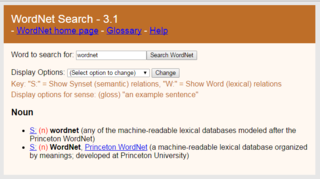
WordNet is a lexical database of semantic relations between words in more than 200 languages. WordNet links words into semantic relations including synonyms, hyponyms, and meronyms. The synonyms are grouped into synsets with short definitions and usage examples. WordNet can thus be seen as a combination and extension of a dictionary and thesaurus. While it is accessible to human users via a web browser, its primary use is in automatic text analysis and artificial intelligence applications. WordNet was first created in the English language and the English WordNet database and software tools have been released under a BSD style license and are freely available for download from that WordNet website.

Wiktionary is a multilingual, web-based project to create a free content dictionary of terms in all natural languages and in a number of artificial languages. These entries may contain definitions, images for illustration, pronunciations, etymologies, inflections, usage examples, quotations, related terms, and translations of terms into other languages, among other features. It is collaboratively edited via a wiki. Its name is a portmanteau of the words wiki and dictionary. It is available in 187 languages and in Simple English. Like its sister project Wikipedia, Wiktionary is run by the Wikimedia Foundation, and is written collaboratively by volunteers, dubbed "Wiktionarians". Its wiki software, MediaWiki, allows almost anyone with access to the website to create and edit entries.
FrameNet is a research and resource development project based at the International Computer Science Institute (ICSI) in Berkeley, California, which has produced an electronic resource based on a theory of meaning called frame semantics. The data that FrameNet has analyzed show that the sentence "John sold a car to Mary" essentially describes the same basic situation as "Mary bought a car from John", just from a different perspective. A semantic frame is a conceptual structure describing an event, relation, or object along with its participants. The FrameNet lexical database contains over 1,200 semantic frames, 13,000 lexical units and 202,000 example sentences. Charles J. Fillmore, who developed the theory of frame semantics which serves as the theoretical the basis of FrameNet, founded the project in 1997 and continued to lead the effort until he died in 2014. Frame Semantic theory and FrameNet have been influential in linguistics and natural language processing, where it led to the task of automatic Semantic Role Labeling.

A semantic lexicon is a digital dictionary of words labeled with semantic classes so associations can be drawn between words that have not previously been encountered. Semantic lexicons are built upon semantic networks, which represent the semantic relations between words. The difference between a semantic lexicon and a semantic network is that a semantic lexicon has definitions for each word, or a "gloss".

Interlingual machine translation is one of the classic approaches to machine translation. In this approach, the source language, i.e. the text to be translated is transformed into an interlingua, i.e., an abstract language-independent representation. The target language is then generated from the interlingua. Within the rule-based machine translation paradigm, the interlingual approach is an alternative to the direct approach and the transfer approach.
Simple Knowledge Organization System (SKOS) is a W3C recommendation designed for representation of thesauri, classification schemes, taxonomies, subject-heading systems, or any other type of structured controlled vocabulary. SKOS is part of the Semantic Web family of standards built upon RDF and RDFS, and its main objective is to enable easy publication and use of such vocabularies as linked data.
Lexipedia is an online visual semantic network with dictionary and thesaurus reference functionality built on Vantage Learning's Multilingual ConceptNet. Lexipedia presents words with their semantic relationships displayed in an animated visual word web. Lexipedia contains an expanded version of the English Wordnet and supports six languages; English, Dutch, French, German, Italian, Spanish languages.
Language resource management - Lexical markup framework, is the International Organization for Standardization ISO/TC37 standard for natural language processing (NLP) and machine-readable dictionary (MRD) lexicons. The scope is standardization of principles and methods relating to language resources in the contexts of multilingual communication.
In digital lexicography, natural language processing, and digital humanities, a lexical resource is a language resource consisting of data regarding the lexemes of the lexicon of one or more languages e.g., in the form of a database.
GermaNet is a semantic network for the German language. It relates nouns, verbs, and adjectives semantically by grouping lexical units that express the same concept into synsets and by defining semantic relations between these synsets. GermaNet is free for academic use, after signing a license. GermaNet has much in common with the English WordNet and can be viewed as an on-line thesaurus or a light-weight ontology. GermaNet has been developed and maintained at the University of Tübingen since 1997 within the research group for General and Computational Linguistics. It has been integrated into the EuroWordNet, a multilingual lexical-semantic database.
IndoWordNet is a linked lexical knowledge base of wordnets of 18 scheduled languages of India, viz., Assamese, Bangla, Bodo, Gujarati, Hindi, Kannada, Kashmiri, Konkani, Malayalam, Meitei (Manipuri), Marathi, Nepali, Odia, Punjabi, Sanskrit, Tamil, Telugu and Urdu.

BabelNet is a multilingual lexicalized semantic network and ontology developed at the NLP group of the Sapienza University of Rome. BabelNet was automatically created by linking Wikipedia to the most popular computational lexicon of the English language, WordNet. The integration is done using an automatic mapping and by filling in lexical gaps in resource-poor languages by using statistical machine translation. The result is an encyclopedic dictionary that provides concepts and named entities lexicalized in many languages and connected with large amounts of semantic relations. Additional lexicalizations and definitions are added by linking to free-license wordnets, OmegaWiki, the English Wiktionary, Wikidata, FrameNet, VerbNet and others. Similarly to WordNet, BabelNet groups words in different languages into sets of synonyms, called Babel synsets. For each Babel synset, BabelNet provides short definitions in many languages harvested from both WordNet and Wikipedia.
UBY-LMF is a format for standardizing lexical resources for Natural Language Processing (NLP). UBY-LMF conforms to the ISO standard for lexicons: LMF, designed within the ISO-TC37, and constitutes a so-called serialization of this abstract standard. In accordance with the LMF, all attributes and other linguistic terms introduced in UBY-LMF refer to standardized descriptions of their meaning in ISOCat.
plWordNet is a lexico-semantic database of the Polish language. It includes sets of synonymous lexical units (synsets) followed by short definitions. plWordNet serves as a thesaurus-dictionary where concepts (synsets) and individual word meanings are defined by their location in the network of mutual relations, reflecting the lexico-semantic system of the Polish language. plWordNet is also used as one of the basic resources for the construction of natural language processing tools for Polish.
The Bulgarian WordNet (BulNet) is an electronic multilingual dictionary of synonym sets along with their explanatory definitions and sets of semantic relations with other words in the language.
UBY is a large-scale lexical-semantic resource for natural language processing (NLP) developed at the Ubiquitous Knowledge Processing Lab (UKP) in the department of Computer Science of the Technische Universität Darmstadt . UBY is based on the ISO standard Lexical Markup Framework (LMF) and combines information from several expert-constructed and collaboratively constructed resources for English and German.

Malayalam WordNet (പദശൃംഖല) is an on line WordNet created for Malayalam Language. Malayalam WordNet has been developed by the Department of Computer Science, Cochin University Of Science And Technology.
In natural language processing, linguistics, and neighboring fields, Linguistic Linked Open Data (LLOD) describes a method and an interdisciplinary community concerned with creating, sharing, and (re-)using language resources in accordance with Linked Data principles. The Linguistic Linked Open Data Cloud was conceived and is being maintained by the Open Linguistics Working Group (OWLG) of the Open Knowledge Foundation, but has been a point of focal activity for several W3C community groups, research projects, and infrastructure efforts since then.

Arabic Ontology is a linguistic ontology for the Arabic language, which can be used as an Arabic WordNet with ontologically clean content. People use it also as a tree of the concepts/meanings of the Arabic terms. It is a formal representation of the concepts that the Arabic terms convey, and its content is ontologically well-founded, and benchmarked to scientific advances and rigorous knowledge sources rather than to speakers’ naïve beliefs as wordnets typically do . The Ontology tree can be explored online.
OntoLex is the short name of a vocabulary for lexical resources in the web of data (OntoLex-Lemon) and the short name of the W3C community group that created it.