In mathematics, a symmetric matrix with real entries is positive-definite if the real number is positive for every nonzero real column vector where is the row vector transpose of More generally, a Hermitian matrix is positive-definite if the real number is positive for every nonzero complex column vector where denotes the conjugate transpose of

Linear programming (LP), also called linear optimization, is a method to achieve the best outcome in a mathematical model whose requirements and objective are represented by linear relationships. Linear programming is a special case of mathematical programming.

In mathematics, the cross product or vector product is a binary operation on two vectors in a three-dimensional oriented Euclidean vector space, and is denoted by the symbol . Given two linearly independent vectors a and b, the cross product, a × b, is a vector that is perpendicular to both a and b, and thus normal to the plane containing them. It has many applications in mathematics, physics, engineering, and computer programming. It should not be confused with the dot product.
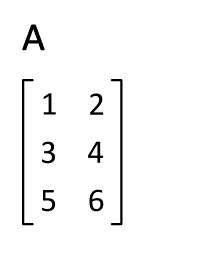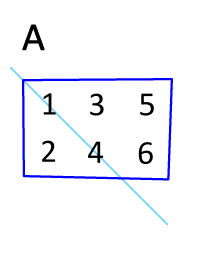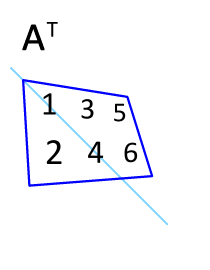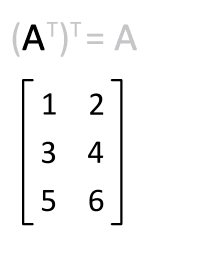
In linear algebra, the transpose of a matrix is an operator which flips a matrix over its diagonal; that is, it switches the row and column indices of the matrix A by producing another matrix, often denoted by AT.
In linear algebra, a diagonal matrix is a matrix in which the entries outside the main diagonal are all zero; the term usually refers to square matrices. Elements of the main diagonal can either be zero or nonzero. An example of a 2×2 diagonal matrix is , while an example of a 3×3 diagonal matrix is. An identity matrix of any size, or any multiple of it is a diagonal matrix called a scalar matrix, for example, . In geometry, a diagonal matrix may be used as a scaling matrix, since matrix multiplication with it results in changing scale (size) and possibly also shape; only a scalar matrix results in uniform change in scale.
In mathematics, the conjugate transpose, also known as the Hermitian transpose, of an complex matrix is an matrix obtained by transposing and applying complex conjugation to each entry. There are several notations, such as or , , or .
In mathematics, the falling factorial is defined as the polynomial
In linear algebra, a Vandermonde matrix, named after Alexandre-Théophile Vandermonde, is a matrix with the terms of a geometric progression in each row: an matrix
The quadratic sieve algorithm (QS) is an integer factorization algorithm and, in practice, the second-fastest method known. It is still the fastest for integers under 100 decimal digits or so, and is considerably simpler than the number field sieve. It is a general-purpose factorization algorithm, meaning that its running time depends solely on the size of the integer to be factored, and not on special structure or properties. It was invented by Carl Pomerance in 1981 as an improvement to Schroeppel's linear sieve.
In mathematics, the matrix exponential is a matrix function on square matrices analogous to the ordinary exponential function. It is used to solve systems of linear differential equations. In the theory of Lie groups, the matrix exponential gives the exponential map between a matrix Lie algebra and the corresponding Lie group.
In mathematics, a matrix of ones or all-ones matrix is a matrix with every entry equal to one. For example:
In mathematics, the kernel of a linear map, also known as the null space or nullspace, is the part of the domain which is mapped to the zero vector of the co-domain; the kernel is always a linear subspace of the domain. That is, given a linear map L : V → W between two vector spaces V and W, the kernel of L is the vector space of all elements v of V such that L(v) = 0, where 0 denotes the zero vector in W, or more symbolically:
In linear algebra, an eigenvector or characteristic vector is a vector that has its direction unchanged by a given linear transformation. More precisely, an eigenvector, , of a linear transformation, , is scaled by a constant factor, , when the linear transformation is applied to it: . The corresponding eigenvalue, characteristic value, or characteristic root is the multiplying factor .
In mathematics, a moment matrix is a special symmetric square matrix whose rows and columns are indexed by monomials. The entries of the matrix depend on the product of the indexing monomials only

In mathematics, stability theory addresses the stability of solutions of differential equations and of trajectories of dynamical systems under small perturbations of initial conditions. The heat equation, for example, is a stable partial differential equation because small perturbations of initial data lead to small variations in temperature at a later time as a result of the maximum principle. In partial differential equations one may measure the distances between functions using Lp norms or the sup norm, while in differential geometry one may measure the distance between spaces using the Gromov–Hausdorff distance.
In mathematics, in the field of control theory, a Sylvester equation is a matrix equation of the form:
In linear algebra, eigendecomposition is the factorization of a matrix into a canonical form, whereby the matrix is represented in terms of its eigenvalues and eigenvectors. Only diagonalizable matrices can be factorized in this way. When the matrix being factorized is a normal or real symmetric matrix, the decomposition is called "spectral decomposition", derived from the spectral theorem.
In mathematics, the quadratic eigenvalue problem (QEP), is to find scalar eigenvalues , left eigenvectors and right eigenvectors such that

In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression.
Brahmagupta polynomials are a class of polynomials associated with the Brahmagupa matrix which in turn is associated with the Brahmagupta's identity. The concept and terminology were introduced by E. R. Suryanarayan, University of Rhode Island, Kingston in a paper published in 1996. These polynomials have several interesting properties and have found applications in tiling problems and in the problem of finding Heronian triangles in which the lengths of the sides are consecutive integers.





