
A supercomputer is a computer with a high level of performance as compared to a general-purpose computer. The performance of a supercomputer is commonly measured in floating-point operations per second (FLOPS) instead of million instructions per second (MIPS). Since 2017, supercomputers have existed which can perform over 1017 FLOPS (a hundred quadrillion FLOPS, 100 petaFLOPS or 100 PFLOPS). For comparison, a desktop computer has performance in the range of hundreds of gigaFLOPS (1011) to tens of teraFLOPS (1013). Since November 2017, all of the world's fastest 500 supercomputers run on Linux-based operating systems. Additional research is being conducted in the United States, the European Union, Taiwan, Japan, and China to build faster, more powerful and technologically superior exascale supercomputers.

In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system. In many cases, a thread is a component of a process.

Symmetric multiprocessing or shared-memory multiprocessing (SMP) involves a multiprocessor computer hardware and software architecture where two or more identical processors are connected to a single, shared main memory, have full access to all input and output devices, and are controlled by a single operating system instance that treats all processors equally, reserving none for special purposes. Most multiprocessor systems today use an SMP architecture. In the case of multi-core processors, the SMP architecture applies to the cores, treating them as separate processors.
Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
In computing, scheduling is the action of assigning resources to perform tasks. The resources may be processors, network links or expansion cards. The tasks may be threads, processes or data flows.

In computer science, distributed memory refers to a multiprocessor computer system in which each processor has its own private memory. Computational tasks can only operate on local data, and if remote data are required, the computational task must communicate with one or more remote processors. In contrast, a shared memory multiprocessor offers a single memory space used by all processors. Processors do not have to be aware where data resides, except that there may be performance penalties, and that race conditions are to be avoided.
In mathematical analysis, a space-filling curve is a curve whose range reaches every point in a higher dimensional region, typically the unit square. Because Giuseppe Peano (1858–1932) was the first to discover one, space-filling curves in the 2-dimensional plane are sometimes called Peano curves, but that phrase also refers to the Peano curve, the specific example of a space-filling curve found by Peano.
In computing, single program, multiple data (SPMD) is a term that has been used to refer to computational models for exploiting parallelism where-by multiple processors cooperate in the execution of a program in order to obtain results faster.

The Hilbert curve is a continuous fractal space-filling curve first described by the German mathematician David Hilbert in 1891, as a variant of the space-filling Peano curves discovered by Giuseppe Peano in 1890.

The Gosper curve, named after Bill Gosper, also known as the Peano-Gosper Curve and the flowsnake, is a space-filling curve whose limit set is rep-7. It is a fractal curve similar in its construction to the dragon curve and the Hilbert curve.
The Parallel Virtual File System (PVFS) is an open-source parallel file system. A parallel file system is a type of distributed file system that distributes file data across multiple servers and provides for concurrent access by multiple tasks of a parallel application. PVFS was designed for use in large scale cluster computing. PVFS focuses on high performance access to large data sets. It consists of a server process and a client library, both of which are written entirely of user-level code. A Linux kernel module and pvfs-client process allow the file system to be mounted and used with standard utilities. The client library provides for high performance access via the message passing interface (MPI). PVFS is being jointly developed between The Parallel Architecture Research Laboratory at Clemson University and the Mathematics and Computer Science Division at Argonne National Laboratory, and the Ohio Supercomputer Center. PVFS development has been funded by NASA Goddard Space Flight Center, The DOE Office of Science Advanced Scientific Computing Research program, NSF PACI and HECURA programs, and other government and private agencies. PVFS is now known as OrangeFS in its newest development branch.
Hilbert R-tree, an R-tree variant, is an index for multidimensional objects such as lines, regions, 3-D objects, or high-dimensional feature-based parametric objects. It can be thought of as an extension to B+-tree for multidimensional objects.

Magerit is one of the most powerful supercomputers in Spain. It also reached the second best Spanish position in the TOP500 list of supercomputers. It is installed in CeSViMa, a research center of the Technical University of Madrid.

A computer cluster is a set of computers that work together so that they can be viewed as a single system. Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by software. The newest manifestation of cluster computing is cloud computing.
Manycore processors are special kinds of multi-core processors designed for a high degree of parallel processing, containing numerous simpler, independent processor cores. Manycore processors are used extensively in embedded computers and high-performance computing.

The Slurm Workload Manager, formerly known as Simple Linux Utility for Resource Management (SLURM), or simply Slurm, is a free and open-source job scheduler for Linux and Unix-like kernels, used by many of the world's supercomputers and computer clusters.

Compute Node Kernel (CNK) is the node level operating system for the IBM Blue Gene series of supercomputers.
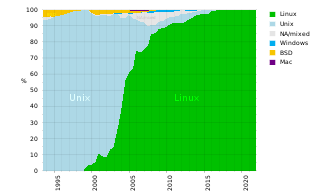
A supercomputer operating system is an operating system intended for supercomputers. Since the end of the 20th century, supercomputer operating systems have undergone major transformations, as fundamental changes have occurred in supercomputer architecture. While early operating systems were custom tailored to each supercomputer to gain speed, the trend has been moving away from in-house operating systems and toward some form of Linux, with it running all the supercomputers on the TOP500 list in November 2017. In 2021, top 10 computers run for instance Red Hat Enterprise Linux (RHEL), or some variant of it or other Linux distribution e.g. Ubuntu.
Massively parallel is the term for using a large number of computer processors to simultaneously perform a set of coordinated computations in parallel. GPUs are massively parallel architecture with tens of thousands of threads.
Message passing is an inherent element of all computer clusters. All computer clusters, ranging from homemade Beowulfs to some of the fastest supercomputers in the world, rely on message passing to coordinate the activities of the many nodes they encompass. Message passing in computer clusters built with commodity servers and switches is used by virtually every internet service.
