Related Research Articles
Information retrieval (IR) is the activity of obtaining information system resources that are relevant to an information need from a collection of those resources. Searches can be based on full-text or other content-based indexing. Information retrieval is the science of searching for information in a document, searching for documents themselves, and also searching for the metadata that describes data, and for databases of texts, images or sounds.
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text. A matrix containing word counts per document is constructed from a large piece of text and a mathematical technique called singular value decomposition (SVD) is used to reduce the number of rows while preserving the similarity structure among columns. Documents are then compared by taking the cosine of the angle between the two vectors formed by any two columns. Values close to 1 represent very similar documents while values close to 0 represent very dissimilar documents.
Document retrieval is defined as the matching of some stated user query against a set of free-text records. These records could be any type of mainly unstructured text, such as newspaper articles, real estate records or paragraphs in a manual. User queries can range from multi-sentence full descriptions of an information need to a few words.
In text retrieval, full-text search refers to techniques for searching a single computer-stored document or a collection in a full-text database. Full-text search is distinguished from searches based on metadata or on parts of the original texts represented in databases.
In text processing, a proximity search looks for documents where two or more separately matching term occurrences are within a specified distance, where distance is the number of intermediate words or characters. In addition to proximity, some implementations may also impose a constraint on the word order, in that the order in the searched text must be identical to the order of the search query. Proximity searching goes beyond the simple matching of words by adding the constraint of proximity and is generally regarded as a form of advanced search.
In information retrieval, tf–idf, TF*IDF, or TFIDF, short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus. It is often used as a weighting factor in searches of information retrieval, text mining, and user modeling. The tf–idf value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently in general. tf–idf is one of the most popular term-weighting schemes today. A survey conducted in 2015 showed that 83% of text-based recommender systems in digital libraries use tf–idf.
Search engine optimisation indexing collects, parses, and stores data to facilitate fast and accurate information retrieval. Index design incorporates interdisciplinary concepts from linguistics, cognitive psychology, mathematics, informatics, and computer science. An alternate name for the process in the context of search engines designed to find web pages on the Internet is web indexing.
Query expansion (QE) is the process of reformulating a given query to improve retrieval performance in information retrieval operations, particularly in the context of query understanding. In the context of search engines, query expansion involves evaluating a user's input and expanding the search query to match additional documents. Query expansion involves techniques such as:
In information retrieval, Okapi BM25 is a ranking function used by search engines to estimate the relevance of documents to a given search query. It is based on the probabilistic retrieval framework developed in the 1970s and 1980s by Stephen E. Robertson, Karen Spärck Jones, and others.
Subject indexing is the act of describing or classifying a document by index terms or other symbols in order to indicate what the document is about, to summarize its content or to increase its findability. In other words, it is about identifying and describing the subject of documents. Indexes are constructed, separately, on three distinct levels: terms in a document such as a book; objects in a collection such as a library; and documents within a field of knowledge.
Audio mining is a technique by which the content of an audio signal can be automatically analyzed and searched. It is most commonly used in the field of automatic speech recognition, where the analysis tries to identify any speech within the audio. The term ‘audio mining’ is sometimes used interchangeably with audio indexing, phonetic searching, phonetic indexing, speech indexing, audio analytics, speech analytics, word spotting, and information retrieval. Audio indexing, however, is mostly used to describe the pre-process of audio mining, in which the audio file is broken down into a searchable index of words.

Karen Spärck Jones FBA was a pioneering British computer scientist responsible for the concept of inverse document frequency, a technology that underlies most modern search engines. In 2019, The New York Times published her belated obituary in its series Overlooked, calling her "a pioneer of computer science for work combining statistics and linguistics, and an advocate for women in the field." From 2008, to recognize her achievements in the fields of IR and NLP, the Karen Spärck Jones Award is awarded to a new recipient with outstanding research in one or both of her fields.

Concept Searching Limited is a software company that specializes in information retrieval software. It has products for Enterprise search, Taxonomy Management and Statistical classification.
A concept search is an automated information retrieval method that is used to search electronically stored unstructured text for information that is conceptually similar to the information provided in a search query. In other words, the ideas expressed in the information retrieved in response to a concept search query are relevant to the ideas contained in the text of the query.
Vector space model or term vector model is an algebraic model for representing text documents as vectors of identifiers. It is used in information filtering, information retrieval, indexing and relevancy rankings. Its first use was in the SMART Information Retrieval System.
Stephen Robertson is a British computer scientist. He is known for his work on information retrieval and the Okapi BM25 weighting model.
The Binary Independence Model (BIM) is a probabilistic information retrieval technique that makes some simple assumptions to make the estimation of document/query similarity probability feasible.
The probabilistic relevance model was devised by Stephen E. Robertson and Karen Spärck Jones as a framework for probabilistic models to come. It is a formalism of information retrieval useful to derive ranking functions used by search engines and web search engines in order to rank matching documents according to their relevance to a given search query.
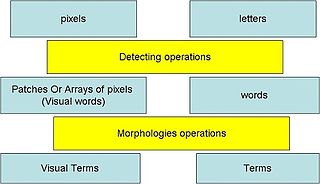
Visual words, as used in image retrieval systems, refer to small parts of an image which carry some kind of information related to the features, or changes occurring in the pixels such as the filtering, low-level feature descriptors.
The following outline is provided as an overview of and topical guide to natural language processing:
References
- ↑ "Lateral Thinking in Information Retrieval" (PDF). Information Management and Technology. 36 PART 4. Archived from the original (PDF) on 2017-11-15. Retrieved 2008-06-20. The British Library Direct catalogue entry can be found here: Archived 2012-02-10 at the Wayback Machine
- ↑ National Statistics CLAMOUR project
- ↑ Robertson, S. E.; Spärck Jones, K. (1976). "Relevance weighting of search terms". Journal of the American Society for Information Science. 27 (3): 129. doi:10.1002/asi.4630270302.
- ↑ WILLIAMS, J.H. (1965). "Results of classifying documents with multiple discriminant functions". Statistical Association Methods for Mechanized Documentation, National Bureau of Standards. Washington: 217–224. Archived from the original on 2011-07-17. Retrieved 2015-05-21.
- ↑ US 20060031195
- ↑ Google Acquires Cuil Patent Applications