This article may need to be rewritten to comply with Wikipedia's quality standards, as it is poorly written.(February 2024) |
Deadline Scheduler is an I/O scheduler, or disk scheduler, for the Linux kernel. It was written in 2002 by Jens Axboe.
This article may need to be rewritten to comply with Wikipedia's quality standards, as it is poorly written.(February 2024) |
Deadline Scheduler is an I/O scheduler, or disk scheduler, for the Linux kernel. It was written in 2002 by Jens Axboe.
This section may be confusing or unclear to readers. In particular, The queue system is not well explained. A schema would be welcome.(March 2014) |
The main purpose of Deadline Scheduler is to guarantee a start service time for a request. [1] The scheduler imposes a deadline on all I/O operations to prevent a starvation of requests. It maintains two deadline queues, as well as sorted queues (both read and write). Deadline queues are sorted by their expiration time, while the sorted queues are sorted by the sector number.
Before serving the next request, Deadline Scheduler decides which queue to use. Read queues are given a higher priority, because processes usually block on read operations. Next, Deadline Scheduler checks if the first request in the deadline queue has expired. Otherwise, the scheduler serves a batch of requests from the sorted queue. In both cases, the scheduler also serves a batch of requests following the chosen request in the sorted queue.
By default, read requests have an expiration time of 500 ms, and write requests expire in 5 seconds.
A rough version of the scheduler was published on the Linux Kernel Mailing List by Axboe in January 2002. [2]
Measurements have shown that the deadline I/O scheduler outperforms the CFQ I/O scheduler for certain multi-threaded workloads. [3]
This section's tone or style may not reflect the encyclopedic tone used on Wikipedia.(October 2023) |
Deadline executes I/O Operations (IOPs) through the concept of "batches" which are sets of operations ordered in terms of increasing sector number. This tunable determines how big a batch will have to be before the requests are queued to the disk (barring expiration of a currently-being-built batch). Smaller batches can reduce latency by ensuring new requests are executed sooner (rather than possibly waiting for more requests to come in), but may degrade overall throughput by increasing the overall movement of drive heads (since sequencing happens within a batch and not between them). Additionally, if the number of IOPs is high enough the batches will be executed in a timely fashion anyway.
The ‘read_expire’ time is the maximum time in milliseconds after which the read request is considered ‘expired’. The read request is best used before the expiration date. Deadline Scheduler will not attempt to make sure all I/O is issued before its expiration date. However, if the I/O is past expiration, then it gets prioritized.
The read expiration queue is only checked when Deadline Scheduler re-evaluates read queues. For read requests, this means that a sorted read request is dispatched (except for the case of streaming I/O). While the scheduler is streaming I/O from the read queue, the read expired is not evaluated. If there are expired reads, then the first one is pulled from the FIFO. Note that this expired read then is the new nexus for read sort ordering. The cached next pointer will be set to point to the next I/O from the sort queue after this expired one…. The thing to note is that the algorithm doesn’t just execute all expired I/O once they are past their expiration date. This allows some reasonable performance to be maintained by batching up ‘write_starved’ sorted reads together before checking the expired read queue again.
The maximum number of I/O that can be performed between read expired I/O is 2 * 'fifo_batch' * 'writes_starved'. One set of ‘fifo_batch’ streaming reads after the first expired read I/O and if this stream happened to cause the write starved condition, then possibly another ‘fifo_batch’ streaming writes. This is worse case, after which the read expired queue would be re-evaluated. At best, the expired read queue will be evaluated ‘write_starved’ times in a row before being skipped because the write queue would be used.
The 'write_expire' has the same function as read_expire, but instead is used for write operations (grouped into separate batches from read requests).
Deadline Scheduler prioritizes read requests to write requests, so this can lead to situations where the operations executed are almost entirely read requests. This becomes more of an important tunable as write_expire is elongated or overall bandwidth approaches saturation. Decreasing this gives more bandwidth to writes (relatively speaking) at the expense of read operations. If the application workload, however, is read-heavy (for example most HTTP or directory servers) with only an occasional write, decreased latency of average IOPs may be achieved by increasing this (so that more reads must be performed before a write batch is queued to disk).
A "front merge" is an operation where the I/O Scheduler, seeking to condense (or "merge") smaller requests into fewer (larger) operations, will take a new operation then examine the active batch and attempt to locate operations where the beginning sector is the same or immediately after another operation's beginning sector. A "back merge" is the opposite, where ending sectors in the active batch are searched for sectors that are either the same or immediately after the current operation's beginning sectors. Merging diverts operations from the current batch to the active one, decreasing "fairness" in order to increase throughput.
Due to the way files are typically laid out, back merges are much more common than front merges. For some workloads, time may be wasted while attempting to front merge requests. Setting 'front_merges' to 0 disables this functionality. Front merges may still occur due to the cached 'last_merge' hint, but since that comes at basically zero cost, it is still performed. This boolean simply disables front sector lookup when the I/O scheduler merging function is called. Disk merge totals are recorded per-block device in '/proc/diskstats'. [1]
In computing, a context switch is the process of storing the state of a process or thread, so that it can be restored and resume execution at a later point, and then restoring a different, previously saved, state. This allows multiple processes to share a single central processing unit (CPU), and is an essential feature of a multiprogramming or multitasking operating system. In a traditional CPU, each process - a program in execution - utilizes the various CPU registers to store data and hold the current state of the running process. However, in a multitasking operating system, the operating system switches between processes or threads to allow the execution of multiple processes simultaneously. For every switch, the operating system must save the state of the currently running process, followed by loading the next process state, which will run on the CPU. This sequence of operations that stores the state of the running process and the loading of the following running process is called a context switch.
In computing and in systems theory, first in, first out, acronymized as FIFO, is a method for organizing the manipulation of a data structure where the oldest (first) entry, or "head" of the queue, is processed first.
In computing, scheduling is the action of assigning resources to perform tasks. The resources may be processors, network links or expansion cards. The tasks may be threads, processes or data flows.
Completely Fair Queuing (CFQ) is an I/O scheduler for the Linux kernel which was written in 2003 by Jens Axboe.
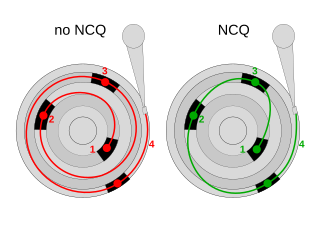
In computing, Native Command Queuing (NCQ) is an extension of the Serial ATA protocol allowing hard disk drives to internally optimize the order in which received read and write commands are executed. This can reduce the amount of unnecessary drive head movement, resulting in increased performance for workloads where multiple simultaneous read/write requests are outstanding, most often occurring in server-type applications.
QIO is a term used in several computer operating systems designed by the former Digital Equipment Corporation (DEC) of Maynard, Massachusetts.
Anticipatory scheduling is an algorithm for scheduling hard disk input/output. It seeks to increase the efficiency of disk utilization by "anticipating" future synchronous read operations.

In computer storage, a disk buffer is the embedded memory in a hard disk drive (HDD) or solid-state drive (SSD) acting as a buffer between the rest of the computer and the physical hard disk platter or flash memory that is used for storage. Modern hard disk drives come with 8 to 256 MiB of such memory, and solid-state drives come with up to 4 GB of cache memory.
Jens Axboe is a Linux kernel hacker.

Input/output (I/O) scheduling is the method that computer operating systems use to decide in which order I/O operations will be submitted to storage volumes. I/O scheduling is sometimes called disk scheduling.

The Completely Fair Scheduler (CFS) was a process scheduler that was merged into the 2.6.23 release of the Linux kernel. It was the default scheduler of the tasks of the SCHED_NORMAL class and handled CPU resource allocation for executing processes, aiming to maximize overall CPU utilization while also maximizing interactive performance.

nmon is a computer performance system monitor tool for the AIX and Linux operating systems. The nmon tool has two modes a) displays the performance stats on-screen in a condensed format or b) the same stats are saved to a comma-separated values (CSV) data file for later graphing and analysis to aid the understanding of computer resource use, tuning options and bottlenecks.
The NOOP scheduler is the simplest I/O scheduler for the Linux kernel. This scheduler was developed by Jens Axboe.

A process is a program in execution, and an integral part of any modern-day operating system (OS). The OS must allocate resources to processes, enable processes to share and exchange information, protect the resources of each process from other processes and enable synchronization among processes. To meet these requirements, the OS must maintain a data structure for each process, which describes the state and resource ownership of that process, and which enables the OS to exert control over each process.
A trim command allows an operating system to inform a solid-state drive (SSD) which blocks of data are no longer considered to be "in use" and therefore can be erased internally.
The Brain Fuck Scheduler (BFS) is a process scheduler designed for the Linux kernel in August 2009 based on earliest eligible virtual deadline first scheduling (EEVDF), as an alternative to the Completely Fair Scheduler (CFS) and the O(1) scheduler. BFS was created by Con Kolivas.
SCHED_DEADLINE is a CPU scheduler available in the Linux kernel since version 3.14, based on the earliest deadline first (EDF) and constant bandwidth server (CBS) algorithms, supporting resource reservations: each task scheduled under such policy is associated with a budget Q, and a period P, corresponding to a declaration to the kernel that Q time units are required by that task every P time units, on any processor. This makes SCHED_DEADLINE particularly suitable for real-time applications, like multimedia or industrial control, where P corresponds to the minimum time elapsing between subsequent activations of the task, and Q corresponds to the worst-case execution time needed by each activation of the task.
bcache is a cache in the Linux kernel's block layer, which is used for accessing secondary storage devices. It allows one or more fast storage devices, such as flash-based solid-state drives (SSDs), to act as a cache for one or more slower storage devices, such as hard disk drives (HDDs); this effectively creates hybrid volumes and provides performance improvements.
dm-cache is a component of the Linux kernel's device mapper, which is a framework for mapping block devices onto higher-level virtual block devices. It allows one or more fast storage devices, such as flash-based solid-state drives (SSDs), to act as a cache for one or more slower storage devices such as hard disk drives (HDDs); this effectively creates hybrid volumes and provides secondary storage performance improvements.
io_uring is a Linux kernel system call interface for storage device asynchronous I/O operations addressing performance issues with similar interfaces provided by functions like read /write or aio_read /aio_write etc. for operations on data accessed by file descriptors.