
Phonetics is a branch of linguistics that studies how humans produce and perceive sounds, or in the case of sign languages, the equivalent aspects of sign. Linguists who specialize in studying the physical properties of speech are phoneticians. The field of phonetics is traditionally divided into three sub-disciplines based on the research questions involved such as how humans plan and execute movements to produce speech, how various movements affect the properties of the resulting sound, or how humans convert sound waves to linguistic information. Traditionally, the minimal linguistic unit of phonetics is the phone—a speech sound in a language which differs from the phonological unit of phoneme; the phoneme is an abstract categorization of phones, and it is also defined as the smallest unit that discerns meaning between sounds in any given language.

In phonetics, voice onset time (VOT) is a feature of the production of stop consonants. It is defined as the length of time that passes between the release of a stop consonant and the onset of voicing, the vibration of the vocal folds, or, according to other authors, periodicity. Some authors allow negative values to mark voicing that begins during the period of articulatory closure for the consonant and continues in the release, for those unaspirated voiced stops in which there is no voicing present at the instant of articulatory closure.
J. A. Scott Kelso is an American neuroscientist, and Professor of Complex Systems and Brain Sciences, Professor of Psychology, Biological Sciences and Biomedical Science at Florida Atlantic University (FAU) in Boca Raton, Florida and The University of Ulster in Derry, N. Ireland.
Speech perception is the process by which the sounds of language are heard, interpreted, and understood. The study of speech perception is closely linked to the fields of phonology and phonetics in linguistics and cognitive psychology and perception in psychology. Research in speech perception seeks to understand how human listeners recognize speech sounds and use this information to understand spoken language. Speech perception research has applications in building computer systems that can recognize speech, in improving speech recognition for hearing- and language-impaired listeners, and in foreign-language teaching.

Haskins Laboratories, Inc. is an independent 501(c) non-profit corporation, founded in 1935 and located in New Haven, Connecticut, since 1970. Haskins has formal affiliation agreements with both Yale University and the University of Connecticut; it remains fully independent, administratively and financially, of both Yale and UConn. Haskins is a multidisciplinary and international community of researchers that conducts basic research on spoken and written language. A guiding perspective of their research is to view speech and language as emerging from biological processes, including those of adaptation, response to stimuli, and conspecific interaction. Haskins Laboratories has a long history of technological and theoretical innovation, from creating systems of rules for speech synthesis and development of an early working prototype of a reading machine for the blind to developing the landmark concept of phonemic awareness as the critical preparation for learning to read an alphabetic writing system.

Philip E. Rubin is an American cognitive scientist, technologist, and science administrator known for raising the visibility of behavioral and cognitive science, neuroscience, and ethical issues related to science, technology, and medicine, at a national level. His research career is noted for his theoretical contributions and pioneering technological developments, starting in the 1970s, related to speech synthesis and speech production, including articulatory synthesis and sinewave synthesis, and their use in studying complex temporal events, particularly understanding the biological bases of speech and language.
Carol Ann Fowler is an American experimental psychologist. She was president and director of research at Haskins Laboratories in New Haven, Connecticut from 1992 to 2008. She is also a professor of psychology at the University of Connecticut and adjunct professor of linguistics and psychology at Yale University. She received her undergraduate degree from Brown University in 1971, her M.A University of Connecticut in 1973 and her Ph.D. in psychology from the University of Connecticut in 1977.
Sinewave synthesis, or sine wave speech, is a technique for synthesizing speech by replacing the formants with pure tone whistles. The first sinewave synthesis program (SWS) for the automatic creation of stimuli for perceptual experiments was developed by Philip Rubin at Haskins Laboratories in the 1970s. This program was subsequently used by Robert Remez, Philip Rubin, David Pisoni, and other colleagues to show that listeners can perceive continuous speech without traditional speech cues, i.e., pitch, stress, and intonation. This work paved the way for a view of speech as a dynamic pattern of trajectories through articulatory-acoustic space.
The pattern playback is an early talking device that was built by Dr. Franklin S. Cooper and his colleagues, including John M. Borst and Caryl Haskins, at Haskins Laboratories in the late 1940s and completed in 1950. There were several different versions of this hardware device. Only one currently survives. The machine converts pictures of the acoustic patterns of speech in the form of a spectrogram back into sound. Using this device, Alvin Liberman, Frank Cooper, and Pierre Delattre were able to discover acoustic cues for the perception of phonetic segments. This research was fundamental to the development of modern techniques of speech synthesis, reading machines for the blind, the study of speech perception and speech recognition, and the development of the motor theory of speech perception.
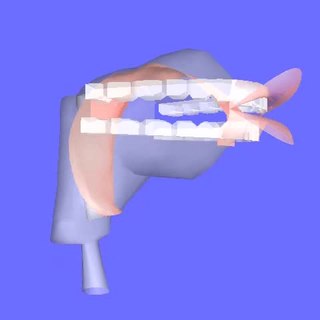
Articulatory synthesis refers to computational techniques for synthesizing speech based on models of the human vocal tract and the articulation processes occurring there. The shape of the vocal tract can be controlled in a number of ways which usually involves modifying the position of the speech articulators, such as the tongue, jaw, and lips. Speech is created by digitally simulating the flow of air through the representation of the vocal tract.
Articulatory phonology is a linguistic theory originally proposed in 1986 by Catherine Browman of Haskins Laboratories and Louis Goldstein of University of Southern California and Haskins. The theory identifies theoretical discrepancies between phonetics and phonology and aims to unify the two by treating them as low- and high-dimensional descriptions of a single system.
Katherine Safford Harris is a noted psychologist and speech scientist. She is Distinguished Professor Emerita in Speech and Hearing at the CUNY Graduate Center and a member of the Board of Directors Archived 2006-03-03 at the Wayback Machine of Haskins Laboratories. She is also the former President of the Acoustical Society of America and Vice President of Haskins Laboratories.
Louis M. Goldstein is an American linguist and cognitive scientist. He was previously a professor and chair of the Department of Linguistics and a professor of psychology at Yale University and is now a professor in the Department of Linguistics at the University of Southern California. He is a senior scientist at Haskins Laboratories in New Haven, Connecticut, and a founding member of the Association for Laboratory Phonology. Notable students of Goldstein include Douglas Whalen and Elizabeth Zsiga.
Catherine Phebe Browman was an American linguist and speech scientist. She received her Ph.D. in linguistics from the University of California, Los Angeles (UCLA) in 1978. Browman was a research scientist at Bell Laboratories in New Jersey (1967–1972). While at Bell Laboratories, she was known for her work on speech synthesis using demisyllables. She later worked as researcher at Haskins Laboratories in New Haven, Connecticut (1982–1998). She was best known for developing, with Louis Goldstein, of the theory of articulatory phonology, a gesture-based approach to phonological and phonetic structure. The theoretical approach is incorporated in a computational model that generates speech from a gesturally-specified lexicon. Browman was made an honorary member of the Association for Laboratory Phonology.
Michael T. Turvey was the Board of Trustees' Distinguished Professor of Experimental Psychology at the University of Connecticut and a Senior Scientist at Haskins Laboratories in New Haven, Connecticut. He is best known for his pioneering work in ecological psychology and in applying the dynamical systems approach to the study of motor behavior. He was the founder of the Center for the Ecological Study of Perception and Action. His research spans a number of areas including: dynamic touch and haptics, interlimb coordination, visual perception and optic flow, postural stability, visual word recognition and speech perception. Along with William Mace and Robert Shaw, he was one of the leading explicators of the ecological psychology of J. J. Gibson. His pioneering work with J. A. Scott Kelso and Peter N. Kugler introduced the physical language of complex systems to the understanding of perception and action. He also helped introduce the ideas of the Russian motor control theorist Nikolai Bernstein and his colleagues to a larger audience. Working with Georgije Lukatela and other colleagues at Haskins Laboratories, he exploited the dual nature of the Serbo-Croatian orthography to help understand word recognition.
The motor theory of speech perception is the hypothesis that people perceive spoken words by identifying the vocal tract gestures with which they are pronounced rather than by identifying the sound patterns that speech generates. It originally claimed that speech perception is done through a specialized module that is innate and human-specific. Though the idea of a module has been qualified in more recent versions of the theory, the idea remains that the role of the speech motor system is not only to produce speech articulations but also to detect them.

Embodied cognition is the concept suggesting that many features of cognition are shaped by the state and capacities of the organism. The cognitive features include a wide spectrum of cognitive functions, such as perception biases, memory recall, comprehension and high-level mental constructs and performance on various cognitive tasks. The bodily aspects involve the motor system, the perceptual system, the bodily interactions with the environment (situatedness), and the assumptions about the world built the functional structure of organism's brain and body.
Neurocomputational speech processing is computer-simulation of speech production and speech perception by referring to the natural neuronal processes of speech production and speech perception, as they occur in the human nervous system. This topic is based on neuroscience and computational neuroscience.
Bernd J. Kröger is a German phonetician and professor at RWTH Aachen University. He is known for his contributions in the field of neurocomputational speech processing, in particular the ACT model.
Ludmilla A. Chistovich was a pioneering linguist and speech scientist who co-founded the Leningrad School of Phonology, together with her husband Valery A. Kozhevnikov.