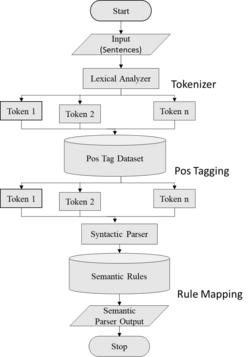
Semantic parsing maps text to formal meaning representations. This contrasts with semantic role labeling and other forms of shallow semantic processing, which do not aim to produce complete formal meanings.[9] In computer vision, semantic parsing is a process of segmentation for 3D objects.[10][11]
Major levels of linguistic structure
History and Background
Early research of semantic parsing included the generation of grammar manually,[12] as well as utilizing applied programming logic.[13] In the 2000s, most of the work in this area involved the creation/learning and use of different grammars and lexicons on controlled tasks,[14][15] particularly general grammars such as SCFGs.[16] This improved upon manual grammars primarily because they leveraged the syntactical nature of the sentence, but they still could not cover enough variation and were not robust enough to be used in the real world. However, following the development of advanced neural network techniques, especially the Seq2Seq model,[17] and the availability of powerful computational resources, neural semantic parsing started emerging. Not only was it providing competitive results on the existing datasets, but it was robust to noise and did not require a lot of supervision and manual intervention.
The current transition of traditional parsing to neural semantic parsing has not been perfect though. Neural semantic parsing, even with its advantages, still fails to solve the problem at a deeper level. Neural models like Seq2Seq treat the parsing problem as a sequential translation problem, and the model learns patterns in a black-box manner, which means we cannot really predict whether the model is truly solving the problem. Intermediate efforts and modifications to the Seq2Seq to incorporate syntax and semantic meaning have been attempted,[18][19] with a marked improvement in results, but there remains a lot of ambiguity to be taken care of.
Shallow semantic parsing is concerned with identifying entities in an utterance and labelling them with the roles they play. Shallow semantic parsing is sometimes known as slot-filling or frame semantic parsing, since its theoretical basis comes from frame semantics, wherein a word evokes a frame of related concepts and roles. Slot-filling systems are widely used in virtual assistants in conjunction with intent classifiers, which can be seen as mechanisms for identifying the frame evoked by an utterance.[20][21] Popular architectures for slot-filling are largely variants of an encoder-decoder model, wherein two recurrent neural networks (RNNs) are trained jointly to encode an utterance into a vector and to decode that vector into a sequence of slot labels.[22] This type of model is used in the Amazon Alexa spoken language understanding system.[20] This parsing follow an unsupervised learning techniques.
Deep Semantic Parsing
Deep semantic parsing, also known as compositional semantic parsing, is concerned with producing precise meaning representations of utterances that can contain significant compositionality.[23] Shallow semantic parsers can parse utterances like "show me flights from Boston to Dallas" by classifying the intent as "list flights", and filling slots "source" and "destination" with "Boston" and "Dallas", respectively. However, shallow semantic parsing cannot parse arbitrary compositional utterances, like "show me flights from Boston to anywhere that has flights to Juneau". Deep semantic parsing attempts to parse such utterances, typically by converting them to a formal meaning representation language. Nowadays, compositional semantic parsing are using Large Language Models to solve artificial compositional generalization tasks such as SCAN.[24]
Neural Semantic Parsing
Semantic parsers play a crucial role in natural language understanding systems because they transform natural language utterances into machine-executable logical structures or programmes. A well-established field of study, semantic parsing finds use in voice assistants, question answering, instruction following, and code generation. Since Neural approaches have been available for two years, many of the presumptions that underpinned semantic parsing have been rethought, leading to a substantial change in the models employed for semantic parsing. Though Semantic neural network and Neural Semantic Parsing[25] both deal with Natural Language Processing (NLP) and semantics, they are not same. The models and executable formalisms used in semantic parsing research have traditionally been strongly dependent on concepts from formal semantics in linguistics, like the λ-calculus produced by a CCG parser. Nonetheless, more approachable formalisms, like conventional programming languages, and NMT-style models that are considerably more accessible to a wider NLP audience, are made possible by recent work with neural encoder-decoder semantic parsers. We'll give a summary of contemporary neural approaches to semantic parsing and discuss how they've affected the field's understanding of semantic parsing.
Representation languages
Early semantic parsers used highly domain-specific meaning representation languages,[26] with later systems using more extensible languages like Prolog,[13]lambda calculus,[16] lambda dependency-based compositional semantics (λ-DCS),[27]SQL,[28][29]Python,[30]Java,[31] the Alexa Meaning Representation Language,[20] and the Abstract Meaning Representation (AMR). Some work has used more exotic meaning representations, like query graphs,[32] semantic graphs,[33] or vector representations.[34]
Models
Most modern deep semantic parsing models are either based on defining a formal grammar for a chart parser or utilizing RNNs to directly translate from a natural language to a meaning representation language. Examples of systems built on formal grammars are the Cornell Semantic Parsing Framework,[35]Stanford University's Semantic Parsing with Execution (SEMPRE),[3] and the Word Alignment-based Semantic Parser (WASP).[36]
Datasets
Datasets used for training statistical semantic parsing models are divided into two main classes based on application: those used for question answering via knowledge base queries, and those used for code generation.
Question answering
Semantic Parsing for Conversational Question Answering
A standard dataset for question answering via semantic parsing is the Air Travel Information System (ATIS) dataset, which contains questions and commands about upcoming flights as well as corresponding SQL.[28] Another benchmark dataset is the GeoQuery dataset which contains questions about the geography of the U.S. paired with corresponding Prolog.[13] The Overnight dataset is used to test how well semantic parsers adapt across multiple domains; it contains natural language queries about 8 different domains paired with corresponding λ-DCS expressions.[37] Recently, semantic parsing is gaining significant popularity as a result of new research works and many large companies, namely Google, Microsoft, Amazon, etc. are working on this area. One on the recent works of Semantic Parsing for question answering is attached here.[38] Shown in this picture is a representation of an example conversation from SPICE. The left column shows dialogue turns (T1–T3) with user (U) and system (S) utterances. The middle column shows the annotations provided in CSQA. Blue boxes on the right show the sequence of actions (AS) and corresponding SPARQL semantic parses (SP).
Code generation
Popular datasets for code generation include two trading card datasets that link the text that appears on cards to code that precisely represents those cards. One was constructed linking Magic: The Gathering card texts to Java snippets; the other by linking Hearthstone card texts to Python snippets.[31] The IFTTT dataset[39] uses a specialized domain-specific language with short conditional commands. The Django dataset[40] pairs Python snippets with English and Japanese pseudocode describing them. The RoboCup dataset[41] pairs English rules with their representations in a domain-specific language that can be understood by virtual soccer-playing robots.
Application Areas
Within the field of natural language processing (NLP), semantic parsing deals with transforming human language into a format that is easier for machines to understand and comprehend. This method is useful in a number of contexts:
Voice Assistants and Chatbots: Semantic parsing enhances the quality of user interaction in devices such as smart speakers and chatbots for customer service by comprehending and answering user inquiries in natural language.
Information Retrieval: It improves the comprehension and processing of user queries by search engines and databases, resulting in more precise and pertinent search results.
Machine Translation: To improve the quality and context of translation, machine translation entails comprehending the semantics of one language in order to translate it into another accurately.
Text Analytics: Business intelligence and social media monitoring benefit from the meaningful insights that can be extracted from text data through semantic parsing. Examples of these insights include sentiment analysis, topic modelling, and trend analysis.
Question Answering Systems: Found in systems such as IBM Watson, these systems assist in comprehending and analyzing natural language queries in order to deliver precise responses. They are particularly helpful in areas such as customer service and educational resources.
Command and Control Systems: Semantic parsing aids in the accurate interpretation of voice or text commands used to control systems in applications such as software interfaces or smart homes.
Content Categorization: It is a useful tool for online publishing and digital content management as it aids in the classification and organization of vast amounts of textual material by analyzing its semantic content.
Technologies related to accessibility: Helps create tools for the disabled, such as sign language interpretation and text to speech conversion.
Legal and Healthcare Informatics: Semantic parsing can extract and structure important information from legal documents and medical records to support research and decision-making.
Semantic parsing aims to improve various applications' efficiency and efficacy by bridging the gap between human language and machine processing in each of these domains.
Evaluation
Depending on the type of meaning representation parsed into and underlying goals to perform parsing, evaluation metrics vary accordingly:
For meaning representations that can be represented as graphs, such as Abstract Meaning Representation, graph similarity between system output and reference graph allows evaluation even of partial successes in parsing.[42]
If semantic parsing is framed as a sequence-to-sequence (seq2seq) task, more traditional metrics used in natural language processing for comparing sequences, such as BLEU, can be utilized.[44][45]:7
Aside from metrics rewarding partial successes, a more strict metric is that of exact match of system output and the reference. Accuracy, as percentage of samples with correctly predicted meaning, is reported for instance for some text-to-SQL parsing tasks.[46]:6f When compositional generalization abilities of semantic parsers should be tested accuracy is used too.[47][48][49]
For executable semantic parsing, not only the meaning representation predicted can be evaluated, but also the result of executing the prediction. As a first step, however, the predicted representation needs to be syntactically well-formed to allow execution. For all well-formed system outputs, the execution result can be compared to the result of executing the gold standard representation.[44]:5,15
↑Andreas, Jacob, Andreas Vlachos, and Stephen Clark. "Semantic parsing as machine translation." Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Vol. 2. 2013.
↑Poon, Hoifung, and Pedro Domingos. "Unsupervised ontology induction from text." Proceedings of the 48th annual meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2010.
↑Rabinovich, Maxim; Stern, Mitchell; Klein, Dan (2017-04-25). "Abstract Syntax Networks for Code Generation and Semantic Parsing". arXiv:1704.07535 [cs.CL].
↑Yin, Pengcheng; Neubig, Graham (2017-04-05). "A Syntactic Neural Model for General-Purpose Code Generation". arXiv:1704.01696 [cs.CL].
↑Wilks, Y. and Fass, D. (1992) The Preference Semantics Family, In Computers and Mathematics with Applications, Volume 23, Issues 2-5, Pages 205-221.
↑Hoifung Poon, Pedro Domingos Unsupervised Semantic Parsing , Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, 2009
123Zelle, J. M.; Mooney, R. J. (1996). "Learning to parse database queries using inductive logic programming". Proceedings of the National Conference on Artificial Intelligence: 1050–1055. hdl:1721.1/7095.
↑Dong, L.; Lapata, M. (2016). "Language to logical form with neural attention". Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Vol.1: Long Papers. pp.33–43. arXiv:1601.01280.
↑Yin, Pengcheng; Neubig, Graham (2017). "A Syntactic Neural Model for General-Purpose Code Generation". Proceedings of 55th Annual Meeting of the Association for Computational Linguistics. Volume 1: Long Papers: 440–450. doi:10.18653/v1/P17-1041.
↑Shi, Tianze; etal. (2018). "A Incsql: Training incremental text-to-sql parsers with non-deterministic oracles". arXiv:1809.05054 [cs.CL].
123Kumar, Anjishnu; etal. (2018). "Just ASK: Building an Architecture for Extensible Self-Service Spoken Language Understanding". arXiv:1711.00549 [cs.CL].
↑Liu, Bing; Lane, Ian (2016). "Attention-based recurrent neural network models for joint intent detection and slot filling". arXiv:1609.01454 [cs.CL].
↑Liang, Percy; Potts, Christopher (2015). "Bringing machine learning and compositional semantics together". Annual Review of Linguistics. 1 (1): 355–376. doi:10.1146/annurev-linguist-030514-125312.
↑Drozdov, Andrew; etal. (2022). "Compositional Semantic Parsing with Large Language Models". arXiv:2209.15003 [cs.CL].
↑Matt Gardner, Pradeep Dasigi, Srinivasan Iyer, Alane Suhr, Luke Zettlemoyer. "Neural Semantic Parsing" Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts, July 2018.
↑Woods, William A. (1979). Semantics for a question-answering system. Outstanding dissertations in the computer sciences. Vol.27. New York: Garland. ISBN0-8240-4419-3.
12Hemphill, Charles T.; etal. (1990). "The ATIS spoken language systems pilot corpus". Speech and Natural Language: Proceedings of a Workshop Held at Hidden Valley, Pennsylvania, June 24–27, 1990.
↑Iyer, Srinivasan; etal. (2017). "Learning a neural semantic parser from user feedback". arXiv:1704.08760 [cs.CL].
↑Yin, Pengcheng; Neubig, Graham (2017). "A syntactic neural model for general-purpose code generation". arXiv:1704.01696 [cs.CL].
↑Wang, Yushi, Jonathan Berant, and Percy Liang. "Building a semantic parser overnight."Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Vol. 1. 2015.
↑Perez-Beltrachini, Laura; Jain, Parag; Monti, Emilio; Lapata, Mirella (2023). "Semantic Parsing for Conversational Question Answering over Knowledge Graphs". arXiv:2301.12217 [cs.CL].
↑Quirk, Chris, Raymond Mooney, and Michel Galley. "Language to code: Learning semantic parsers for if-this-then-that recipes."Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Vol. 1. 2015.
12Oepen, Stephan; Abend, Omri; Hajic, Jan; Hershcovich, Daniel; Kuhlmann, Marco; O’Gorman, Tim; Xue, Nianwen; Chun, Jayeol; Straka, Milan; Uresova, Zdenka (2019). "MRP 2019: Cross-Framework Meaning Representation Parsing"(PDF). Proceedings of the Shared Task on Cross-Framework Meaning Representation Parsing at the 2019 Conference on Natural Language Learning. Association for Computational Linguistics. pp.1–27. doi:10.18653/v1/K19-2001. Retrieved 2025-06-20.
↑Van Noord, Rik; Abzianidze, Lasha; Haagsma, Hessel; Bos, Johan (2018). Calzolari, Nicoletta; Choukri, Khalid; Cieri, Christopher; Declerck, Thierry; Goggi, Sara; Hasida, Koiti; Isahara, Hitoshi; Maegaard, Bente; Mariani, Joseph; Mazo, Hélène; Moreno, Asuncion; Odijk, Jan; Piperidis, Stelios; Tokunaga, Takenobu (eds.). Evaluating Scoped Meaning Representations(PDF). Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). Miyazaki, Japan: European Language Resources Association (ELRA). pp.1685–1693. Retrieved 2025-06-20.
↑Lee, Celine; Gottschlich, Justin; Roth, Dan (2021-04-26). "Toward Code Generation: A Survey and Lessons from Semantic Parsing". arXiv:2105.03317 [cs.SE].
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.