
In physics, the Lorentz transformations are a six-parameter family of linear transformations from a coordinate frame in spacetime to another frame that moves at a constant velocity relative to the former. The respective inverse transformation is then parameterized by the negative of this velocity. The transformations are named after the Dutch physicist Hendrik Lorentz.
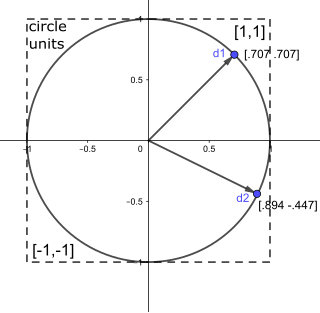
In mathematics, a unit vector in a normed vector space is a vector of length 1. A unit vector is often denoted by a lowercase letter with a circumflex, or "hat", as in .
In mechanics and geometry, the 3D rotation group, often denoted SO(3), is the group of all rotations about the origin of three-dimensional Euclidean space under the operation of composition.
In continuum mechanics, the infinitesimal strain theory is a mathematical approach to the description of the deformation of a solid body in which the displacements of the material particles are assumed to be much smaller than any relevant dimension of the body; so that its geometry and the constitutive properties of the material at each point of space can be assumed to be unchanged by the deformation.
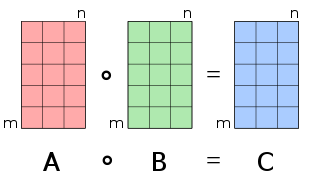
In linear algebra, linear transformations can be represented by matrices. If is a linear transformation mapping to and is a column vector with entries, then
In mathematics, the Kronecker product, sometimes denoted by ⊗, is an operation on two matrices of arbitrary size resulting in a block matrix. It is a specialization of the tensor product from vectors to matrices and gives the matrix of the tensor product linear map with respect to a standard choice of basis. The Kronecker product is to be distinguished from the usual matrix multiplication, which is an entirely different operation. The Kronecker product is also sometimes called matrix direct product.
In statistics, a generalized linear model (GLM) is a flexible generalization of ordinary linear regression. The GLM generalizes linear regression by allowing the linear model to be related to the response variable via a link function and by allowing the magnitude of the variance of each measurement to be a function of its predicted value.
In linear algebra, a rotation matrix is a transformation matrix that is used to perform a rotation in Euclidean space. For example, using the convention below, the matrix

In geometry and linear algebra, a Cartesian tensor uses an orthonormal basis to represent a tensor in a Euclidean space in the form of components. Converting a tensor's components from one such basis to another is done through an orthogonal transformation.
In geometry, various formalisms exist to express a rotation in three dimensions as a mathematical transformation. In physics, this concept is applied to classical mechanics where rotational kinematics is the science of quantitative description of a purely rotational motion. The orientation of an object at a given instant is described with the same tools, as it is defined as an imaginary rotation from a reference placement in space, rather than an actually observed rotation from a previous placement in space.

In mathematics, the axis–angle representation parameterizes a rotation in a three-dimensional Euclidean space by two quantities: a unit vector e indicating the direction (geometry) of an axis of rotation, and an angle of rotation θ describing the magnitude and sense of the rotation about the axis. Only two numbers, not three, are needed to define the direction of a unit vector e rooted at the origin because the magnitude of e is constrained. For example, the elevation and azimuth angles of e suffice to locate it in any particular Cartesian coordinate frame.
In mathematics, the Johnson–Lindenstrauss lemma is a result named after William B. Johnson and Joram Lindenstrauss concerning low-distortion embeddings of points from high-dimensional into low-dimensional Euclidean space. The lemma states that a set of points in a high-dimensional space can be embedded into a space of much lower dimension in such a way that distances between the points are nearly preserved. The map used for the embedding is at least Lipschitz, and can even be taken to be an orthogonal projection.
Non-linear least squares is the form of least squares analysis used to fit a set of m observations with a model that is non-linear in n unknown parameters (m ≥ n). It is used in some forms of nonlinear regression. The basis of the method is to approximate the model by a linear one and to refine the parameters by successive iterations. There are many similarities to linear least squares, but also some significant differences. In economic theory, the non-linear least squares method is applied in (i) the probit regression, (ii) threshold regression, (iii) smooth regression, (iv) logistic link regression, (v) Box–Cox transformed regressors ().
The derivatives of scalars, vectors, and second-order tensors with respect to second-order tensors are of considerable use in continuum mechanics. These derivatives are used in the theories of nonlinear elasticity and plasticity, particularly in the design of algorithms for numerical simulations.
In mathematics, the Hadamard product is a binary operation that takes in two matrices of the same dimensions and returns a matrix of the multiplied corresponding elements. This operation can be thought as a "naive matrix multiplication" and is different from the matrix product. It is attributed to, and named after, either French-Jewish mathematician Jacques Hadamard or German-Jewish mathematician Issai Schur.
Curvilinear coordinates can be formulated in tensor calculus, with important applications in physics and engineering, particularly for describing transportation of physical quantities and deformation of matter in fluid mechanics and continuum mechanics.
In statistics, the class of vector generalized linear models (VGLMs) was proposed to enlarge the scope of models catered for by generalized linear models (GLMs). In particular, VGLMs allow for response variables outside the classical exponential family and for more than one parameter. Each parameter can be transformed by a link function. The VGLM framework is also large enough to naturally accommodate multiple responses; these are several independent responses each coming from a particular statistical distribution with possibly different parameter values.
SAMV is a parameter-free superresolution algorithm for the linear inverse problem in spectral estimation, direction-of-arrival (DOA) estimation and tomographic reconstruction with applications in signal processing, medical imaging and remote sensing. The name was coined in 2013 to emphasize its basis on the asymptotically minimum variance (AMV) criterion. It is a powerful tool for the recovery of both the amplitude and frequency characteristics of multiple highly correlated sources in challenging environments. Applications include synthetic-aperture radar, computed tomography scan, and magnetic resonance imaging (MRI).

In statistics, machine learning and algorithms, a tensor sketch is a type of dimensionality reduction that is particularly efficient when applied to vectors that have tensor structure. Such a sketch can be used to speed up explicit kernel methods, bilinear pooling in neural networks and is a cornerstone in many numerical linear algebra algorithms.
In mathematics, the Khatri–Rao product of matrices is defined as































