
In group theory, the symmetry group of a geometric object is the group of all transformations under which the object is invariant, endowed with the group operation of composition. Such a transformation is an invertible mapping of the ambient space which takes the object to itself, and which preserves all the relevant structure of the object. A frequent notation for the symmetry group of an object X is G = Sym(X).

A shape is a graphical representation of an object's form or its external boundary, outline, or external surface. It is distinct from other object properties, such as color, texture, or material type. In geometry, shape excludes information about the object's position, size, orientation and chirality. A figure is a representation including both shape and size.
In mathematical physics, a closed timelike curve (CTC) is a world line in a Lorentzian manifold, of a material particle in spacetime, that is "closed", returning to its starting point. This possibility was first discovered by Willem Jacob van Stockum in 1937 and later confirmed by Kurt Gödel in 1949, who discovered a solution to the equations of general relativity (GR) allowing CTCs known as the Gödel metric; and since then other GR solutions containing CTCs have been found, such as the Tipler cylinder and traversable wormholes. If CTCs exist, their existence would seem to imply at least the theoretical possibility of time travel backwards in time, raising the spectre of the grandfather paradox, although the Novikov self-consistency principle seems to show that such paradoxes could be avoided. Some physicists speculate that the CTCs which appear in certain GR solutions might be ruled out by a future theory of quantum gravity which would replace GR, an idea which Stephen Hawking labeled the chronology protection conjecture. Others note that if every closed timelike curve in a given spacetime passes through an event horizon, a property which can be called chronological censorship, then that spacetime with event horizons excised would still be causally well behaved and an observer might not be able to detect the causal violation.

In computer graphics and computational geometry, a bounding volume for a set of objects is a closed region that completely contains the union of the objects in the set. Bounding volumes are used to improve the efficiency of geometrical operations, such as by using simple regions, having simpler ways to test for overlap.
The scale-invariant feature transform (SIFT) is a computer vision algorithm to detect, describe, and match local features in images, invented by David Lowe in 1999. Applications include object recognition, robotic mapping and navigation, image stitching, 3D modeling, gesture recognition, video tracking, individual identification of wildlife and match moving.

Ambiguous images or reversible figures are visual forms that create ambiguity by exploiting graphical similarities and other properties of visual system interpretation between two or more distinct image forms. These are famous for inducing the phenomenon of multistable perception. Multistable perception is the occurrence of an image being able to provide multiple, although stable, perceptions.
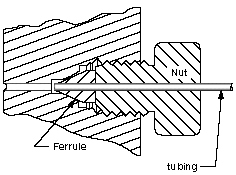
In geometry and science, a cross section is the non-empty intersection of a solid body in three-dimensional space with a plane, or the analog in higher-dimensional spaces. Cutting an object into slices creates many parallel cross-sections. The boundary of a cross-section in three-dimensional space that is parallel to two of the axes, that is, parallel to the plane determined by these axes, is sometimes referred to as a contour line; for example, if a plane cuts through mountains of a raised-relief map parallel to the ground, the result is a contour line in two-dimensional space showing points on the surface of the mountains of equal elevation.
Scale-space theory is a framework for multi-scale signal representation developed by the computer vision, image processing and signal processing communities with complementary motivations from physics and biological vision. It is a formal theory for handling image structures at different scales, by representing an image as a one-parameter family of smoothed images, the scale-space representation, parametrized by the size of the smoothing kernel used for suppressing fine-scale structures. The parameter in this family is referred to as the scale parameter, with the interpretation that image structures of spatial size smaller than about have largely been smoothed away in the scale-space level at scale .
In computer vision and image processing, a feature is a piece of information about the content of an image; typically about whether a certain region of the image has certain properties. Features may be specific structures in the image such as points, edges or objects. Features may also be the result of a general neighborhood operation or feature detection applied to the image. Other examples of features are related to motion in image sequences, or to shapes defined in terms of curves or boundaries between different image regions.
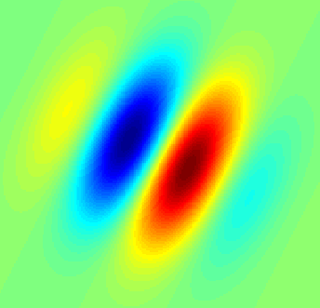
A simple cell in the primary visual cortex is a cell that responds primarily to oriented edges and gratings. These cells were discovered by Torsten Wiesel and David Hubel in the late 1950s.
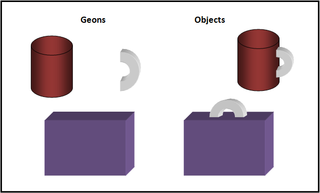
The recognition-by-components theory, or RBC theory, is a process proposed by Irving Biederman in 1987 to explain object recognition. According to RBC theory, we are able to recognize objects by separating them into geons. Biederman suggested that geons are based on basic 3-dimensional shapes that can be assembled in various arrangements to form a virtually unlimited number of objects.
Object recognition – technology in the field of computer vision for finding and identifying objects in an image or video sequence. Humans recognize a multitude of objects in images with little effort, despite the fact that the image of the objects may vary somewhat in different view points, in many different sizes and scales or even when they are translated or rotated. Objects can even be recognized when they are partially obstructed from view. This task is still a challenge for computer vision systems. Many approaches to the task have been implemented over multiple decades.
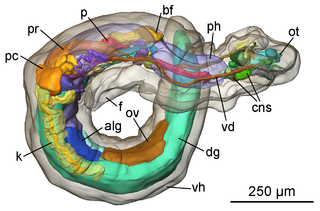
In computer vision and computer graphics, 3D reconstruction is the process of capturing the shape and appearance of real objects. This process can be accomplished either by active or passive methods. If the model is allowed to change its shape in time, this is referred to as non-rigid or spatio-temporal reconstruction.
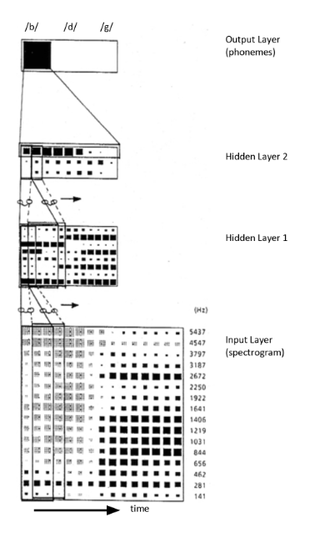
Time delay neural network (TDNN) is a multilayer artificial neural network architecture whose purpose is to 1) classify patterns with shift-invariance, and 2) model context at each layer of the network.
Visual object recognition refers to the ability to identify the objects in view based on visual input. One important signature of visual object recognition is "object invariance", or the ability to identify objects across changes in the detailed context in which objects are viewed, including changes in illumination, object pose, and background context.
Form perception is the recognition of visual elements of objects, specifically those to do with shapes, patterns and previously identified important characteristics. An object is perceived by the retina as a two-dimensional image, but the image can vary for the same object in terms of the context with which it is viewed, the apparent size of the object, the angle from which it is viewed, how illuminated it is, as well as where it resides in the field of vision. Despite the fact that each instance of observing an object leads to a unique retinal response pattern, the visual processing in the brain is capable of recognizing these experiences as analogous, allowing invariant object recognition. Visual processing occurs in a hierarchy with the lowest levels recognizing lines and contours, and slightly higher levels performing tasks such as completing boundaries and recognizing contour combinations. The highest levels integrate the perceived information to recognize an entire object. Essentially object recognition is the ability to assign labels to objects in order to categorize and identify them, thus distinguishing one object from another. During visual processing information is not created, but rather reformatted in a way that draws out the most detailed information of the stimulus.
Representational momentum is a small, but reliable, error in our visual perception of moving objects. Representational moment was discovered and named by Jennifer Freyd and Ronald Finke. Instead of knowing the exact location of a moving object, viewers actually think it is a bit further along its trajectory as time goes forward. For example, people viewing an object moving from left to right that suddenly disappears will report they saw it a bit further to the right than where it actually vanished. While not a big error, it has been found in a variety of different events ranging from simple rotations to camera movement through a scene. The name "representational momentum" initially reflected the idea that the forward displacement was the result of the perceptual system having internalized, or evolved to include, basic principles of Newtonian physics, but it has come to mean forward displacements that continue a presented pattern along a variety of dimensions, not just position or orientation. As with many areas of cognitive psychology, theories can focus on bottom-up or top-down aspects of the task. Bottom-up theories of representational momentum highlight the role of eye movements and stimulus presentation, while top-down theories highlight the role of the observer's experience and expectations regarding the presented event.
In visual perception, structure from motion (SFM) refers to how humans recover depth structure from object's motion. The human visual field has an important function: capturing the three-dimensional structures of an object using different kinds of visual cues.

An accidental viewpoint is a singular position from which an image can be perceived, creating either an ambiguous image or an illusion. The image perceived at this angle is viewpoint-specific, meaning it cannot be perceived at any other position, known as generic or non-accidental viewpoints. These view-specific angles are involved in object recognition. In its uses in art and other visual illusions, the accidental viewpoint creates the perception of depth often on a two-dimensional surface with the assistance of monocular cues.
Geometrical Product Specification and Verification (GPS&V) is a set of ISO standards developed by ISO Technical Committee 213. The aim of those standards is to develop a common language to specify macro geometry and micro-geometry of products or parts of products so that the language can be used consistently worldwide.

