In mathematics, the prime number theorem (PNT) describes the asymptotic distribution of the prime numbers among the positive integers. It formalizes the intuitive idea that primes become less common as they become larger by precisely quantifying the rate at which this occurs. The theorem was proved independently by Jacques Hadamard and Charles Jean de la Vallée Poussin in 1896 using ideas introduced by Bernhard Riemann.
In probability theory, Chebyshev's inequality provides an upper bound on the probability of deviation of a random variable from its mean. More specifically, the probability that a random variable deviates from its mean by more than is at most , where is any positive constant and is the standard deviation.

In mathematics, the error function, often denoted by erf, is a function defined as:
In probability theory, Markov's inequality gives an upper bound on the probability that a non-negative random variable is greater than or equal to some positive constant. Markov's inequality is tight in the sense that for each chosen positive constant, there exists a random variable such that the inequality is in fact an equality.

In mathematics, the prime-counting function is the function counting the number of prime numbers less than or equal to some real number x. It is denoted by π(x) (unrelated to the number π).
In probability theory, the Vysochanskij–Petunin inequality gives a lower bound for the probability that a random variable with finite variance lies within a certain number of standard deviations of the variable's mean, or equivalently an upper bound for the probability that it lies further away. The sole restrictions on the distribution are that it be unimodal and have finite variance; here unimodal implies that it is a continuous probability distribution except at the mode, which may have a non-zero probability.
In mathematics, unimodality means possessing a unique mode. More generally, unimodality means there is only a single highest value, somehow defined, of some mathematical object.
In probability theory, the central limit theorem says that, under certain conditions, the sum of many independent identically-distributed random variables, when scaled appropriately, converges in distribution to a standard normal distribution. The martingale central limit theorem generalizes this result for random variables to martingales, which are stochastic processes where the change in the value of the process from time t to time t + 1 has expectation zero, even conditioned on previous outcomes.
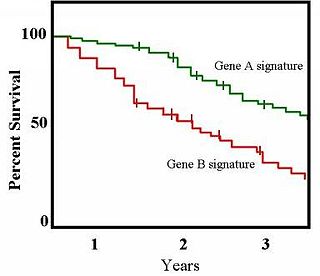
The Kaplan–Meier estimator, also known as the product limit estimator, is a non-parametric statistic used to estimate the survival function from lifetime data. In medical research, it is often used to measure the fraction of patients living for a certain amount of time after treatment. In other fields, Kaplan–Meier estimators may be used to measure the length of time people remain unemployed after a job loss, the time-to-failure of machine parts, or how long fleshy fruits remain on plants before they are removed by frugivores. The estimator is named after Edward L. Kaplan and Paul Meier, who each submitted similar manuscripts to the Journal of the American Statistical Association. The journal editor, John Tukey, convinced them to combine their work into one paper, which has been cited more than 34,000 times since its publication in 1958.

In mathematics, the Chebyshev function is either a scalarising function (Tchebycheff function) or one of two related functions. The first Chebyshev functionϑ (x) or θ (x) is given by
In mathematics, the theory of optimal stopping or early stopping is concerned with the problem of choosing a time to take a particular action, in order to maximise an expected reward or minimise an expected cost. Optimal stopping problems can be found in areas of statistics, economics, and mathematical finance. A key example of an optimal stopping problem is the secretary problem. Optimal stopping problems can often be written in the form of a Bellman equation, and are therefore often solved using dynamic programming.
In mathematics, a local martingale is a type of stochastic process, satisfying the localized version of the martingale property. Every martingale is a local martingale; every bounded local martingale is a martingale; in particular, every local martingale that is bounded from below is a supermartingale, and every local martingale that is bounded from above is a submartingale; however, a local martingale is not in general a martingale, because its expectation can be distorted by large values of small probability. In particular, a driftless diffusion process is a local martingale, but not necessarily a martingale.
In probability theory, Bernstein inequalities give bounds on the probability that the sum of random variables deviates from its mean. In the simplest case, let X1, ..., Xn be independent Bernoulli random variables taking values +1 and −1 with probability 1/2, then for every positive ,
In probability theory, the multidimensional Chebyshev's inequality is a generalization of Chebyshev's inequality, which puts a bound on the probability of the event that a random variable differs from its expected value by more than a specified amount.

Anatoly Alexeyevich Karatsuba was a Russian mathematician working in the field of analytic number theory, p-adic numbers and Dirichlet series.

In mathematics, the modular lambda function λ(τ) is a highly symmetric Holomorphic function on the complex upper half-plane. It is invariant under the fractional linear action of the congruence group Γ(2), and generates the function field of the corresponding quotient, i.e., it is a Hauptmodul for the modular curve X(2). Over any point τ, its value can be described as a cross ratio of the branch points of a ramified double cover of the projective line by the elliptic curve , where the map is defined as the quotient by the [−1] involution.
In probability theory, concentration inequalities provide mathematical bounds on the probability of a random variable deviating from some value.
In statistics and probability theory, the nonparametric skew is a statistic occasionally used with random variables that take real values. It is a measure of the skewness of a random variable's distribution—that is, the distribution's tendency to "lean" to one side or the other of the mean. Its calculation does not require any knowledge of the form of the underlying distribution—hence the name nonparametric. It has some desirable properties: it is zero for any symmetric distribution; it is unaffected by a scale shift; and it reveals either left- or right-skewness equally well. In some statistical samples it has been shown to be less powerful than the usual measures of skewness in detecting departures of the population from normality.
In probability theory, Cantelli's inequality is an improved version of Chebyshev's inequality for one-sided tail bounds. The inequality states that, for
In probability theory, a subgaussian distribution, the distribution of a subgaussian random variable, is a probability distribution with strong tail decay. More specifically, the tails of a subgaussian distribution are dominated by the tails of a Gaussian. This property gives subgaussian distributions their name.



