As a subfield in artificial intelligence, diagnosis is concerned with the development of algorithms and techniques that are able to determine whether the behaviour of a system is correct. If the system is not functioning correctly, the algorithm should be able to determine, as accurately as possible, which part of the system is failing, and which kind of fault it is facing. The computation is based on observations, which provide information on the current behaviour.
The expression diagnosis also refers to the answer of the question of whether the system is malfunctioning or not, and to the process of computing the answer. This word comes from the medical context where a diagnosis is the process of identifying a disease by its symptoms.
Example
An example of diagnosis is the process of a garage mechanic with an automobile. The mechanic will first try to detect any abnormal behavior based on the observations on the car and his knowledge of this type of vehicle. If he finds out that the behavior is abnormal, the mechanic will try to refine his diagnosis by using new observations and possibly testing the system, until he discovers the faulty component; the mechanic plays an important role in the vehicle diagnosis.
Expert diagnosis
The expert diagnosis (or diagnosis by expert system) is based on experience with the system. Using this experience, a mapping is built that efficiently associates the observations to the corresponding diagnoses.
The experience can be provided:
By a human operator. In this case, the human knowledge must be translated into a computer language.
By examples of the system behaviour. In this case, the examples must be classified as correct or faulty (and, in the latter case, by the type of fault). Machine learning methods are then used to generalize from the examples.
The main drawbacks of these methods are:
The difficulty acquiring the expertise. The expertise is typically only available after a long period of use of the system (or similar systems). Thus, these methods are unsuitable for safety- or mission-critical systems (such as a nuclear power plant, or a robot operating in space). Moreover, the acquired expert knowledge can never be guaranteed to be complete. In case a previously unseen behaviour occurs, leading to an unexpected observation, it is impossible to give a diagnosis.
The complexity of the learning. The off-line process of building an expert system can require a large amount of time and computer memory.
The size of the final expert system. As the expert system aims to map any observation to a diagnosis, it will in some cases require a huge amount of storage space.
The lack of robustness. If even a small modification is made on the system, the process of constructing the expert system must be repeated.
A slightly different approach is to build an expert system from a model of the system rather than directly from an expertise. An example is the computation of a diagnoser for the diagnosis of discrete event systems. This approach can be seen as model-based, but it benefits from some advantages and suffers some drawbacks of the expert system approach.
Model-based diagnosis
Model-based diagnosis is an example of abductive reasoning using a model of the system. In general, it works as follows:
Principle of the model-based diagnosis
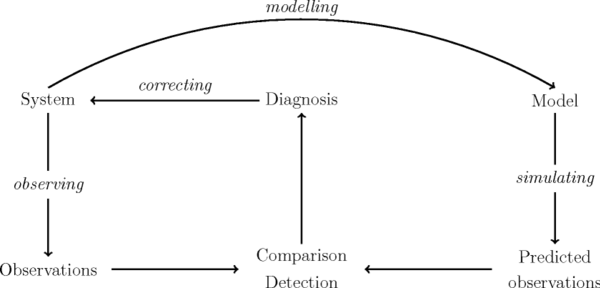
We have a model that describes the behaviour of the system (or artefact). The model is an abstraction of the behaviour of the system and can be incomplete. In particular, the faulty behaviour is generally little-known, and the faulty model may thus not be represented. Given observations of the system, the diagnosis system simulates the system using the model, and compares the observations actually made to the observations predicted by the simulation.
The modelling can be simplified by the following rules (where is the Abnormal predicate):
(fault model)
The semantics of these formulae is the following: if the behaviour of the system is not abnormal (i.e. if it is normal), then the internal (unobservable) behaviour will be and the observable behaviour . Otherwise, the internal behaviour will be and the observable behaviour . Given the observations , the problem is to determine whether the system behaviour is normal or not ( or ). This is an example of abductive reasoning.
Diagnosability
A system is said to be diagnosable if whatever the behavior of the system, we will be able to determine without ambiguity a unique diagnosis.
The problem of diagnosability is very important when designing a system because on one hand one may want to reduce the number of sensors to reduce the cost, and on the other hand one may want to increase the number of sensors to increase the probability of detecting a faulty behavior.
Several algorithms for dealing with these problems exist. One class of algorithms answers the question whether a system is diagnosable; another class looks for sets of sensors that make the system diagnosable, and optionally comply to criteria such as cost optimization.
The diagnosability of a system is generally computed from the model of the system. In applications using model-based diagnosis, such a model is already present and doesn't need to be built from scratch.
Bibliography
Hamscher, W.; L. Console; J. de Kleer (1992). Readings in model-based diagnosis. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc. ISBN1-55860-249-6.
Pattern recognition is the task of assigning a class to an observation based on patterns extracted from data. While similar, pattern recognition (PR) is not to be confused with pattern machines (PM) which may possess (PR) capabilities but their primary function is to distinguish and create emergent patterns. PR has applications in statistical data analysis, signal processing, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. Pattern recognition has its origins in statistics and engineering; some modern approaches to pattern recognition include the use of machine learning, due to the increased availability of big data and a new abundance of processing power.
In statistics, an outlier is a data point that differs significantly from other observations. An outlier may be due to a variability in the measurement, an indication of novel data, or it may be the result of experimental error; the latter are sometimes excluded from the data set. An outlier can be an indication of exciting possibility, but can also cause serious problems in statistical analyses.
A Bayesian network is a probabilistic graphical model that represents a set of variables and their conditional dependencies via a directed acyclic graph (DAG). While it is one of several forms of causal notation, causal networks are special cases of Bayesian networks. Bayesian networks are ideal for taking an event that occurred and predicting the likelihood that any one of several possible known causes was the contributing factor. For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases.
In computer science and operations research, the ant colony optimization algorithm (ACO) is a probabilistic technique for solving computational problems that can be reduced to finding good paths through graphs. Artificial ants represent multi-agent methods inspired by the behavior of real ants. The pheromone-based communication of biological ants is often the predominant paradigm used. Combinations of artificial ants and local search algorithms have become a preferred method for numerous optimization tasks involving some sort of graph, e.g., vehicle routing and internet routing.
Swarm intelligence (SI) is the collective behavior of decentralized, self-organized systems, natural or artificial. The concept is employed in work on artificial intelligence. The expression was introduced by Gerardo Beni and Jing Wang in 1989, in the context of cellular robotic systems.
Default logic is a non-monotonic logic proposed by Raymond Reiter to formalize reasoning with default assumptions.
Belief revision is the process of changing beliefs to take into account a new piece of information. The logical formalization of belief revision is researched in philosophy, in databases, and in artificial intelligence for the design of rational agents.
Answer set programming (ASP) is a form of declarative programming oriented towards difficult search problems. It is based on the stable model semantics of logic programming. In ASP, search problems are reduced to computing stable models, and answer set solvers—programs for generating stable models—are used to perform search. The computational process employed in the design of many answer set solvers is an enhancement of the DPLL algorithm and, in principle, it always terminates.
Circumscription is a non-monotonic logic created by John McCarthy to formalize the common sense assumption that things are as expected unless otherwise specified. Circumscription was later used by McCarthy in an attempt to solve the frame problem. To implement circumscription in its initial formulation, McCarthy augmented first-order logic to allow the minimization of the extension of some predicates, where the extension of a predicate is the set of tuples of values the predicate is true on. This minimization is similar to the closed-world assumption that what is not known to be true is false.
In artificial intelligence, model-based reasoning refers to an inference method used in expert systems based on a model of the physical world. With this approach, the main focus of application development is developing the model. Then at run time, an "engine" combines this model knowledge with observed data to derive conclusions such as a diagnosis or a prediction.
INTERNIST-I was a broad-based computer-assisted decision tree developed in the early 1970s at the University of Pittsburgh as an educational experiment. The INTERNIST system was designed primarily by AI pioneer and Computer Scientist Harry Pople to capture the diagnostic expertise of Jack D. Myers, chairman of internal medicine in the University of Pittsburgh School of Medicine. The Division of Research Resources and the National Library of Medicine funded INTERNIST-I. Other major collaborators on the project included Randolph A. Miller and Kenneth "Casey" Quayle, who did much of the implementation of INTERNIST and its successors.
A partially observable Markov decision process (POMDP) is a generalization of a Markov decision process (MDP). A POMDP models an agent decision process in which it is assumed that the system dynamics are determined by an MDP, but the agent cannot directly observe the underlying state. Instead, it must maintain a sensor model and the underlying MDP. Unlike the policy function in MDP which maps the underlying states to the actions, POMDP's policy is a mapping from the history of observations to the actions.
Logic Theorist is a computer program written in 1956 by Allen Newell, Herbert A. Simon, and Cliff Shaw. It was the first program deliberately engineered to perform automated reasoning, and has been described as "the first artificial intelligence program". Logic Theorist proved 38 of the first 52 theorems in chapter two of Whitehead and Bertrand Russell's Principia Mathematica, and found new and shorter proofs for some of them.
Activity recognition aims to recognize the actions and goals of one or more agents from a series of observations on the agents' actions and the environmental conditions. Since the 1980s, this research field has captured the attention of several computer science communities due to its strength in providing personalized support for many different applications and its connection to many different fields of study such as medicine, human-computer interaction, or sociology.
Fault detection, isolation, and recovery (FDIR) is a subfield of control engineering which concerns itself with monitoring a system, identifying when a fault has occurred, and pinpointing the type of fault and its location. Two approaches can be distinguished: A direct pattern recognition of sensor readings that indicate a fault and an analysis of the discrepancy between the sensor readings and expected values, derived from some model. In the latter case, it is typical that a fault is said to be detected if the discrepancy or residual goes above a certain threshold. It is then the task of fault isolation to categorize the type of fault and its location in the machinery. Fault detection and isolation (FDI) techniques can be broadly classified into two categories. These include model-based FDI and signal processing based FDI.
The Brooks–Iyengar algorithm or FuseCPA Algorithm or Brooks–Iyengar hybrid algorithm is a distributed algorithm that improves both the precision and accuracy of the interval measurements taken by a distributed sensor network, even in the presence of faulty sensors. The sensor network does this by exchanging the measured value and accuracy value at every node with every other node, and computes the accuracy range and a measured value for the whole network from all of the values collected. Even if some of the data from some of the sensors is faulty, the sensor network will not malfunction. The algorithm is fault-tolerant and distributed. It could also be used as a sensor fusion method. The precision and accuracy bound of this algorithm have been proved in 2016.
Thompson sampling, named after William R. Thompson, is a heuristic for choosing actions that address the exploration-exploitation dilemma in the multi-armed bandit problem. It consists of choosing the action that maximizes the expected reward with respect to a randomly drawn belief.
This glossary of artificial intelligence is a list of definitions of terms and concepts relevant to the study of artificial intelligence (AI), its subdisciplines, and related fields. Related glossaries include Glossary of computer science, Glossary of robotics, and Glossary of machine vision.
Artificial intelligence in healthcare is the application of artificial intelligence (AI) to copy or exceed human cognition in the analysis, presentation, and understanding of complex medical and healthcare data. It can augment and exceed human capabilities by providing better ways to diagnose, treat, or prevent disease. Using AI in healthcare has the potential to improve predicting, diagnosing, and treating diseases. Through machine learning algorithms and deep learning, AI can analyze large sets of clinical data and electronic health records, and can help to diagnose diseases more quickly and accurately. In addition, AI is becoming more relevant in bringing culturally competent healthcare practices to the industry.
Imitation learning is a paradigm in reinforcement learning, where an agent learns to perform a task by supervised learning from expert demonstrations. It is also called learning from demonstration and apprenticeship learning.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.