The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
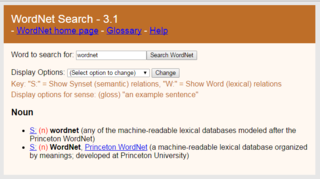
WordNet is a lexical database of semantic relations between words in more than 200 languages. WordNet links words into semantic relations including synonyms, hyponyms, and meronyms. The synonyms are grouped into synsets with short definitions and usage examples. WordNet can thus be seen as a combination and extension of a dictionary and thesaurus. While it is accessible to human users via a web browser, its primary use is in automatic text analysis and artificial intelligence applications. WordNet was first created in the English language and the English WordNet database and software tools have been released under a BSD style license and are freely available for download from that WordNet website.

Wiktionary is a multilingual, web-based project to create a free content dictionary of terms in all natural languages and in a number of artificial languages. These entries may contain definitions, images for illustrations, pronunciations, etymologies, inflections, usage examples, quotations, related terms, and translations of words into other languages, among other features. It is collaboratively edited via a wiki. Its name is a portmanteau of the words wiki and dictionary. It is available in 182 languages and in Simple English. Like its sister project Wikipedia, Wiktionary is run by the Wikimedia Foundation, and is written collaboratively by volunteers, dubbed "Wiktionarians". Its wiki software, MediaWiki, allows almost anyone with access to the website to create and edit entries.
A monolingual learner's dictionary (MLD) is designed to meet the reference needs of people learning a foreign language. MLDs are based on the premise that language-learners should progress from a bilingual dictionary to a monolingual one as they become more proficient in their target language, but that general-purpose dictionaries are inappropriate for their needs. Dictionaries for learners include information on grammar, usage, common errors, collocation, and pragmatics, which is largely missing from standard dictionaries, because native speakers tend to know these aspects of language intuitively. And while the definitions in standard dictionaries are often written in difficult language, those in an MLD use a simple and accessible defining vocabulary.
A modeling language is any artificial language that can be used to express information or knowledge or systems in a structure that is defined by a consistent set of rules. The rules are used for interpretation of the meaning of components in the structure.
The Gene Ontology (GO) is a major bioinformatics initiative to unify the representation of gene and gene product attributes across all species. More specifically, the project aims to: 1) maintain and develop its controlled vocabulary of gene and gene product attributes; 2) annotate genes and gene products, and assimilate and disseminate annotation data; and 3) provide tools for easy access to all aspects of the data provided by the project, and to enable functional interpretation of experimental data using the GO, for example via enrichment analysis. GO is part of a larger classification effort, the Open Biomedical Ontologies, being one of the Initial Candidate Members of the OBO Foundry.
The semantic spectrum is a series of increasingly precise or rather semantically expressive definitions for data elements in knowledge representations, especially for machine use.

An electronic dictionary is a dictionary whose data exists in digital form and can be accessed through a number of different media. Electronic dictionaries can be found in several forms, including software installed on tablet or desktop computers, mobile apps, web applications, and as a built-in function of E-readers. They may be free or require payment.
Gellish is an ontology language for data storage and communication, designed and developed by Andries van Renssen since mid-1990s. It started out as an engineering modeling language but evolved into a universal and extendable conceptual data modeling language with general applications. Because it includes domain-specific terminology and definitions, it is also a semantic data modelling language and the Gellish modeling methodology is a member of the family of semantic modeling methodologies.
Linguistic categories include
Computational lexicology is a branch of computational linguistics, which is concerned with the use of computers in the study of lexicon. It has been more narrowly described by some scholars as the use of computers in the study of machine-readable dictionaries. It is distinguished from computational lexicography, which more properly would be the use of computers in the construction of dictionaries, though some researchers have used computational lexicography as synonymous.
Language resource management - Lexical markup framework, is the ISO International Organization for Standardization ISO/TC37 standard for natural language processing (NLP) and machine-readable dictionary (MRD) lexicons. The scope is standardization of principles and methods relating to language resources in the contexts of multilingual communication.
In digital lexicography, natural language processing, and digital humanities, a lexical resource is a language resource consisting of data regarding the lexemes of the lexicon of one or more languages e.g., in the form of a database.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
The following outline is provided as an overview of and topical guide to natural language processing:
UBY is a large-scale lexical-semantic resource for natural language processing (NLP) developed at the Ubiquitous Knowledge Processing Lab (UKP) in the department of Computer Science of the Technische Universität Darmstadt . UBY is based on the ISO standard Lexical Markup Framework (LMF) and combines information from several expert-constructed and collaboratively constructed resources for English and German.
In natural language processing, linguistics, and neighboring fields, Linguistic Linked Open Data (LLOD) describes a method and an interdisciplinary community concerned with creating, sharing, and (re-)using language resources in accordance with Linked Data principles. The Linguistic Linked Open Data Cloud was conceived and is being maintained by the Open Linguistics Working Group (OWLG) of the Open Knowledge Foundation, but has been a point of focal activity for several W3C community groups, research projects, and infrastructure efforts since then.
OntoLex is the short name of a vocabulary for lexical resources in the web of data (OntoLex-Lemon) and the short name of the W3C community group that created it.