
In physics, the Lorentz transformations are a six-parameter family of linear transformations from a coordinate frame in spacetime to another frame that moves at a constant velocity relative to the former. The respective inverse transformation is then parameterized by the negative of this velocity. The transformations are named after the Dutch physicist Hendrik Lorentz.

In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables each of which clusters around a mean value.
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, including the enabling of the user to calculate expectations, covariances using differentiation based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. Sometimes loosely referred to as "the" exponential family, this class of distributions is distinct because they all possess a variety of desirable properties, most importantly the existence of a sufficient statistic.
In statistics, a generalized linear model (GLM) is a flexible generalization of ordinary linear regression. The GLM generalizes linear regression by allowing the linear model to be related to the response variable via a link function and by allowing the magnitude of the variance of each measurement to be a function of its predicted value.
Variational Bayesian methods are a family of techniques for approximating intractable integrals arising in Bayesian inference and machine learning. They are typically used in complex statistical models consisting of observed variables as well as unknown parameters and latent variables, with various sorts of relationships among the three types of random variables, as might be described by a graphical model. As typical in Bayesian inference, the parameters and latent variables are grouped together as "unobserved variables". Variational Bayesian methods are primarily used for two purposes:
- To provide an analytical approximation to the posterior probability of the unobserved variables, in order to do statistical inference over these variables.
- To derive a lower bound for the marginal likelihood of the observed data. This is typically used for performing model selection, the general idea being that a higher marginal likelihood for a given model indicates a better fit of the data by that model and hence a greater probability that the model in question was the one that generated the data.

In nuclear physics, the chiral model, introduced by Feza Gürsey in 1960, is a phenomenological model describing effective interactions of mesons in the chiral limit (where the masses of the quarks go to zero), but without necessarily mentioning quarks at all. It is a nonlinear sigma model with the principal homogeneous space of a Lie group as its target manifold. When the model was originally introduced, this Lie group was the SU(N), where N is the number of quark flavors. The Riemannian metric of the target manifold is given by a positive constant multiplied by the Killing form acting upon the Maurer–Cartan form of SU(N).
In statistics and information theory, a maximum entropy probability distribution has entropy that is at least as great as that of all other members of a specified class of probability distributions. According to the principle of maximum entropy, if nothing is known about a distribution except that it belongs to a certain class, then the distribution with the largest entropy should be chosen as the least-informative default. The motivation is twofold: first, maximizing entropy minimizes the amount of prior information built into the distribution; second, many physical systems tend to move towards maximal entropy configurations over time.
In Bayesian probability, the Jeffreys prior, named after Sir Harold Jeffreys, is a non-informative prior distribution for a parameter space; its density function is proportional to the square root of the determinant of the Fisher information matrix:

In mathematics, the Ornstein–Uhlenbeck process is a stochastic process with applications in financial mathematics and the physical sciences. Its original application in physics was as a model for the velocity of a massive Brownian particle under the influence of friction. It is named after Leonard Ornstein and George Eugene Uhlenbeck.
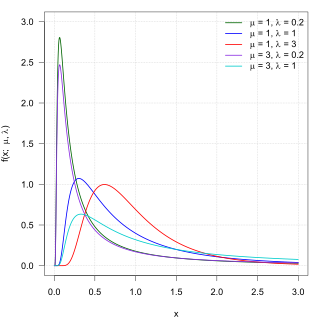
In probability theory, the inverse Gaussian distribution is a two-parameter family of continuous probability distributions with support on (0,∞).
Bayesian linear regression is a type of conditional modeling in which the mean of one variable is described by a linear combination of other variables, with the goal of obtaining the posterior probability of the regression coefficients and ultimately allowing the out-of-sample prediction of the regressandconditional on observed values of the regressors. The simplest and most widely used version of this model is the normal linear model, in which given is distributed Gaussian. In this model, and under a particular choice of prior probabilities for the parameters—so-called conjugate priors—the posterior can be found analytically. With more arbitrarily chosen priors, the posteriors generally have to be approximated.
In statistics, the multivariate t-distribution is a multivariate probability distribution. It is a generalization to random vectors of the Student's t-distribution, which is a distribution applicable to univariate random variables. While the case of a random matrix could be treated within this structure, the matrix t-distribution is distinct and makes particular use of the matrix structure.
In probability and statistics, a natural exponential family (NEF) is a class of probability distributions that is a special case of an exponential family (EF).
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
In probability and statistics, the Tweedie distributions are a family of probability distributions which include the purely continuous normal, gamma and inverse Gaussian distributions, the purely discrete scaled Poisson distribution, and the class of compound Poisson–gamma distributions which have positive mass at zero, but are otherwise continuous. Tweedie distributions are a special case of exponential dispersion models and are often used as distributions for generalized linear models.

In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.

In probability theory and statistics, the Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time or space if these events occur with a known constant mean rate and independently of the time since the last event. It is named after French mathematician Siméon Denis Poisson. The Poisson distribution can also be used for the number of events in other specified interval types such as distance, area, or volume. It plays an important role for discrete-stable distributions.
In probability theory and statistics, the normal-inverse-Wishart distribution is a multivariate four-parameter family of continuous probability distributions. It is the conjugate prior of a multivariate normal distribution with unknown mean and covariance matrix.
In statistics, the variance function is a smooth function that depicts the variance of a random quantity as a function of its mean. The variance function is a measure of heteroscedasticity and plays a large role in many settings of statistical modelling. It is a main ingredient in the generalized linear model framework and a tool used in non-parametric regression, semiparametric regression and functional data analysis. In parametric modeling, variance functions take on a parametric form and explicitly describe the relationship between the variance and the mean of a random quantity. In a non-parametric setting, the variance function is assumed to be a smooth function.






























