuron except itself. These connections are bidirectional and symmetric, meaning the weight of the connection from neuron i to neuron j is the same as the weight from neuron j to neuron i. Patterns are associatively recalled by fixing certain inputs, and dynamically evolve the network to minimize an energy function, towards local energy minimum states that correspond to stored patterns. Patterns are associatively learned by a Hebbian learning algorithm.
Recurrent neural networks (RNNs) are a class of artificial neural networks for sequential data processing. Unlike feedforward neural networks, which process data in a single pass, RNNs process data across multiple time steps, making them well-adapted for modelling and processing text, speech, and time series.

Quantum neural networks are computational neural network models which are based on the principles of quantum mechanics. The first ideas on quantum neural computation were published independently in 1995 by Subhash Kak and Ron Chrisley, engaging with the theory of quantum mind, which posits that quantum effects play a role in cognitive function. However, typical research in quantum neural networks involves combining classical artificial neural network models with the advantages of quantum information in order to develop more efficient algorithms. One important motivation for these investigations is the difficulty to train classical neural networks, especially in big data applications. The hope is that features of quantum computing such as quantum parallelism or the effects of interference and entanglement can be used as resources. Since the technological implementation of a quantum computer is still in a premature stage, such quantum neural network models are mostly theoretical proposals that await their full implementation in physical experiments.
The softmax function, also known as softargmax or normalized exponential function, converts a vector of K real numbers into a probability distribution of K possible outcomes. It is a generalization of the logistic function to multiple dimensions, and used in multinomial logistic regression. The softmax function is often used as the last activation function of a neural network to normalize the output of a network to a probability distribution over predicted output classes.
Autoassociative memory, also known as auto-association memory or an autoassociation network, is any type of memory that is able to retrieve a piece of data from only a tiny sample of itself. They are very effective in de-noising or removing interference from the input and can be used to determine whether the given input is “known” or “unknown”.
The image segmentation problem is concerned with partitioning an image into multiple regions according to some homogeneity criterion. This article is primarily concerned with graph theoretic approaches to image segmentation applying graph partitioning via minimum cut or maximum cut. Segmentation-based object categorization can be viewed as a specific case of spectral clustering applied to image segmentation.
In statistics, projection pursuit regression (PPR) is a statistical model developed by Jerome H. Friedman and Werner Stuetzle that extends additive models. This model adapts the additive models in that it first projects the data matrix of explanatory variables in the optimal direction before applying smoothing functions to these explanatory variables.
There are many types of artificial neural networks (ANN).

A restricted Boltzmann machine (RBM) is a generative stochastic artificial neural network that can learn a probability distribution over its set of inputs.
An attractor network is a type of recurrent dynamical network, that evolves toward a stable pattern over time. Nodes in the attractor network converge toward a pattern that may either be fixed-point, cyclic, chaotic or random (stochastic). Attractor networks have largely been used in computational neuroscience to model neuronal processes such as associative memory and motor behavior, as well as in biologically inspired methods of machine learning.
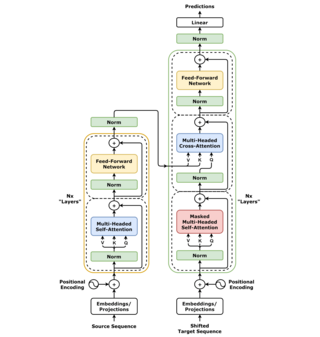
A transformer is a deep learning architecture developed by researchers at Google and based on the multi-head attention mechanism, proposed in a 2017 paper "Attention Is All You Need". Text is converted to numerical representations called tokens, and each token is converted into a vector via looking up from a word embedding table. At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism allowing the signal for key tokens to be amplified and less important tokens to be diminished.
Modern Hopfield networks are generalizations of the classical Hopfield networks that break the linear scaling relationship between the number of input features and the number of stored memories. This is achieved by introducing stronger non-linearities leading to super-linear memory storage capacity as a function of the number of feature neurons. The network still requires a sufficient number of hidden neurons.













