
In probability theory and statistics, the cumulative distribution function (CDF) of a real-valued random variable , or just distribution function of , evaluated at , is the probability that will take a value less than or equal to .
In probability theory, the expected value of a random variable, intuitively, is the long-run average value of repetitions of the same experiment it represents. For example, the expected value in rolling a six-sided die is 3.5, because the average of all the numbers that come up is 3.5 as the number of rolls approaches infinity. In other words, the law of large numbers states that the arithmetic mean of the values almost surely converges to the expected value as the number of repetitions approaches infinity. The expected value is also known as the expectation, mathematical expectation, EV, average, mean value, mean, or first moment.

Information entropy is the average rate at which information is produced by a stochastic source of data.
In probability theory, the central limit theorem (CLT) establishes that, in some situations, when independent random variables are added, their properly normalized sum tends toward a normal distribution even if the original variables themselves are not normally distributed. The theorem is a key concept in probability theory because it implies that probabilistic and statistical methods that work for normal distributions can be applicable to many problems involving other types of distributions.
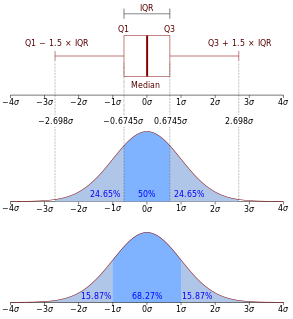
In probability theory, a probability density function (PDF), or density of a continuous random variable, is a function whose value at any given sample in the sample space can be interpreted as providing a relative likelihood that the value of the random variable would equal that sample. In other words, while the absolute likelihood for a continuous random variable to take on any particular value is 0, the value of the PDF at two different samples can be used to infer, in any particular draw of the random variable, how much more likely it is that the random variable would equal one sample compared to the other sample.
In probability theory, there exist several different notions of convergence of random variables. The convergence of sequences of random variables to some limit random variable is an important concept in probability theory, and its applications to statistics and stochastic processes. The same concepts are known in more general mathematics as stochastic convergence and they formalize the idea that a sequence of essentially random or unpredictable events can sometimes be expected to settle down into a behavior that is essentially unchanging when items far enough into the sequence are studied. The different possible notions of convergence relate to how such a behavior can be characterized: two readily understood behaviors are that the sequence eventually takes a constant value, and that values in the sequence continue to change but can be described by an unchanging probability distribution.
In probability theory, Chebyshev's inequality guarantees that, for a wide class of probability distributions, no more than a certain fraction of values can be more than a certain distance from the mean. Specifically, no more than 1/k2 of the distribution's values can be more than k standard deviations away from the mean. The rule is often called Chebyshev's theorem, about the range of standard deviations around the mean, in statistics. The inequality has great utility because it can be applied to any probability distribution in which the mean and variance are defined. For example, it can be used to prove the weak law of large numbers.
In numerical analysis and computational statistics, rejection sampling is a basic technique used to generate observations from a distribution. It is also commonly called the acceptance-rejection method or "accept-reject algorithm" and is a type of exact simulation method. The method works for any distribution in with a density.
A Dynkin system, named after Eugene Dynkin, is a collection of subsets of another universal set satisfying a set of axioms weaker than those of σ-algebra. Dynkin systems are sometimes referred to as λ-systems or d-system. These set families have applications in measure theory and probability.
Differential entropy is a concept in information theory that began as an attempt by Shannon to extend the idea of (Shannon) entropy, a measure of average surprisal of a random variable, to continuous probability distributions. Unfortunately, Shannon did not derive this formula, and rather just assumed it was the correct continuous analogue of discrete entropy, but it is not. The actual continuous version of discrete entropy is the limiting density of discrete points (LDDP). Differential entropy is commonly encountered in the literature, but it is a limiting case of the LDDP, and one that loses its fundamental association with discrete entropy.
In mathematics, a π-system on a set Ω is a collection P of certain subsets of Ω, such that
In probability theory, an indecomposable distribution is a probability distribution that cannot be represented as the distribution of the sum of two or more non-constant independent random variables: Z ≠ X + Y. If it can be so expressed, it is decomposable:Z = X + Y. If, further, it can be expressed as the distribution of the sum of two or more independent identically distributed random variables, then it is divisible:Z = X1 + X2.
In statistics, the probability integral transform or transformation relates to the result that data values that are modelled as being random variables from any given continuous distribution can be converted to random variables having a standard uniform distribution. This holds exactly provided that the distribution being used is the true distribution of the random variables; if the distribution is one fitted to the data, the result will hold approximately in large samples.
In mathematics, uniform integrability is an important concept in real analysis, functional analysis and measure theory, and plays a vital role in the theory of martingales. The definition used in measure theory is closely related to, but not identical to, the definition typically used in probability.
In probability theory and statistics, a stochastic order quantifies the concept of one random variable being "bigger" than another. These are usually partial orders, so that one random variable may be neither stochastically greater than, less than nor equal to another random variable . Many different orders exist, which have different applications.
In probability theory, Kolmogorov's Three-Series Theorem, named after Andrey Kolmogorov, gives a criterion for the almost sure convergence of an infinite series of random variables in terms of the convergence of three different series involving properties of their probability distributions. Kolmogorov's three-series theorem, combined with Kronecker's lemma, can be used to give a relatively easy proof of the Strong Law of Large Numbers.
A product distribution is a probability distribution constructed as the distribution of the product of random variables having two other known distributions. Given two statistically independent random variables X and Y, the distribution of the random variable Z that is formed as the product
In probability theory and statistics, a collection of random variables is independent and identically distributed if each random variable has the same probability distribution as the others and all are mutually independent. This property is usually abbreviated as i.i.d. or iid or IID. Herein, i.i.d. is used, because it is the most prevalent.















