Related Research Articles
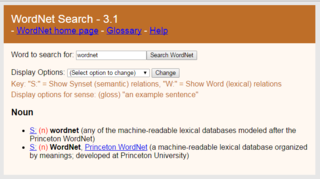
WordNet is a lexical database of semantic relations between words that links words into semantic relations including synonyms, hyponyms, and meronyms. The synonyms are grouped into synsets with short definitions and usage examples. It can thus be seen as a combination and extension of a dictionary and thesaurus. While it is accessible to human users via a web browser, its primary use is in automatic text analysis and artificial intelligence applications. It was first created in the English language and the English WordNet database and software tools have been released under a BSD style license and are freely available for download from that WordNet website. There are now WordNets in more than 200 languages.
Word-sense disambiguation is the process of identifying which sense of a word is meant in a sentence or other segment of context. In human language processing and cognition, it is usually subconscious.

Wiktionary is a multilingual, web-based project to create a free content dictionary of terms in all natural languages and in a number of artificial languages. These entries may contain definitions, images for illustration, pronunciations, etymologies, inflections, usage examples, quotations, related terms, and translations of terms into other languages, among other features. It is collaboratively edited via a wiki. Its name is a portmanteau of the words wiki and dictionary. It is available in 193 languages and in Simple English. Like its sister project Wikipedia, Wiktionary is run by the Wikimedia Foundation, and is written collaboratively by volunteers, dubbed "Wiktionarians". Its wiki software, MediaWiki, allows almost anyone with access to the website to create and edit entries.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity. These are mathematical tools used to estimate the strength of the semantic relationship between units of language, concepts or instances, through a numerical description obtained according to the comparison of information supporting their meaning or describing their nature. The term semantic similarity is often confused with semantic relatedness. Semantic relatedness includes any relation between two terms, while semantic similarity only includes "is a" relations. For example, "car" is similar to "bus", but is also related to "road" and "driving".
The sequence between semantic related ordered words is classified as a lexical chain. A lexical chain is a sequence of related words in writing, spanning narrow or wide context window. A lexical chain is independent of the grammatical structure of the text and in effect it is a list of words that captures a portion of the cohesive structure of the text. A lexical chain can provide a context for the resolution of an ambiguous term and enable disambiguation of concepts that the term represents.
The VerbNet project maps PropBank verb types to their corresponding Levin classes. It is a lexical resource that incorporates both semantic and syntactic information about its contents.
Linguistic categories include
Computational lexicology is a branch of computational linguistics, which is concerned with the use of computers in the study of lexicon. It has been more narrowly described by some scholars as the use of computers in the study of machine-readable dictionaries. It is distinguished from computational lexicography, which more properly would be the use of computers in the construction of dictionaries, though some researchers have used computational lexicography as synonymous.
Machine-readable dictionary (MRD) is a dictionary stored as machine-readable data instead of being printed on paper. It is an electronic dictionary and lexical database.
Language resource management – Lexical markup framework, produced by ISO/TC 37, is the ISO standard for natural language processing (NLP) and machine-readable dictionary (MRD) lexicons. The scope is standardization of principles and methods relating to language resources in the contexts of multilingual communication.
In digital lexicography, natural language processing, and digital humanities, a lexical resource is a language resource consisting of data regarding the lexemes of the lexicon of one or more languages e.g., in the form of a database.
The Ubiquitous Knowledge Processing Lab is a research lab at the Department of Computer Science at the Technische Universität Darmstadt. It was founded in 2006 by Iryna Gurevych.
SemEval is an ongoing series of evaluations of computational semantic analysis systems; it evolved from the Senseval word sense evaluation series. The evaluations are intended to explore the nature of meaning in language. While meaning is intuitive to humans, transferring those intuitions to computational analysis has proved elusive.
GermaNet is a semantic network for the German language. It relates nouns, verbs, and adjectives semantically by grouping lexical units that express the same concept into synsets and by defining semantic relations between these synsets. GermaNet is free for academic use, after signing a license. GermaNet has much in common with the English WordNet and can be viewed as an on-line thesaurus or a light-weight ontology. GermaNet has been developed and maintained at the University of Tübingen since 1997 within the research group for General and Computational Linguistics. It has been integrated into the EuroWordNet, a multilingual lexical-semantic database.
BabelNet is a multilingual lexicalized semantic network and ontology developed at the NLP group of the Sapienza University of Rome. BabelNet was automatically created by linking Wikipedia to the most popular computational lexicon of the English language, WordNet. The integration is done using an automatic mapping and by filling in lexical gaps in resource-poor languages by using statistical machine translation. The result is an encyclopedic dictionary that provides concepts and named entities lexicalized in many languages and connected with large amounts of semantic relations. Additional lexicalizations and definitions are added by linking to free-license wordnets, OmegaWiki, the English Wiktionary, Wikidata, FrameNet, VerbNet and others. Similarly to WordNet, BabelNet groups words in different languages into sets of synonyms, called Babel synsets. For each Babel synset, BabelNet provides short definitions in many languages harvested from both WordNet and Wikipedia.
UBY-LMF is a format for standardizing lexical resources for Natural Language Processing (NLP). UBY-LMF conforms to the ISO standard for lexicons: LMF, designed within the ISO-TC37, and constitutes a so-called serialization of this abstract standard. In accordance with the LMF, all attributes and other linguistic terms introduced in UBY-LMF refer to standardized descriptions of their meaning in ISOCat.
In natural language processing (NLP), a word embedding is a representation of a word. The embedding is used in text analysis. Typically, the representation is a real-valued vector that encodes the meaning of the word in such a way that the words that are closer in the vector space are expected to be similar in meaning. Word embeddings can be obtained using language modeling and feature learning techniques, where words or phrases from the vocabulary are mapped to vectors of real numbers.
In natural language processing, linguistics, and neighboring fields, Linguistic Linked Open Data (LLOD) describes a method and an interdisciplinary community concerned with creating, sharing, and (re-)using language resources in accordance with Linked Data principles. The Linguistic Linked Open Data Cloud was conceived and is being maintained by the Open Linguistics Working Group (OWLG) of the Open Knowledge Foundation, but has been a point of focal activity for several W3C community groups, research projects, and infrastructure efforts since then.

Iryna Gurevych, member Leopoldina, is a Ukrainian computer scientist. She is Professor at the Department of Computer Science of the Technical University of Darmstadt and Director of Ubiquitous Knowledge Processing Lab.
OntoLex is the short name of a vocabulary for lexical resources in the web of data (OntoLex-Lemon) and the short name of the W3C community group that created it.
References
- ↑ Iryna Gurevych; Judith Eckle-Kohler; Silvana Hartmann; Michael Matuschek; Christian M. Meyer; Christian Wirth (April 2012). UBY - A Large-Scale Unified Lexical-Semantic Resource Based on LMF. Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics. pp. 580–590. ISBN 978-1-937284-19-0. S2CID 9692934. Wikidata Q51752742.
{{cite book}}:|journal=ignored (help) - ↑ Matuschek, Michael: Word Sense Alignment of Lexical Resources. Technische Universität, Darmstadt [Dissertation], (2015)
- ↑ Judith Eckle-Kohler, Iryna Gurevych, Silvana Hartmann, Michael Matuschek, Christian M Meyer: UBY-LMF – exploring the boundaries of language-independent lexicon models, in Gil Francopoulo, LMF Lexical Markup Framework, ISTE / Wiley 2013 ( ISBN 978-1-84821-430-9)
- ↑ Judith Eckle-Kohler, Iryna Gurevych, Silvana Hartmann, Michael Matuschek and Christian M. Meyer. UBY-LMF – A Uniform Model for Standardizing Heterogeneous Lexical-Semantic Resources in ISO-LMF. In: Nicoletta Calzolari and Khalid Choukri and Thierry Declerck and Mehmet Uğur Doğan and Bente Maegaard and Joseph Mariani and Jan Odijk and Stelios Piperidis: Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC), p. 275--282, May 2012.
- ↑ Gottfried Herzog, Laurent Romary, Andreas Witt: Standards for Language Resources. Poster Presentation at the META-FORUM 2013 – META Exhibition, September 2013, Berlin, Germany.
- ↑ Laurent Romary: TEI and LMF crosswalks. CoRR abs/1301.2444 (2013)
- ↑ Judith Eckle-Kohler, John Philip McCrae and Christian Chiarcos: lemonUby – a large, interlinked, syntactically-rich lexical resource for ontologies. In: Semantic Web Journal, vol. 6, no. 4, p. 371-378, 2015.
- ↑ Christian M. Meyer and Iryna Gurevych: To Exhibit is not to Loiter: A Multilingual, Sense-Disambiguated Wiktionary for Measuring Verb Similarity, in: Proceedings of the 24th International Conference on Computational Linguistics (COLING), Vol. 4, p. 1763–1780, December 2012. Mumbai, India.
- ↑ Michael Matuschek, Tristan Miller and Iryna Gurevych: A Language-independent Sense Clustering Approach for Enhanced WSD. In: Josef Ruppert and Gertrud Faaß: Proceedings of the 12th Konferenz zur Verarbeitung natürlicher Sprache (KONVENS 2014), p. 11-21, Universitätsverlag Hildesheim, October 2014.
- ↑ Kostadin Cholakov and Judith Eckle-Kohler and Iryna Gurevych : Automated Verb Sense Labelling Based on Linked Lexical Resources. In: Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2014), p. 68-77, Association for Computational Linguistics
- ↑ Lucie Flekova and Iryna Gurevych: Personality Profiling of Fictional Characters using Sense-Level Links between Lexical Resources, in: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), September 2015.
- ↑ José Gildo de A. Júnior, Ulrich Schiel, and Leandro Balby Marinho. 2015. An approach for building lexical-semantic resources based on heterogeneous information sources. In Proceedings of the 30th Annual ACM Symposium on Applied Computing (SAC '15). ACM, New York, USA, 402-408. DOI=10.1145/2695664.2695896 http://doi.acm.org/10.1145/2695664.2695896
- ↑ J. P. McCrae, P. Cimiano: Mining translations from the web of open linked data, in: Proceedings of the Joint Workshop on NLP&LOD and SWAIE: Semantic Web, Linked Open Data and Information Extraction, pp 9-13 (2013).