In the field of numerical analysis, the condition number of a function with respect to an argument measures how much the output value of the function can change for a small change in the input argument. This is used to measure how sensitive a function is to changes or errors in the input, and how much error in the output results from an error in the input. Very frequently, one is solving the inverse problem – given one is solving for x, and thus the condition number of the (local) inverse must be used. In linear regression the condition number of the moment matrix can be used as a diagnostic for multicollinearity.

In the theory of computation, a branch of theoretical computer science, a pushdown automaton (PDA) is a type of automaton that employs a stack.
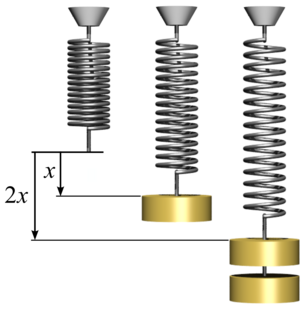
Hooke's law is a law of physics that states that the force needed to extend or compress a spring by some distance x scales linearly with respect to that distance. That is: , where k is a constant factor characteristic of the spring: its stiffness, and x is small compared to the total possible deformation of the spring. The law is named after 17th-century British physicist Robert Hooke. He first stated the law in 1676 as a Latin anagram. He published the solution of his anagram in 1678 as: ut tensio, sic vis. Hooke states in the 1678 work that he was aware of the law already in 1660.

In the theory of computation, a branch of theoretical computer science, a deterministic finite automaton (DFA)—also known as deterministic finite acceptor (DFA), deterministic finite state machine (DFSM), or deterministic finite state automaton (DFSA)—is a finite-state machine that accepts or rejects strings of symbols and only produces a unique computation of the automaton for each input string. Deterministic refers to the uniqueness of the computation. In search of the simplest models to capture finite-state machines, Warren McCulloch and Walter Pitts were among the first researchers to introduce a concept similar to finite automata in 1943.
In automata theory, a finite state machine is called a deterministic finite automaton (DFA), if

Yang–Mills theory is a gauge theory based on the SU(N) group, or more generally any compact, reductive Lie algebra. Yang–Mills theory seeks to describe the behavior of elementary particles using these non-abelian Lie groups and is at the core of the unification of the electromagnetic force and weak forces as well as quantum chromodynamics, the theory of the strong force. Thus it forms the basis of our understanding of the Standard Model of particle physics.
A finite-state transducer (FST) is a finite-state machine with two memory tapes, following the terminology for Turing machines: an input tape and an output tape. This contrasts with an ordinary finite-state automaton, which has a single tape. An FST is a type of finite-state automaton that maps between two sets of symbols. An FST is more general than a finite-state automaton (FSA). An FSA defines a formal language by defining a set of accepted strings while an FST defines relations between sets of strings.
In statistics, econometrics and signal processing, an autoregressive (AR) model is a representation of a type of random process; as such, it is used to describe certain time-varying processes in nature, economics, etc. The autoregressive model specifies that the output variable depends linearly on its own previous values and on a stochastic term ; thus the model is in the form of a stochastic difference equation. In machine learning, an autoregressive model learns from a series of timed steps and takes measurements from previous actions as inputs for a regression model, in order to predict the value of the next time step.
In differential geometry, a tensor density or relative tensor is a generalization of the tensor field concept. A tensor density transforms as a tensor field when passing from one coordinate system to another, except that it is additionally multiplied or weighted by a power W of the Jacobian determinant of the coordinate transition function or its absolute value. A distinction is made among (authentic) tensor densities, pseudotensor densities, even tensor densities and odd tensor densities. Sometimes tensor densities with a negative weight W are called tensor capacity. A tensor density can also be regarded as a section of the tensor product of a tensor bundle with a density bundle.
In automata theory, a deterministic pushdown automaton is a variation of the pushdown automaton. The class of deterministic pushdown automata accepts the deterministic context-free languages, a proper subset of context-free languages.
The Newman–Penrose (NP) formalism is a set of notation developed by Ezra T. Newman and Roger Penrose for general relativity (GR). Their notation is an effort to treat general relativity in terms of spinor notation, which introduces complex forms of the usual variables used in GR. The NP formalism is itself a special case of the tetrad formalism, where the tensors of the theory are projected onto a complete vector basis at each point in spacetime. Usually this vector basis is chosen to reflect some symmetry of the space-time, leading to simplified expressions for physical observables. In the case of the NP formalism, the vector basis chosen is a null tetrad: a set of four null vectors—two real, and a complex-conjugate pair. The two real members asymptotically point radially inward and radially outward, and the formalism is well adapted to treatment of the propagation of radiation in curved spacetime. The most often-used variables in the formalism are the Weyl scalars, derived from the Weyl tensor. In particular, it can be shown that one of these scalars-- in the appropriate frame—encodes the outgoing gravitational radiation of an asymptotically flat system.
In the Newman–Penrose (NP) formalism of general relativity, Weyl scalars refer to a set of five complex scalars which encode the ten independent components of the Weyl tensors of a four-dimensional spacetime.
Effective medium approximations or effective medium theory (EMT) pertain to analytical or theoretical modeling that describes the macroscopic properties of composite materials. EMAs or EMTs are developed from averaging the multiple values of the constituents that directly make up the composite material. At the constituent level, the values of the materials vary and are inhomogeneous. Precise calculation of the many constituent values is nearly impossible. However, theories have been developed that can produce acceptable approximations which in turn describe useful parameters and properties of the composite material as a whole. In this sense, effective medium approximations are descriptions of a medium based on the properties and the relative fractions of its components and are derived from calculations.
In mathematics and theoretical computer science, a semiautomaton is a deterministic finite automaton having inputs but no output. It consists of a set Q of states, a set Σ called the input alphabet, and a function T: Q × Σ → Q called the transition function.
A read-only Turing machine or Two-way deterministic finite-state automaton (2DFA) is class of models of computability that behave like a standard Turing machine and can move in both directions across input, except cannot write to its input tape. The machine in its bare form is equivalent to a Deterministic finite automaton in computational power, and therefore can only parse a regular language.
An embedded pushdown automaton or EPDA is a computational model for parsing languages generated by tree-adjoining grammars (TAGs). It is similar to the context-free grammar-parsing pushdown automaton, except that instead of using a plain stack to store symbols, it has a stack of iterated stacks that store symbols, giving TAGs a generative capacity between context-free grammars and context-sensitive grammars, or a subset of the mildly context-sensitive grammars. Embedded pushdown automata should not be confused with nested stack automata which have more computational power.
In computer science, more specifically in automata and formal language theory, nested words are a concept proposed by Alur and Madhusudan as a joint generalization of words, as traditionally used for modelling linearly ordered structures, and of ordered unranked trees, as traditionally used for modelling hierarchical structures. Finite-state acceptors for nested words, so-called nested word automata, then give a more expressive generalization of finite automata on words. The linear encodings of languages accepted by finite nested word automata gives the class of visibly pushdown languages. The latter language class lies properly between the regular languages and the deterministic context-free languages. Since their introduction in 2004, these concepts have triggered much research in that area.
In the Newman–Penrose (NP) formalism of general relativity, independent components of the Ricci tensors of a four-dimensional spacetime are encoded into seven Ricci scalars which consist of three real scalars , three complex scalars and the NP curvature scalar . Physically, Ricci-NP scalars are related with the energy–momentum distribution of the spacetime due to Einstein's field equation.
Generalized filtering is a generic Bayesian filtering scheme for nonlinear state-space models. It is based on a variational principle of least action, formulated in generalized coordinates. Note that the concept of "generalized coordinates" as used here differs from the concept of generalized coordinates of motion as used in (multibody) dynamical systems analysis. Generalized filtering furnishes posterior densities over hidden states generating observed data using a generalized gradient descent on variational free energy, under the Laplace assumption. Unlike classical filtering, generalized filtering eschews Markovian assumptions about random fluctuations. Furthermore, it operates online, assimilating data to approximate the posterior density over unknown quantities, without the need for a backward pass. Special cases include variational filtering, dynamic expectation maximization and generalized predictive coding.
An enumerator is a Turing machine that lists, possibly with repetitions, elements of some set S, which it is said to enumerate. A set enumerated by some enumerator is said to be recursively enumerable.