
In probability theory, the expected value is a generalization of the weighted average. Informally, the expected value is the arithmetic mean of the possible values a random variable can take, weighted by the probability of those outcomes. Since it is obtained through arithmetic, the expected value sometimes may not even be included in the sample data set; it is not the value you would "expect" to get in reality.

In information theory, the entropy of a random variable is the average level of "information", "surprise", or "uncertainty" inherent to the variable's possible outcomes. Given a discrete random variable , which takes values in the alphabet and is distributed according to , the entropy is
In probability theory and statistics, a probability distribution is the mathematical function that gives the probabilities of occurrence of different possible outcomes for an experiment. It is a mathematical description of a random phenomenon in terms of its sample space and the probabilities of events.
A random variable is a mathematical formalization of a quantity or object which depends on random events. The term 'random variable' in its mathematical definition refers to neither randomness nor variability but instead is a mathematical function in which
In probability theory, the central limit theorem (CLT) states that, under appropriate conditions, the distribution of a normalized version of the sample mean converges to a standard normal distribution. This holds even if the original variables themselves are not normally distributed. There are several versions of the CLT, each applying in the context of different conditions.

In probability theory, a probability density function (PDF), density function, or density of an absolutely continuous random variable, is a function whose value at any given sample in the sample space can be interpreted as providing a relative likelihood that the value of the random variable would be equal to that sample. Probability density is the probability per unit length, in other words, while the absolute likelihood for a continuous random variable to take on any particular value is 0, the value of the PDF at two different samples can be used to infer, in any particular draw of the random variable, how much more likely it is that the random variable would be close to one sample compared to the other sample.
A pseudorandom number generator (PRNG), also known as a deterministic random bit generator (DRBG), is an algorithm for generating a sequence of numbers whose properties approximate the properties of sequences of random numbers. The PRNG-generated sequence is not truly random, because it is completely determined by an initial value, called the PRNG's seed. Although sequences that are closer to truly random can be generated using hardware random number generators, pseudorandom number generators are important in practice for their speed in number generation and their reproducibility.
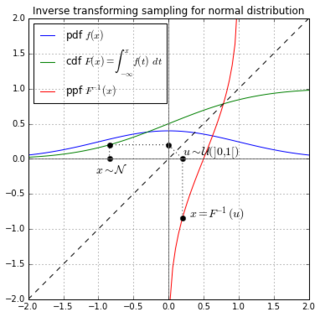
Inverse transform sampling is a basic method for pseudo-random number sampling, i.e., for generating sample numbers at random from any probability distribution given its cumulative distribution function.
In probability theory, there exist several different notions of convergence of sequences of random variables, including convergence in probability, convergence in distribution, and almost sure convergence. The different notions of convergence capture different properties about the sequence, with some notions of convergence being stronger than others. For example, convergence in distribution tells us about the limit distribution of a sequence of random variables. This is a weaker notion than convergence in probability, which tells us about the value a random variable will take, rather than just the distribution.
In probability theory, the law of large numbers (LLN) is a mathematical theorem that states that the average of the results obtained from a large number of independent and identical random samples converges to the true value, if it exists. More formally, the LLN states that given a sample of independent and identically distributed values, the sample mean converges to the true mean.
In numerical analysis and computational statistics, rejection sampling is a basic technique used to generate observations from a distribution. It is also commonly called the acceptance-rejection method or "accept-reject algorithm" and is a type of exact simulation method. The method works for any distribution in with a density.
Quantum statistical mechanics is statistical mechanics applied to quantum mechanical systems. In quantum mechanics a statistical ensemble is described by a density operator S, which is a non-negative, self-adjoint, trace-class operator of trace 1 on the Hilbert space H describing the quantum system. This can be shown under various mathematical formalisms for quantum mechanics.
In statistics, binomial regression is a regression analysis technique in which the response has a binomial distribution: it is the number of successes in a series of independent Bernoulli trials, where each trial has probability of success . In binomial regression, the probability of a success is related to explanatory variables: the corresponding concept in ordinary regression is to relate the mean value of the unobserved response to explanatory variables.
In statistics, probability theory, and information theory, a statistical distance quantifies the distance between two statistical objects, which can be two random variables, or two probability distributions or samples, or the distance can be between an individual sample point and a population or a wider sample of points.
In probability theory, an empirical measure is a random measure arising from a particular realization of a sequence of random variables. The precise definition is found below. Empirical measures are relevant to mathematical statistics.
In probability theory and statistics, the Dirichlet-multinomial distribution is a family of discrete multivariate probability distributions on a finite support of non-negative integers. It is also called the Dirichlet compound multinomial distribution (DCM) or multivariate Pólya distribution. It is a compound probability distribution, where a probability vector p is drawn from a Dirichlet distribution with parameter vector , and an observation drawn from a multinomial distribution with probability vector p and number of trials n. The Dirichlet parameter vector captures the prior belief about the situation and can be seen as a pseudocount: observations of each outcome that occur before the actual data is collected. The compounding corresponds to a Pólya urn scheme. It is frequently encountered in Bayesian statistics, machine learning, empirical Bayes methods and classical statistics as an overdispersed multinomial distribution.
In probability theory and statistics, a categorical distribution is a discrete probability distribution that describes the possible results of a random variable that can take on one of K possible categories, with the probability of each category separately specified. There is no innate underlying ordering of these outcomes, but numerical labels are often attached for convenience in describing the distribution,. The K-dimensional categorical distribution is the most general distribution over a K-way event; any other discrete distribution over a size-K sample space is a special case. The parameters specifying the probabilities of each possible outcome are constrained only by the fact that each must be in the range 0 to 1, and all must sum to 1.
In cryptography, learning with errors (LWE) is a mathematical problem that is widely used to create secure encryption algorithms. It is based on the idea of representing secret information as a set of equations with errors. In other words, LWE is a way to hide the value of a secret by introducing noise to it. In more technical terms, it refers to the computational problem of inferring a linear -ary function over a finite ring from given samples some of which may be erroneous. The LWE problem is conjectured to be hard to solve, and thus to be useful in cryptography.
The convolution/sum of probability distributions arises in probability theory and statistics as the operation in terms of probability distributions that corresponds to the addition of independent random variables and, by extension, to forming linear combinations of random variables. The operation here is a special case of convolution in the context of probability distributions.

A hyperbolic geometric graph (HGG) or hyperbolic geometric network (HGN) is a special type of spatial network where (1) latent coordinates of nodes are sprinkled according to a probability density function into a hyperbolic space of constant negative curvature and (2) an edge between two nodes is present if they are close according to a function of the metric (typically either a Heaviside step function resulting in deterministic connections between vertices closer than a certain threshold distance, or a decaying function of hyperbolic distance yielding the connection probability). A HGG generalizes a random geometric graph (RGG) whose embedding space is Euclidean.






