Related Research Articles

In computing, a database is an organized collection of data or a type of data store based on the use of a database management system (DBMS), the software that interacts with end users, applications, and the database itself to capture and analyze the data. The DBMS additionally encompasses the core facilities provided to administer the database. The sum total of the database, the DBMS and the associated applications can be referred to as a database system. Often the term "database" is also used loosely to refer to any of the DBMS, the database system or an application associated with the database.
A relational database is a database based on the relational model of data, as proposed by E. F. Codd in 1970. A system used to maintain relational databases is a relational database management system (RDBMS). Many relational database systems are equipped with the option of using SQL for querying and updating the database.
Ingres Database is a proprietary SQL relational database management system intended to support large commercial and government applications.
Db2 is a family of data management products, including database servers, developed by IBM. It initially supported the relational model, but was extended to support object–relational features and non-relational structures like JSON and XML. The brand name was originally styled as DB/2, then DB2 until 2017 and finally changed to its present form.
In database systems, isolation determines how transaction integrity is visible to other users and systems.
The following tables compare general and technical information for a number of relational database management systems. Please see the individual products' articles for further information. Unless otherwise specified in footnotes, comparisons are based on the stable versions without any add-ons, extensions or external programs.
The Access Database Engine is a database engine on which several Microsoft products have been built. The first version of Jet was developed in 1992, consisting of three modules which could be used to manipulate a database.
Online transaction processing (OLTP) is a type of database system used in transaction-oriented applications, such as many operational systems. "Online" refers to that such systems are expected to respond to user requests and process them in real-time. The term is contrasted with online analytical processing (OLAP) which instead focuses on data analysis.
In database computing, Oracle Real Application Clusters (RAC) — an option for the Oracle Database software produced by Oracle Corporation and introduced in 2001 with Oracle9i — provides software for clustering and high availability in Oracle database environments. Oracle Corporation includes RAC with the Enterprise Edition, provided the nodes are clustered using Oracle Clusterware.

Virtuoso Universal Server is a middleware and database engine hybrid that combines the functionality of a traditional relational database management system (RDBMS), object–relational database (ORDBMS), virtual database, RDF, XML, free-text, web application server and file server functionality in a single system. Rather than have dedicated servers for each of the aforementioned functionality realms, Virtuoso is a "universal server"; it enables a single multithreaded server process that implements multiple protocols. The free and open source edition of Virtuoso Universal Server is also known as OpenLink Virtuoso. The software has been developed by OpenLink Software with Kingsley Uyi Idehen and Orri Erling as the chief software architects.
SAP IQ is a column-based, petabyte scale, relational database software system used for business intelligence, data warehousing, and data marts. Produced by Sybase Inc., now an SAP company, its primary function is to analyze large amounts of data in a low-cost, highly available environment. SAP IQ is often credited with pioneering the commercialization of column-store technology.
Microsoft SQL Server is a proprietary relational database management system developed by Microsoft. As a database server, it is a software product with the primary function of storing and retrieving data as requested by other software applications—which may run either on the same computer or on another computer across a network. Microsoft markets at least a dozen different editions of Microsoft SQL Server, aimed at different audiences and for workloads ranging from small single-machine applications to large Internet-facing applications with many concurrent users.
A database shard, or simply a shard, is a horizontal partition of data in a database or search engine. Each shard is held on a separate database server instance, to spread load.
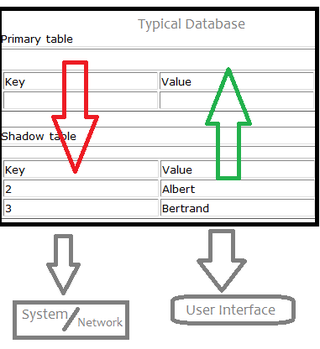
Shadow tables are objects in computer science used to improve the way machines, networks and programs handle information. More specifically, a shadow table is an object that is read and written by a processor and contains data similar to its primary table, which is the table it's "shadowing". Shadow tables usually contain data that is relevant to the operation and maintenance of its primary table, but not within the subset of data required for the primary table to exist. Shadow tables are related to the data type "trails" in data storage systems. Trails are very similar to shadow tables but instead of storing identically formatted information that is different, they store a history of modifications and functions operated on a table.
In computer science, in-memory processing (PIM) is a computer architecture for processing data stored in an in-memory database. In-memory processing improves the power usage and performance of moving data between the processor and the main memory. Older systems have been based on disk storage and relational databases using Structured Query Language, which are increasingly regarded as inadequate to meet business intelligence (BI) needs. Because stored data is accessed much more quickly when it is placed in random-access memory (RAM) or flash memory, in-memory processing allows data to be analyzed in real time, enabling faster reporting and decision-making in business.
The following is provided as an overview of and topical guide to databases:
SingleStore is a proprietary, cloud-native database designed for data-intensive applications. A distributed, relational, SQL database management system (RDBMS) that features ANSI SQL support, it is known for speed in data ingest, transaction processing, and query processing.

Oracle NoSQL Database is a NoSQL-type distributed key-value database from Oracle Corporation. It provides transactional semantics for data manipulation, horizontal scalability, and simple administration and monitoring.
NewSQL is a class of relational database management systems that seek to provide the scalability of NoSQL systems for online transaction processing (OLTP) workloads while maintaining the ACID guarantees of a traditional database system.
The following outline is provided as an overview of and topical guide to MySQL:
References
- ↑ Bondi, André B. (2000). Characteristics of scalability and their impact on performance. Proceedings of the second international workshop on Software and performance – WOSP '00. p. 195. doi:10.1145/350391.350432. ISBN 158113195X.
- 1 2 Chopra, Rajiv (2010). Database Management System (DBMS)A Practical Approach. S. Chand Publishing. p. 33. ISBN 9788121932455.
- 1 2 "Row locks vs table locks in Oracle". www.dba-oracle.com. Retrieved 2019-04-11.
- ↑ "The Advantages of a Shared Nothing Architecture for Truly Non-Disruptive Upgrades". solidfire.com. 2014-09-17. Archived from the original on 2015-04-24. Retrieved 2015-04-21.
- ↑ "Real Application Clusters Administration and Deployment Guide". docs.oracle.com. Retrieved 2019-04-11.
- 1 2 "A Primer on Database Replication". www.brianstorti.com. Retrieved 2019-04-11.
- ↑ Martin Zapletal (2015-06-11). "Large volume data analysis on the Typesafe Reactive Platform".
{{cite journal}}: Cite journal requires|journal=(help) - ↑ "Overview of Cloud Bigtable | Cloud Bigtable Documentation". Google Cloud. Retrieved 2019-04-11.
- ↑ Aslett, Matthew (2011). "How Will The Database Incumbents Respond To NoSQL And NewSQL?" (PDF). 451 Group (published 2011-04-04). Retrieved 2012-07-06.
- 1 2 3 Branson, Tony (2016-12-06). "Two main approaches to database scalability". Infosecurity Magazine. Retrieved 2019-04-11.
- ↑ "Clojure - Refs and Transactions". clojure.org. Retrieved 2019-04-12.
- ↑ "Introduction To Reverse Key Indexes: Part I". Richard Foote's Oracle Blog. 2008-01-14. Retrieved 2019-04-13.
- ↑ "clustering" (PDF). Oracle.com. Retrieved 2012-11-07.
- ↑ Base One (2007). "Database Scalability - Dispelling myths about the limits of database-centric architecture" . Retrieved May 23, 2007.