
In computer science, a control-flow graph (CFG) is a representation, using graph notation, of all paths that might be traversed through a program during its execution. The control-flow graph was discovered by Frances E. Allen, who noted that Reese T. Prosser used boolean connectivity matrices for flow analysis before.
In compiler design, static single assignment form is a type of intermediate representation (IR) where each variable is assigned exactly once. SSA is used in most high-quality optimizing compilers for imperative languages, including LLVM, the GNU Compiler Collection, and many commercial compilers.
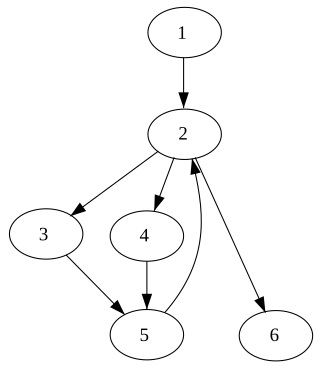
In computer science, a node d of a control-flow graph dominates a node n if every path from the entry node to n must go through d. Notationally, this is written as d dom n. By definition, every node dominates itself.
Data-flow analysis is a technique for gathering information about the possible set of values calculated at various points in a computer program. A program's control-flow graph (CFG) is used to determine those parts of a program to which a particular value assigned to a variable might propagate. The information gathered is often used by compilers when optimizing a program. A canonical example of a data-flow analysis is reaching definitions.
In computer science, a topological sort or topological ordering of a directed graph is a linear ordering of its vertices such that for every directed edge (u,v) from vertex u to vertex v, u comes before v in the ordering. For instance, the vertices of the graph may represent tasks to be performed, and the edges may represent constraints that one task must be performed before another; in this application, a topological ordering is just a valid sequence for the tasks. Precisely, a topological sort is a graph traversal in which each node v is visited only after all its dependencies are visited. A topological ordering is possible if and only if the graph has no directed cycles, that is, if it is a directed acyclic graph (DAG). Any DAG has at least one topological ordering, and algorithms are known for constructing a topological ordering of any DAG in linear time. Topological sorting has many applications, especially in ranking problems such as feedback arc set. Topological sorting is also possible when the DAG has disconnected components.
Cyclomatic complexity is a software metric used to indicate the complexity of a program. It is a quantitative measure of the number of linearly independent paths through a program's source code. It was developed by Thomas J. McCabe, Sr. in 1976.
In computer science, instruction scheduling is a compiler optimization used to improve instruction-level parallelism, which improves performance on machines with instruction pipelines. Put more simply, it tries to do the following without changing the meaning of the code:
In compiler theory, a reaching definition for a given instruction is an earlier instruction whose target variable can reach the given one without an intervening assignment. For example, in the following code:
d1 : y := 3 d2 : x := y
In compiler theory, loop optimization is the process of increasing execution speed and reducing the overheads associated with loops. It plays an important role in improving cache performance and making effective use of parallel processing capabilities. Most execution time of a scientific program is spent on loops; as such, many compiler optimization techniques have been developed to make them faster.
In compiler theory, dependence analysis produces execution-order constraints between statements/instructions. Broadly speaking, a statement S2 depends on S1 if S1 must be executed before S2. Broadly, there are two classes of dependencies--control dependencies and data dependencies.
In computer science, loop dependence analysis is a process which can be used to find dependencies within iterations of a loop with the goal of determining different relationships between statements. These dependent relationships are tied to the order in which different statements access memory locations. Using the analysis of these relationships, execution of the loop can be organized to allow multiple processors to work on different portions of the loop in parallel. This is known as parallel processing. In general, loops can consume a lot of processing time when executed as serial code. Through parallel processing, it is possible to reduce the total execution time of a program through sharing the processing load among multiple processors.
ID/LP Grammars are a subset of Phrase Structure Grammars, differentiated from other formal grammars by distinguishing between immediate dominance (ID) and linear precedence (LP) constraints. Whereas traditional phrase structure rules incorporate dominance and precedence into a single rule, ID/LP Grammars maintains separate rule sets which need not be processed simultaneously. ID/LP Grammars are used in Computational Linguistics.
Automatic vectorization, in parallel computing, is a special case of automatic parallelization, where a computer program is converted from a scalar implementation, which processes a single pair of operands at a time, to a vector implementation, which processes one operation on multiple pairs of operands at once. For example, modern conventional computers, including specialized supercomputers, typically have vector operations that simultaneously perform operations such as the following four additions :
A data dependency in computer science is a situation in which a program statement (instruction) refers to the data of a preceding statement. In compiler theory, the technique used to discover data dependencies among statements is called dependence analysis.
In mathematics, computer science and digital electronics, a dependency graph is a directed graph representing dependencies of several objects towards each other. It is possible to derive an evaluation order or the absence of an evaluation order that respects the given dependencies from the dependency graph.

In metaphysics, a causal model is a conceptual model that describes the causal mechanisms of a system. Several types of causal notation may be used in the development of a causal model. Causal models can improve study designs by providing clear rules for deciding which independent variables need to be included/controlled for.
Loop-level parallelism is a form of parallelism in software programming that is concerned with extracting parallel tasks from loops. The opportunity for loop-level parallelism often arises in computing programs where data is stored in random access data structures. Where a sequential program will iterate over the data structure and operate on indices one at a time, a program exploiting loop-level parallelism will use multiple threads or processes which operate on some or all of the indices at the same time. Such parallelism provides a speedup to overall execution time of the program, typically in line with Amdahl's law.
Node graph architecture is a software design structured around the notion of a node graph. Both the source code and the user interface are designed around the editing and composition of atomic functional units. Node graphs are a type of visual programming language.
In parallel computing, work stealing is a scheduling strategy for multithreaded computer programs. It solves the problem of executing a dynamically multithreaded computation, one that can "spawn" new threads of execution, on a statically multithreaded computer, with a fixed number of processors. It does so efficiently in terms of execution time, memory usage, and inter-processor communication.
A graphoid is a set of statements of the form, "X is irrelevant to Y given that we know Z" where X, Y and Z are sets of variables. The notion of "irrelevance" and "given that we know" may obtain different interpretations, including probabilistic, relational and correlational, depending on the application. These interpretations share common properties that can be captured by paths in graphs. The theory of graphoids characterizes these properties in a finite set of axioms that are common to informational irrelevance and its graphical representations.




