Reinforcement learning (RL) is an interdisciplinary area of machine learning and optimal control concerned with how an intelligent agent ought to take actions in a dynamic environment in order to maximize the cumulative reward. Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.

Kőnig's lemma or Kőnig's infinity lemma is a theorem in graph theory due to the Hungarian mathematician Dénes Kőnig who published it in 1927. It gives a sufficient condition for an infinite graph to have an infinitely long path. The computability aspects of this theorem have been thoroughly investigated by researchers in mathematical logic, especially in computability theory. This theorem also has important roles in constructive mathematics and proof theory.
In mathematics, a Markov decision process (MDP) is a discrete-time stochastic control process. It provides a mathematical framework for modeling decision making in situations where outcomes are partly random and partly under the control of a decision maker. MDPs are useful for studying optimization problems solved via dynamic programming. MDPs were known at least as early as the 1950s; a core body of research on Markov decision processes resulted from Ronald Howard's 1960 book, Dynamic Programming and Markov Processes. They are used in many disciplines, including robotics, automatic control, economics and manufacturing. The name of MDPs comes from the Russian mathematician Andrey Markov as they are an extension of Markov chains.
Q-learning is a model-free reinforcement learning algorithm to learn the value of an action in a particular state. It does not require a model of the environment, and it can handle problems with stochastic transitions and rewards without requiring adaptations.
In the mathematical field of set theory, ordinal arithmetic describes the three usual operations on ordinal numbers: addition, multiplication, and exponentiation. Each can be defined in essentially two different ways: either by constructing an explicit well-ordered set that represents the result of the operation or by using transfinite recursion. Cantor normal form provides a standardized way of writing ordinals. In addition to these usual ordinal operations, there are also the "natural" arithmetic of ordinals and the nimber operations.

In probability theory and machine learning, the multi-armed bandit problem is a problem in which a decision maker iteratively selects one of multiple fixed choices when the properties of each choice are only partially known at the time of allocation, and may become better understood as time passes. A fundamental aspect of bandit problems is that choosing an arm does not affect the properties of the arm or other arms.
A partially observable Markov decision process (POMDP) is a generalization of a Markov decision process (MDP). A POMDP models an agent decision process in which it is assumed that the system dynamics are determined by an MDP, but the agent cannot directly observe the underlying state. Instead, it must maintain a sensor model and the underlying MDP. Unlike the policy function in MDP which maps the underlying states to the actions, POMDP's policy is a mapping from the history of observations to the actions.
In physics and mathematics, the Gibbs measure, named after Josiah Willard Gibbs, is a probability measure frequently seen in many problems of probability theory and statistical mechanics. It is a generalization of the canonical ensemble to infinite systems. The canonical ensemble gives the probability of the system X being in state x as
In mathematics, especially in the study of dynamical systems, a limit set is the state a dynamical system reaches after an infinite amount of time has passed, by either going forward or backwards in time. Limit sets are important because they can be used to understand the long term behavior of a dynamical system. A system that has reached its limiting set is said to be at equilibrium.
In mathematics, the theory of optimal stopping or early stopping is concerned with the problem of choosing a time to take a particular action, in order to maximise an expected reward or minimise an expected cost. Optimal stopping problems can be found in areas of statistics, economics, and mathematical finance. A key example of an optimal stopping problem is the secretary problem. Optimal stopping problems can often be written in the form of a Bellman equation, and are therefore often solved using dynamic programming.
Linear Programming Boosting (LPBoost) is a supervised classifier from the boosting family of classifiers. LPBoost maximizes a margin between training samples of different classes and hence also belongs to the class of margin-maximizing supervised classification algorithms. Consider a classification function
In probability theory, a standard probability space, also called Lebesgue–Rokhlin probability space or just Lebesgue space is a probability space satisfying certain assumptions introduced by Vladimir Rokhlin in 1940. Informally, it is a probability space consisting of an interval and/or a finite or countable number of atoms.
In game theory, a stochastic game, introduced by Lloyd Shapley in the early 1950s, is a repeated game with probabilistic transitions played by one or more players. The game is played in a sequence of stages. At the beginning of each stage the game is in some state. The players select actions and each player receives a payoff that depends on the current state and the chosen actions. The game then moves to a new random state whose distribution depends on the previous state and the actions chosen by the players. The procedure is repeated at the new state and play continues for a finite or infinite number of stages. The total payoff to a player is often taken to be the discounted sum of the stage payoffs or the limit inferior of the averages of the stage payoffs.
An -superprocess, , within mathematics probability theory is a stochastic process on that is usually constructed as a special limit of near-critical branching diffusions.
Metal-mesh optical filters are optical filters made from stacks of metal meshes and dielectric. They are used as part of an optical path to filter the incoming light to allow frequencies of interest to pass while reflecting other frequencies of light.
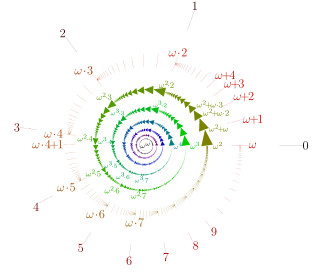
In set theory, an ordinal number, or ordinal, is a generalization of ordinal numerals aimed to extend enumeration to infinite sets.

In computer science, a suffix automaton is an efficient data structure for representing the substring index of a given string which allows the storage, processing, and retrieval of compressed information about all its substrings. The suffix automaton of a string is the smallest directed acyclic graph with a dedicated initial vertex and a set of "final" vertices, such that paths from the initial vertex to final vertices represent the suffixes of the string.
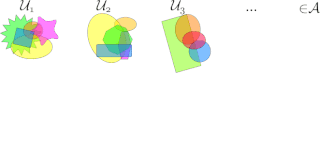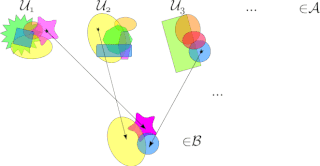
In mathematics, a selection principle is a rule asserting the possibility of obtaining mathematically significant objects by selecting elements from given sequences of sets. The theory of selection principles studies these principles and their relations to other mathematical properties. Selection principles mainly describe covering properties, measure- and category-theoretic properties, and local properties in topological spaces, especially function spaces. Often, the characterization of a mathematical property using a selection principle is a nontrivial task leading to new insights on the characterized property.
In mathematics, a -space is a topological space that satisfies a certain a basic selection principle. An infinite cover of a topological space is an -cover if every finite subset of this space is contained in some member of the cover, and the whole space is not a member the cover. A cover of a topological space is a -cover if every point of this space belongs to all but finitely many members of this cover. A -space is a space in which every open -cover contains a -cover.


















