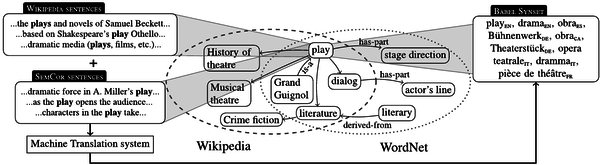
WordNet is a lexical database of semantic relations between words that links words into semantic relations including synonyms, hyponyms, and meronyms. The synonyms are grouped into synsets with short definitions and usage examples. It can thus be seen as a combination and extension of a dictionary and thesaurus. While it is accessible to human users via a web browser, its primary use is in automatic text analysis and artificial intelligence applications. It was first created in the English language and the English WordNet database and software tools have been released under a BSD style license and are freely available for download from that WordNet website. There are now WordNets in more than 200 languages.
Word-sense disambiguation is the process of identifying which sense of a word is meant in a sentence or other segment of context. In human language processing and cognition, it is usually subconscious.

A glossary, also known as a vocabulary or clavis, is an alphabetical list of terms in a particular domain of knowledge with the definitions for those terms. Traditionally, a glossary appears at the end of a book and includes terms within that book that are either newly introduced, uncommon, or specialized. While glossaries are most commonly associated with non-fiction books, in some cases, fiction novels sometimes include a glossary for unfamiliar terms.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity. These are mathematical tools used to estimate the strength of the semantic relationship between units of language, concepts or instances, through a numerical description obtained according to the comparison of information supporting their meaning or describing their nature. The term semantic similarity is often confused with semantic relatedness. Semantic relatedness includes any relation between two terms, while semantic similarity only includes "is a" relations. For example, "car" is similar to "bus", but is also related to "road" and "driving".
The sequence between semantic related ordered words is classified as a lexical chain. A lexical chain is a sequence of related words in writing, spanning narrow or wide context window. A lexical chain is independent of the grammatical structure of the text and in effect it is a list of words that captures a portion of the cohesive structure of the text. A lexical chain can provide a context for the resolution of an ambiguous term and enable disambiguation of concepts that the term represents.
Semantic analytics, also termed semantic relatedness, is the use of ontologies to analyze content in web resources. This field of research combines text analytics and Semantic Web technologies like RDF. Semantic analytics measures the relatedness of different ontological concepts.
The knowledge acquisition bottleneck is perhaps the major impediment to solving the word-sense disambiguation (WSD) problem. Unsupervised learning methods rely on knowledge about word senses, which is barely formulated in dictionaries and lexical databases. Supervised learning methods depend heavily on the existence of manually annotated examples for every word sense, a requisite that can so far be met only for a handful of words for testing purposes, as it is done in the Senseval exercises.
In computational linguistics, word-sense induction (WSI) or discrimination is an open problem of natural language processing, which concerns the automatic identification of the senses of a word. Given that the output of word-sense induction is a set of senses for the target word, this task is strictly related to that of word-sense disambiguation (WSD), which relies on a predefined sense inventory and aims to solve the ambiguity of words in context.
SemEval is an ongoing series of evaluations of computational semantic analysis systems; it evolved from the Senseval word sense evaluation series. The evaluations are intended to explore the nature of meaning in language. While meaning is intuitive to humans, transferring those intuitions to computational analysis has proved elusive.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
GermaNet is a semantic network for the German language. It relates nouns, verbs, and adjectives semantically by grouping lexical units that express the same concept into synsets and by defining semantic relations between these synsets. GermaNet is free for academic use, after signing a license. GermaNet has much in common with the English WordNet and can be viewed as an on-line thesaurus or a light-weight ontology. GermaNet has been developed and maintained at the University of Tübingen since 1997 within the research group for General and Computational Linguistics. It has been integrated into the EuroWordNet, a multilingual lexical-semantic database.
IndoWordNet is a linked lexical knowledge base of wordnets of 18 scheduled languages of India, viz., Assamese, Bangla, Bodo, Gujarati, Hindi, Kannada, Kashmiri, Konkani, Malayalam, Meitei (Manipuri), Marathi, Nepali, Odia, Punjabi, Sanskrit, Tamil, Telugu and Urdu.
UBY-LMF is a format for standardizing lexical resources for Natural Language Processing (NLP). UBY-LMF conforms to the ISO standard for lexicons: LMF, designed within the ISO-TC37, and constitutes a so-called serialization of this abstract standard. In accordance with the LMF, all attributes and other linguistic terms introduced in UBY-LMF refer to standardized descriptions of their meaning in ISOCat.

Babelfy is a software algorithm for the disambiguation of text written in any language.
In natural language processing, a word embedding is a representation of a word. The embedding is used in text analysis. Typically, the representation is a real-valued vector that encodes the meaning of the word in such a way that the words that are closer in the vector space are expected to be similar in meaning. Word embeddings can be obtained using language modeling and feature learning techniques, where words or phrases from the vocabulary are mapped to vectors of real numbers.
The Bulgarian Sense-annotated Corpus (BulSemCor) is a structured corpus of Bulgarian texts in which each lexical item is assigned a sense tag. BulSemCor was created by the Department of Computational Linguistics at the Institute for Bulgarian Language of the Bulgarian Academy of Sciences.
The Bulgarian WordNet (BulNet) is an electronic multilingual dictionary of synonym sets along with their explanatory definitions and sets of semantic relations with other words in the language.
UBY is a large-scale lexical-semantic resource for natural language processing (NLP) developed at the Ubiquitous Knowledge Processing Lab (UKP) in the department of Computer Science of the Technische Universität Darmstadt . UBY is based on the ISO standard Lexical Markup Framework (LMF) and combines information from several expert-constructed and collaboratively constructed resources for English and German.
OntoLex is the short name of a vocabulary for lexical resources in the web of data (OntoLex-Lemon) and the short name of the W3C community group that created it.

Roberto Navigli is an Italian computer scientist and Professor in the Department of Computer, Control and Management Engineering "Antonio Ruberti" at the Sapienza University of Rome, where he is also the Director of the Sapienza NLP Group. His research focuses on Artificial Intelligence, specifically on enabling computers to understand and represent meaning across hundreds of languages, making significant contributions to various fields within Natural Language Processing, including Word Sense Disambiguation, Entity Linking, Semantic Role Labeling and semantic parsing. He created BabelNet, a multilingual knowledge graph that brings together knowledge from resources including WordNet, Wikipedia, Wiktionary and Wikidata. At the core of his research lies the goal of making semantic representations of words and sentences independent of the language in which they are written. More recently, he has focused on Large Language Models, leading the Minerva LLM project, the first Italian effort for pretraining a LLM from scratch.