Related Research Articles
Instructions per second (IPS) is a measure of a computer's processor speed. For complex instruction set computers (CISCs), different instructions take different amounts of time, so the value measured depends on the instruction mix; even for comparing processors in the same family the IPS measurement can be problematic. Many reported IPS values have represented "peak" execution rates on artificial instruction sequences with few branches and no cache contention, whereas realistic workloads typically lead to significantly lower IPS values. Memory hierarchy also greatly affects processor performance, an issue barely considered in IPS calculations. Because of these problems, synthetic benchmarks such as Dhrystone are now generally used to estimate computer performance in commonly used applications, and raw IPS has fallen into disuse.

A supercomputer is a computer with a high level of performance as compared to a general-purpose computer. The performance of a supercomputer is commonly measured in floating-point operations per second (FLOPS) instead of million instructions per second (MIPS). Since 2017, there have existed supercomputers which can perform over 1017 FLOPS (a hundred quadrillion FLOPS, 100 petaFLOPS or 100 PFLOPS). For comparison, a desktop computer has performance in the range of hundreds of gigaFLOPS (1011) to tens of teraFLOPS (1013). Since November 2017, all of the world's fastest 500 supercomputers run on Linux-based operating systems. Additional research is being conducted in the United States, the European Union, Taiwan, Japan, and China to build faster, more powerful and technologically superior exascale supercomputers.

Single instruction, multiple data (SIMD) is a type of parallel processing in Flynn's taxonomy. SIMD can be internal and it can be directly accessible through an instruction set architecture (ISA), but it should not be confused with an ISA. SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously.

In computing, floating point operations per second is a measure of computer performance, useful in fields of scientific computations that require floating-point calculations. For such cases, it is a more accurate measure than measuring instructions per second.

A system on a chip or system-on-chip is an integrated circuit that integrates most or all components of a computer or other electronic system. These components almost always include on-chip central processing unit (CPU), memory interfaces, input/output devices, input/output interfaces, and secondary storage interfaces, often alongside other components such as radio modems and a graphics processing unit (GPU) – all on a single substrate or microchip. SoCs may contain digital, and also analog, mixed-signal, and often radio frequency signal processing functions.
In computer science, algorithmic efficiency is a property of an algorithm which relates to the amount of computational resources used by the algorithm. An algorithm must be analyzed to determine its resource usage, and the efficiency of an algorithm can be measured based on the usage of different resources. Algorithmic efficiency can be thought of as analogous to engineering productivity for a repeating or continuous process.
Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
Cell is a 64-bit multi-core microprocessor microarchitecture that combines a general-purpose PowerPC core of modest performance with streamlined coprocessing elements which greatly accelerate multimedia and vector processing applications, as well as many other forms of dedicated computation.

High-performance computing (HPC) uses supercomputers and computer clusters to solve advanced computation problems.

ASCI Red was the first computer built under the Accelerated Strategic Computing Initiative (ASCI), the supercomputing initiative of the United States government created to help the maintenance of the United States nuclear arsenal after the 1992 moratorium on nuclear testing.

In computing, a benchmark is the act of running a computer program, a set of programs, or other operations, in order to assess the relative performance of an object, normally by running a number of standard tests and trials against it.

The NASA Advanced Supercomputing (NAS) Division is located at NASA Ames Research Center, Moffett Field in the heart of Silicon Valley in Mountain View, California. It has been the major supercomputing and modeling and simulation resource for NASA missions in aerodynamics, space exploration, studies in weather patterns and ocean currents, and space shuttle and aircraft design and development for almost forty years.

A multi-core processor is a microprocessor on a single integrated circuit with two or more separate processing units, called cores, each of which reads and executes program instructions. The instructions are ordinary CPU instructions but the single processor can run instructions on separate cores at the same time, increasing overall speed for programs that support multithreading or other parallel computing techniques. Manufacturers typically integrate the cores onto a single integrated circuit die or onto multiple dies in a single chip package. The microprocessors currently used in almost all personal computers are multi-core.
In computing, computer performance is the amount of useful work accomplished by a computer system. Outside of specific contexts, computer performance is estimated in terms of accuracy, efficiency and speed of executing computer program instructions. When it comes to high computer performance, one or more of the following factors might be involved:
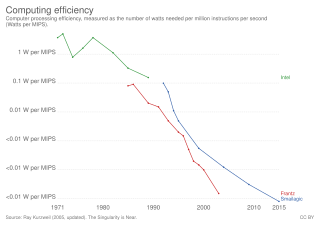
In computing, performance per watt is a measure of the energy efficiency of a particular computer architecture or computer hardware. Literally, it measures the rate of computation that can be delivered by a computer for every watt of power consumed. This rate is typically measured by performance on the LINPACK benchmark when trying to compare between computing systems: an example using this is the Green500 list of supercomputers. Performance per watt has been suggested to be a more sustainable measure of computing than Moore’s Law.

A computer cluster is a set of computers that work together so that they can be viewed as a single system. Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by software.

In computer science, computer architecture is a description of the structure of a computer system made from component parts. It can sometimes be a high-level description that ignores details of the implementation. At a more detailed level, the description may include the instruction set architecture design, microarchitecture design, logic design, and implementation.

The term supercomputing arose in the late 1920s in the United States in response to the IBM tabulators at Columbia University. The CDC 6600, released in 1964, is sometimes considered the first supercomputer. However, some earlier computers were considered supercomputers for their day such as the 1954 IBM NORC in the 1950s, and in the early 1960s, the UNIVAC LARC (1960), the IBM 7030 Stretch (1962), and the Manchester Atlas (1962), all of which were of comparable power.

Approaches to supercomputer architecture have taken dramatic turns since the earliest systems were introduced in the 1960s. Early supercomputer architectures pioneered by Seymour Cray relied on compact innovative designs and local parallelism to achieve superior computational peak performance. However, in time the demand for increased computational power ushered in the age of massively parallel systems.
References
- ↑ Gustafson, J. L.; Snell, Q. O. (1995). "HINT: A new way to measure computer performance". Proceedings of the Twenty-Eighth Hawaii International Conference on System Sciences. pp. 392–401. doi:10.1109/HICSS.1995.375519. ISBN 0-8186-6935-7. S2CID 17572925.
- ↑ Gustafson, J. (2004). "Purpose-based benchmarks" (PDF). The International Journal of High Performance Computing Applications. 18 (4): 475–487. CiteSeerX 10.1.1.684.150 . doi:10.1177/1094342004048540. S2CID 5786180. See pages 5, 11.
- ↑ John L. Gustafson, Quinn O. Snell, and Rajat Todi. "The HINT Benchmark".
- ↑ Gustafson, John; Snell, Quinn; Heller, Don. (2 September 1999). "Scalable Computer Performance and Analysis (Hierarchical INTegration). Computer software" (Document). DOE/ER. OSTI 1230480.