Related Research Articles

Metabolomics is the scientific study of chemical processes involving metabolites, the small molecule substrates, intermediates, and products of cell metabolism. Specifically, metabolomics is the "systematic study of the unique chemical fingerprints that specific cellular processes leave behind", the study of their small-molecule metabolite profiles. The metabolome represents the complete set of metabolites in a biological cell, tissue, organ, or organism, which are the end products of cellular processes. Messenger RNA (mRNA), gene expression data, and proteomic analyses reveal the set of gene products being produced in the cell, data that represents one aspect of cellular function. Conversely, metabolic profiling can give an instantaneous snapshot of the physiology of that cell, and thus, metabolomics provides a direct "functional readout of the physiological state" of an organism. There are indeed quantifiable correlations between the metabolome and the other cellular ensembles, which can be used to predict metabolite abundances in biological samples from, for example mRNA abundances. One of the ultimate challenges of systems biology is to integrate metabolomics with all other -omics information to provide a better understanding of cellular biology.

The metabolome refers to the complete set of small-molecule chemicals found within a biological sample. The biological sample can be a cell, a cellular organelle, an organ, a tissue, a tissue extract, a biofluid or an entire organism. The small molecule chemicals found in a given metabolome may include both endogenous metabolites that are naturally produced by an organism as well as exogenous chemicals that are not naturally produced by an organism.
BRENDA is the world's most comprehensive online database for functional, biochemical and molecular biological data on enzymes, metabolites and metabolic pathways. It contains data on the properties, function and significance of all enzymes classified by the Enzyme Commission of the International Union of Biochemistry and Molecular Biology (IUBMB) classified enzymes. As ELIXIR Core Data Resource, BRENDA is considered a data resource of critical importance to the international life sciences research community. The database compiles a representative overview of enzymes and metabolites using current research data from primary scientific literature and thus serves the purpose of facilitating information retrieval for researchers. BRENDA is subject to the terms of the Creative Commons license, is accessible worldwide and can be used free of charge. As one of the digital resources of the Leibniz Institute DSMZ-German Collection of Microorganisms and Cell Cultures, BRENDA is part of the integrated biodata infrastructure DSMZ Digital Diversity.
Metabolic network modelling, also known as metabolic network reconstruction or metabolic pathway analysis, allows for an in-depth insight into the molecular mechanisms of a particular organism. In particular, these models correlate the genome with molecular physiology. A reconstruction breaks down metabolic pathways into their respective reactions and enzymes, and analyzes them within the perspective of the entire network. In simplified terms, a reconstruction collects all of the relevant metabolic information of an organism and compiles it in a mathematical model. Validation and analysis of reconstructions can allow identification of key features of metabolism such as growth yield, resource distribution, network robustness, and gene essentiality. This knowledge can then be applied to create novel biotechnology.
The DrugBank database is a comprehensive, freely accessible, online database containing information on drugs and drug targets created and maintained by the University of Alberta and The Metabolomics Innovation Centre located in Alberta, Canada. As both a bioinformatics and a cheminformatics resource, DrugBank combines detailed drug data with comprehensive drug target information. DrugBank has used content from Wikipedia; Wikipedia also often links to Drugbank, posing potential circular reporting issues.
KEGG is a collection of databases dealing with genomes, biological pathways, diseases, drugs, and chemical substances. KEGG is utilized for bioinformatics research and education, including data analysis in genomics, metagenomics, metabolomics and other omics studies, modeling and simulation in systems biology, and translational research in drug development.
ChemSpider is a freely accessible online database of chemicals owned by the Royal Society of Chemistry. It contains information on more than 100 million molecules from over 270 data sources, each of them receiving a unique identifier called ChemSpider Identifier.
The Re-referenced Protein Chemical shift Database (RefDB) is an NMR spectroscopy database of carefully corrected or re-referenced chemical shifts, derived from the BioMagResBank (BMRB). The database was assembled by using a structure-based chemical shift calculation program to calculate expected protein (1)H, (13)C and (15)N chemical shifts from X-ray or NMR coordinate data of previously assigned proteins reported in the BMRB. The comparison is automatically performed by a program called SHIFTCOR. The RefDB database currently provides reference-corrected chemical shift data on more than 2000 assigned peptides and proteins. Data from the database indicates that nearly 25% of BMRB entries with (13)C protein assignments and 27% of BMRB entries with (15)N protein assignments require significant chemical shift reference readjustments. Additionally, nearly 40% of protein entries deposited in the BioMagResBank appear to have at least one assignment error. Users may download, search or browse the database through a number of methods available through the RefDB website. RefDB provides a standard chemical shift resource for biomolecular NMR spectroscopists, wishing to derive or compute chemical shift trends in peptides and proteins.
The Human Metabolome Database (HMDB) is a comprehensive, high-quality, freely accessible, online database of small molecule metabolites found in the human body. It has been created by the Human Metabolome Project funded by Genome Canada and is one of the first dedicated metabolomics databases. The HMDB facilitates human metabolomics research, including the identification and characterization of human metabolites using NMR spectroscopy, GC-MS spectrometry and LC/MS spectrometry. To aid in this discovery process, the HMDB contains three kinds of data: 1) chemical data, 2) clinical data, and 3) molecular biology/biochemistry data (Fig. 1–3). The chemical data includes 41,514 metabolite structures with detailed descriptions along with nearly 10,000 NMR, GC-MS and LC/MS spectra.

The Toxin and Toxin-Target Database (T3DB), also known as the Toxic Exposome Database, is a freely accessible online database of common substances that are toxic to humans, along with their protein, DNA or organ targets. The database currently houses nearly 3,700 toxic compounds or poisons described by nearly 42,000 synonyms. This list includes various groups of toxins, including common pollutants, pesticides, drugs, food toxins, household and industrial/workplace toxins, cigarette toxins, and uremic toxins. These toxic substances are linked to 2,086 corresponding protein/DNA target records. In total there are 42,433 toxic substance-toxin target associations. Each toxic compound record (ToxCard) in T3DB contains nearly 100 data fields and holds information such as chemical properties and descriptors, mechanisms of action, toxicity or lethal dose values, molecular and cellular interactions, medical information, NMR an MS spectra, and up- and down-regulated genes. This information has been extracted from over 18,000 sources, which include other databases, government documents, books, and scientific literature.
The Small Molecule Pathway Database (SMPDB) is a comprehensive, high-quality, freely accessible, online database containing more than 600 small molecule (i.e. metabolic) pathways found in humans. SMPDB is designed specifically to support pathway elucidation and pathway discovery in metabolomics, transcriptomics, proteomics and systems biology. It is able to do so, in part, by providing colorful, detailed, fully searchable, hyperlinked diagrams of five types of small molecule pathways: 1) general human metabolic pathways; 2) human metabolic disease pathways; 3) human metabolite signaling pathways; 4) drug-action pathways and 5) drug metabolism pathways. SMPDB pathways may be navigated, viewed and zoomed interactively using a Google Maps-like interface. All SMPDB pathways include information on the relevant organs, subcellular compartments, protein cofactors, protein locations, metabolite locations, chemical structures and protein quaternary structures (Fig. 1). Each small molecule in SMPDB is hyperlinked to detailed descriptions contained in the HMDB or DrugBank and each protein or enzyme complex is hyperlinked to UniProt. Additionally, all SMPDB pathways are accompanied with detailed descriptions and references, providing an overview of the pathway, condition or processes depicted in each diagram. Users can browse the SMPDB (Fig. 2) or search its contents by text searching (Fig. 3), sequence searching, or chemical structure searching. More powerful queries are also possible including searching with lists of gene or protein names, drug names, metabolite names, GenBank IDs, Swiss-Prot IDs, Agilent or Affymetrix microarray IDs. These queries will produce lists of matching pathways and highlight the matching molecules on each of the pathway diagrams. Gene, metabolite and protein concentration data can also be visualized through SMPDB's mapping interface.
MetaboAnalyst is a set of online tools for metabolomic data analysis and interpretation, created by members of the Wishart Research Group at the University of Alberta. It was first released in May 2009 and version 2.0 was released in January 2012. MetaboAnalyst provides a variety of analysis methods that have been tailored for metabolomic data. These methods include metabolomic data processing, normalization, multivariate statistical analysis, and data annotation. The current version is focused on biomarker discovery and classification.
Pharmacometabolomics, also known as pharmacometabonomics, is a field which stems from metabolomics, the quantification and analysis of metabolites produced by the body. It refers to the direct measurement of metabolites in an individual's bodily fluids, in order to predict or evaluate the metabolism of pharmaceutical compounds, and to better understand the pharmacokinetic profile of a drug. Alternatively, pharmacometabolomics can be applied to measure metabolite levels following the administration of a pharmaceutical compound, in order to monitor the effects of the compound on certain metabolic pathways(pharmacodynamics). This provides detailed mapping of drug effects on metabolism and the pathways that are implicated in mechanism of variation of response to treatment. In addition, the metabolic profile of an individual at baseline (metabotype) provides information about how individuals respond to treatment and highlights heterogeneity within a disease state. All three approaches require the quantification of metabolites found in bodily fluids and tissue, such as blood or urine, and can be used in the assessment of pharmaceutical treatment options for numerous disease states.
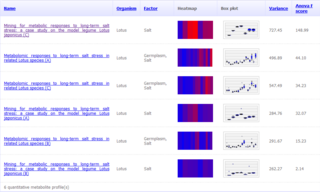
The Golm Metabolome Database (GMD) is a gas chromatography (GC) – mass spectrometry (MS) reference library dedicated to metabolite profiling experiments and comprises mass spectral and retention index (RI) information for non-annotated mass spectral tags together with data of a multitude of already identified metabolites and reference substances. The GMD is hosted at the Max Planck Institute of Molecular Plant Physiology in Golm district of Potsdam, Germany.
The Yeast Metabolome Database (YMDB) is a comprehensive, high-quality, freely accessible, online database of small molecule metabolites found in or produced by Saccharomyces cerevisiae. The YMDB was designed to facilitate yeast metabolomics research, specifically in the areas of general fermentation as well as wine, beer and fermented food analysis. YMDB supports the identification and characterization of yeast metabolites using NMR spectroscopy, GC-MS spectrometry and Liquid chromatography–mass spectrometry. The YMDB contains two kinds of data: 1) chemical data and 2) molecular biology/biochemistry data. The chemical data includes 2027 metabolite structures with detailed metabolite descriptions along with nearly 4000 NMR, GC-MS and LC/MS spectra.
The Serum Metabolome database is a free web database about small molecule metabolites found in human serum and their concentration values. The database includes chemical data, clinical data and molecular/biochemistry data from literature and experiment. This database also references many other databases, such as KEGG, PubChem, MetaCyc, ChEBI, PDB, Swiss-Prot, GenBank, and Human Metabolome Database (HMDB).
The CyberCell Database (CCDB) is a freely available, web-accessible database that provides quantitative genomic, proteomic as well metabolomic data on Escherichia coli. Escherichia coli is perhaps the best-studied bacterium on the planet and has been the organism of choice for several international efforts in cell simulation. These cell simulation efforts require up-to-date web-accessible resources that provide comprehensive, non-redundant, and quantitative data on this bacterium. The intent of CCDB is to facilitate the collection, revision, coordination and storage of the key information required for in silico E. coli simulation.

MetaboLights is a data repository founded in 2012 for cross-species and cross-platform metabolomic studies that provides primary research data and meta data for metabolomic studies as well as a knowledge base for properties of individual metabolites. The database is maintained by the European Bioinformatics Institute (EMBL-EBI) and the development is funded by Biotechnology and Biological Sciences Research Council (BBSRC). As of July 2018, the MetaboLights browse functionality consists of 383 studies, two analytical platforms, NMR spectroscopy and mass spectrometry.
The Biological Magnetic Resonance Data Bank is an open access repository of nuclear magnetic resonance (NMR) spectroscopic data from peptides, proteins, nucleic acids and other biologically relevant molecules. The database is operated by the University of Wisconsin–Madison and is supported by the National Library of Medicine. The BMRB is part of the Research Collaboratory for Structural Bioinformatics and, since 2006, it is a partner in the Worldwide Protein Data Bank (wwPDB). The repository accepts NMR spectral data from laboratories around the world and, once the data is validated, it is available online at the BMRB website. The database has also an ftp site, where data can be downloaded in the bulk. The BMRB has two mirror sites, one at the Protein Database Japan (PDBj) at Osaka University and one at the Magnetic Resonance Research Center (CERM) at the University of Florence in Italy. The site at Japan accepts and processes data depositions.
David S. Wishart is a Canadian researcher in metabolomics and a Distinguished University Professor in the Department of Biological Sciences and the Department of Computing Science at the University of Alberta. Wishart also holds cross appointments in the Faculty of Pharmacy and Pharmaceutical Sciences and the Department of Laboratory Medicine and Pathology in the Faculty of Medicine and Dentistry. Additionally, Wishart holds a joint appointment in metabolomics at the Pacific Northwest National Laboratory in Richland, Washington. Wishart is well known for his pioneering contributions to the fields of protein NMR spectroscopy, bioinformatics, cheminformatics and metabolomics. In 2011, Wishart founded the Metabolomics Innovation Centre (TMIC), which is Canada's national metabolomics laboratory.
References
- 1 2 3 Guo, AC; Jewison T; Wilson M; Liu Y; Knox C; Djoumbou Y; Lo P; Mandal R; Krishnamurthy R; Wishart DS (Jan 2013). "ECMDB: the E. coli Metabolome Database". Nucleic Acids Res. 41 (Database issue): D625–30. doi:10.1093/nar/gks992. PMC 3531117 . PMID 23109553.