
Probability theory or probability calculus is the branch of mathematics concerned with probability. Although there are several different probability interpretations, probability theory treats the concept in a rigorous mathematical manner by expressing it through a set of axioms. Typically these axioms formalise probability in terms of a probability space, which assigns a measure taking values between 0 and 1, termed the probability measure, to a set of outcomes called the sample space. Any specified subset of the sample space is called an event.
In mathematical analysis and in probability theory, a σ-algebra on a set X is a nonempty collection Σ of subsets of X closed under complement, countable unions, and countable intersections. The ordered pair is called a measurable space.

In probability theory, the central limit theorem (CLT) states that, under appropriate conditions, the distribution of a normalized version of the sample mean converges to a standard normal distribution. This holds even if the original variables themselves are not normally distributed. There are several versions of the CLT, each applying in the context of different conditions.
In probability theory, there exist several different notions of convergence of sequences of random variables, including convergence in probability, convergence in distribution, and almost sure convergence. The different notions of convergence capture different properties about the sequence, with some notions of convergence being stronger than others. For example, convergence in distribution tells us about the limit distribution of a sequence of random variables. This is a weaker notion than convergence in probability, which tells us about the value a random variable will take, rather than just the distribution.
Distributions, also known as Schwartz distributions or generalized functions, are objects that generalize the classical notion of functions in mathematical analysis. Distributions make it possible to differentiate functions whose derivatives do not exist in the classical sense. In particular, any locally integrable function has a distributional derivative.
Vapnik–Chervonenkis theory was developed during 1960–1990 by Vladimir Vapnik and Alexey Chervonenkis. The theory is a form of computational learning theory, which attempts to explain the learning process from a statistical point of view.
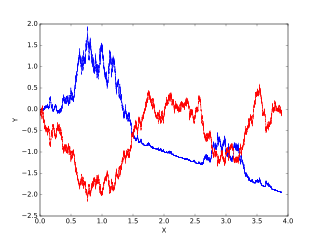
Itô calculus, named after Kiyosi Itô, extends the methods of calculus to stochastic processes such as Brownian motion. It has important applications in mathematical finance and stochastic differential equations.

In statistics, an empirical distribution function is the distribution function associated with the empirical measure of a sample. This cumulative distribution function is a step function that jumps up by 1/n at each of the n data points. Its value at any specified value of the measured variable is the fraction of observations of the measured variable that are less than or equal to the specified value.
In probability theory, an empirical process is a stochastic process that characterizes the deviation of the empirical distribution function from its expectation. In mean field theory, limit theorems are considered and generalise the central limit theorem for empirical measures. Applications of the theory of empirical processes arise in non-parametric statistics.
In the theory of probability, the Glivenko–Cantelli theorem, named after Valery Ivanovich Glivenko and Francesco Paolo Cantelli, describes the asymptotic behaviour of the empirical distribution function as the number of independent and identically distributed observations grows. Specifically, the empirical distribution function converges uniformly to the true distribution function almost surely.

In probability theory, Donsker's theorem, named after Monroe D. Donsker, is a functional extension of the central limit theorem for empirical distribution functions. Specifically, the theorem states that an appropriately centered and scaled version of the empirical distribution function converges to a Gaussian process.
In statistics, M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares and maximum likelihood estimation are special cases of M-estimators. The definition of M-estimators was motivated by robust statistics, which contributed new types of M-estimators. However, M-estimators are not inherently robust, as is clear from the fact that they include maximum likelihood estimators, which are in general not robust. The statistical procedure of evaluating an M-estimator on a data set is called M-estimation. The "M" initial stands for "maximum likelihood-type".
In probability theory, an empirical measure is a random measure arising from a particular realization of a sequence of random variables. The precise definition is found below. Empirical measures are relevant to mathematical statistics.
Bootstrapping is a procedure for estimating the distribution of an estimator by resampling one's data or a model estimated from the data. Bootstrapping assigns measures of accuracy to sample estimates. This technique allows estimation of the sampling distribution of almost any statistic using random sampling methods.
An -superprocess, , within mathematics probability theory is a stochastic process on that is usually constructed as a special limit of near-critical branching diffusions.
Self-similar processes are stochastic processes satisfying a mathematically precise version of the self-similarity property. Several related properties have this name, and some are defined here.
In probability theory, the Komlós–Major–Tusnády approximation refers to one of the two strong embedding theorems: 1) approximation of random walk by a standard Brownian motion constructed on the same probability space, and 2) an approximation of the empirical process by a Brownian bridge constructed on the same probability space. It is named after Hungarian mathematicians János Komlós, Gábor Tusnády, and Péter Major, who proved it in 1975.
In Bayesian inference, the Bernstein–von Mises theorem provides the basis for using Bayesian credible sets for confidence statements in parametric models. It states that under some conditions, a posterior distribution converges in total variation distance to a multivariate normal distribution centered at the maximum likelihood estimator with covariance matrix given by , where is the true population parameter and is the Fisher information matrix at the true population parameter value:
In probability theory and statistics, the Dirichlet process (DP) is one of the most popular Bayesian nonparametric models. It was introduced by Thomas Ferguson as a prior over probability distributions.
In statistical learning theory, a learnable function class is a set of functions for which an algorithm can be devised to asymptotically minimize the expected risk, uniformly over all probability distributions. The concept of learnable classes are closely related to regularization in machine learning, and provides large sample justifications for certain learning algorithms.












