
In mathematical physics and mathematics, the Pauli matrices are a set of three 2 × 2 complex matrices that are Hermitian, involutory and unitary. Usually indicated by the Greek letter sigma, they are occasionally denoted by tau when used in connection with isospin symmetries.
In continuum mechanics, the infinitesimal strain theory is a mathematical approach to the description of the deformation of a solid body in which the displacements of the material particles are assumed to be much smaller than any relevant dimension of the body; so that its geometry and the constitutive properties of the material at each point of space can be assumed to be unchanged by the deformation.
Linear elasticity is a mathematical model of how solid objects deform and become internally stressed due to prescribed loading conditions. It is a simplification of the more general nonlinear theory of elasticity and a branch of continuum mechanics.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, including the enabling of the user to calculate expectations, covariances using differentiation based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. Sometimes loosely referred to as "the" exponential family, this class of distributions is distinct because they all possess a variety of desirable properties, most importantly the existence of a sufficient statistic.

In statistics, an expectation–maximization (EM) algorithm is an iterative method to find (local) maximum likelihood or maximum a posteriori (MAP) estimates of parameters in statistical models, where the model depends on unobserved latent variables. The EM iteration alternates between performing an expectation (E) step, which creates a function for the expectation of the log-likelihood evaluated using the current estimate for the parameters, and a maximization (M) step, which computes parameters maximizing the expected log-likelihood found on the E step. These parameter-estimates are then used to determine the distribution of the latent variables in the next E step. It can be used, for example, to estimate a mixture of gaussians, or to solve the multiple linear regression problem.
In information geometry, the Fisher information metric is a particular Riemannian metric which can be defined on a smooth statistical manifold, i.e., a smooth manifold whose points are probability measures defined on a common probability space. It can be used to calculate the informational difference between measurements.
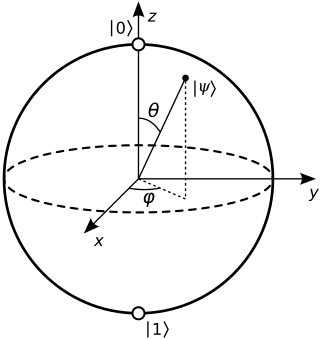
In quantum mechanics and computing, the Bloch sphere is a geometrical representation of the pure state space of a two-level quantum mechanical system (qubit), named after the physicist Felix Bloch.
In physics, a first class constraint is a dynamical quantity in a constrained Hamiltonian system whose Poisson bracket with all the other constraints vanishes on the constraint surface in phase space. To calculate the first class constraint, one assumes that there are no second class constraints, or that they have been calculated previously, and their Dirac brackets generated.
In mathematical statistics, the Kullback–Leibler (KL) divergence, denoted , is a type of statistical distance: a measure of how one probability distribution P is different from a second, reference probability distribution Q. A simple interpretation of the KL divergence of P from Q is the expected excess surprise from using Q as a model instead of P when the actual distribution is P. While it is a measure of how different two distributions are, and in some sense is thus a "distance", it is not actually a metric, which is the most familiar and formal type of distance. In particular, it is not symmetric in the two distributions, and does not satisfy the triangle inequality. Instead, in terms of information geometry, it is a type of divergence, a generalization of squared distance, and for certain classes of distributions, it satisfies a generalized Pythagorean theorem.
In statistical mechanics, the microcanonical ensemble is a statistical ensemble that represents the possible states of a mechanical system whose total energy is exactly specified. The system is assumed to be isolated in the sense that it cannot exchange energy or particles with its environment, so that the energy of the system does not change with time.
In Bayesian probability, the Jeffreys prior, named after Sir Harold Jeffreys, is a non-informative prior distribution for a parameter space; its density function is proportional to the square root of the determinant of the Fisher information matrix:
An ideal chain is the simplest model in polymer chemistry to describe polymers, such as nucleic acids and proteins. It assumes that the monomers in a polymer are located at the steps of a hypothetical random walker that does not remember its previous steps. By neglecting interactions among monomers, this model assumes that two monomers can occupy the same location. Although it is simple, its generality gives insight about the physics of polymers.

Assortativity, or assortative mixing, is a preference for a network's nodes to attach to others that are similar in some way. Though the specific measure of similarity may vary, network theorists often examine assortativity in terms of a node's degree. The addition of this characteristic to network models more closely approximates the behaviors of many real world networks.
Monte Carlo in statistical physics refers to the application of the Monte Carlo method to problems in statistical physics, or statistical mechanics.
Stress majorization is an optimization strategy used in multidimensional scaling (MDS) where, for a set of -dimensional data items, a configuration of points in -dimensional space is sought that minimizes the so-called stress function . Usually is or , i.e. the matrix lists points in or dimensional Euclidean space so that the result may be visualised. The function is a cost or loss function that measures the squared differences between ideal distances and actual distances in r-dimensional space. It is defined as:

In general relativity, a point mass deflects a light ray with impact parameter by an angle approximately equal to
In statistical mechanics, the eight-vertex model is a generalisation of the ice-type (six-vertex) models; it was discussed by Sutherland, and Fan & Wu, and solved by Baxter in the zero-field case.
In continuum mechanics, an Arruda–Boyce model is a hyperelastic constitutive model used to describe the mechanical behavior of rubber and other polymeric substances. This model is based on the statistical mechanics of a material with a cubic representative volume element containing eight chains along the diagonal directions. The material is assumed to be incompressible. The model is named after Ellen Arruda and Mary Cunningham Boyce, who published it in 1993.
Curvilinear coordinates can be formulated in tensor calculus, with important applications in physics and engineering, particularly for describing transportation of physical quantities and deformation of matter in fluid mechanics and continuum mechanics.
In network science, the network entropy is a disorder measure derived from information theory to describe the level of randomness and the amount of information encoded in a graph. It is a relevant metric to quantitatively characterize real complex networks and can also be used to quantify network complexity





























