Related Research Articles
In computer science, an array is a data structure consisting of a collection of elements, of same memory size, each identified by at least one array index or key. An array is stored such that the position of each element can be computed from its index tuple by a mathematical formula. The simplest type of data structure is a linear array, also called one-dimensional array.

In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.

A hash function is any function that can be used to map data of arbitrary size to fixed-size values, though there are some hash functions that support variable length output. The values returned by a hash function are called hash values, hash codes, hash digests, digests, or simply hashes. The values are usually used to index a fixed-size table called a hash table. Use of a hash function to index a hash table is called hashing or scatter storage addressing.

In computing, a hash table is a data structure that implements an associative array, also called a dictionary or simply map, which is an abstract data type that maps keys to values. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored.
In computer science, an associative array, map, symbol table, or dictionary is an abstract data type that stores a collection of pairs, such that each possible key appears at most once in the collection. In mathematical terms, an associative array is a function with finite domain. It supports 'lookup', 'remove', and 'insert' operations.
In computing, inline expansion, or inlining, is a manual or compiler optimization that replaces a function call site with the body of the called function. Inline expansion is similar to macro expansion, but occurs during compilation, without changing the source code, while macro expansion occurs prior to compilation, and results in different text that is then processed by the compiler.

In computer science, a perfect hash functionh for a set S is a hash function that maps distinct elements in S to a set of m integers, with no collisions. In mathematical terms, it is an injective function.
In computer science, a lookup table (LUT) is an array that replaces runtime computation with a simpler array indexing operation, in a process termed as direct addressing. The savings in processing time can be significant, because retrieving a value from memory is often faster than carrying out an "expensive" computation or input/output operation. The tables may be precalculated and stored in static program storage, calculated as part of a program's initialization phase (memoization), or even stored in hardware in application-specific platforms. Lookup tables are also used extensively to validate input values by matching against a list of valid items in an array and, in some programming languages, may include pointer functions to process the matching input. FPGAs also make extensive use of reconfigurable, hardware-implemented, lookup tables to provide programmable hardware functionality. LUTs differ from hash tables in a way that, to retrieve a value with key , a hash table would store the value in the slot where is a hash function i.e. is used to compute the slot, while in the case of LUT, the value is stored in slot , thus directly addressable.

In computer programming, foreach loop is a control flow statement for traversing items in a collection. foreach is usually used in place of a standard for loop statement. Unlike other for loop constructs, however, foreach loops usually maintain no explicit counter: they essentially say "do this to everything in this set", rather than "do this x times". This avoids potential off-by-one errors and makes code simpler to read. In object-oriented languages, an iterator, even if implicit, is often used as the means of traversal.

In computer science, a radix tree is a data structure that represents a space-optimized trie in which each node that is the only child is merged with its parent. The result is that the number of children of every internal node is at most the radix r of the radix tree, where r = 2x for some integer x ≥ 1. Unlike regular trees, edges can be labeled with sequences of elements as well as single elements. This makes radix trees much more efficient for small sets and for sets of strings that share long prefixes.

Open addressing, or closed hashing, is a method of collision resolution in hash tables. With this method a hash collision is resolved by probing, or searching through alternative locations in the array until either the target record is found, or an unused array slot is found, which indicates that there is no such key in the table. Well-known probe sequences include:
In computer programming languages, a switch statement is a type of selection control mechanism used to allow the value of a variable or expression to change the control flow of program execution via search and map.

In computer science, recursion is a method of solving a computational problem where the solution depends on solutions to smaller instances of the same problem. Recursion solves such recursive problems by using functions that call themselves from within their own code. The approach can be applied to many types of problems, and recursion is one of the central ideas of computer science.
The power of recursion evidently lies in the possibility of defining an infinite set of objects by a finite statement. In the same manner, an infinite number of computations can be described by a finite recursive program, even if this program contains no explicit repetitions.
The C and C++ programming languages are closely related but have many significant differences. C++ began as a fork of an early, pre-standardized C, and was designed to be mostly source-and-link compatible with C compilers of the time. Due to this, development tools for the two languages are often integrated into a single product, with the programmer able to specify C or C++ as their source language.
In computer programming, a branch table or jump table is a method of transferring program control (branching) to another part of a program using a table of branch or jump instructions. It is a form of multiway branch. The branch table construction is commonly used when programming in assembly language but may also be generated by compilers, especially when implementing optimized switch statements whose values are densely packed together.
This comparison of programming languages (associative arrays) compares the features of associative array data structures or array-lookup processing for over 40 computer programming languages.

Control tables are tables that control the control flow or play a major part in program control. There are no rigid rules about the structure or content of a control table—its qualifying attribute is its ability to direct control flow in some way through "execution" by a processor or interpreter. The design of such tables is sometimes referred to as table-driven design. In some cases, control tables can be specific implementations of finite-state-machine-based automata-based programming. If there are several hierarchical levels of control table they may behave in a manner equivalent to UML state machines
Multiway branch is the change to a program's control flow based upon a value matching a selected criteria. It is a form of conditional statement. A multiway branch is often the most efficient method of passing control to one of a set of program labels, especially if an index has been created beforehand from the raw data.
In computer science, tabulation hashing is a method for constructing universal families of hash functions by combining table lookup with exclusive or operations. It was first studied in the form of Zobrist hashing for computer games; later work by Carter and Wegman extended this method to arbitrary fixed-length keys. Generalizations of tabulation hashing have also been developed that can handle variable-length keys such as text strings.
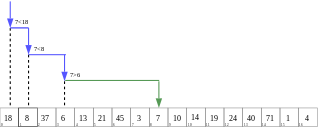
In computer science, multiplicative binary search is a variation of binary search that uses a specific permutation of keys in an array instead of the sorted order used by regular binary search. Multiplicative binary search was first described by Thomas Standish in 1980. This algorithm was originally proposed to simplify the midpoint index calculation on small computers without efficient division or shift operations. On modern hardware, the cache-friendly nature of multiplicative binary search makes it suitable for out-of-core search on block-oriented storage as an alternative to B-trees and B+ trees. For optimal performance, the branching factor of a B-tree or B+-tree must match the block size of the file system that it is stored on. The permutation used by multiplicative binary search places the optimal number of keys in the first (root) block, regardless of block size.
References
- ↑ Cormen, Thomas H. (2009). Introduction to algorithms (3rd ed.). Cambridge, Mass.: MIT Press. pp. 253–255. ISBN 9780262033848 . Retrieved 26 November 2015.
- ↑ Sayle, Roger Anthony (June 17, 2008). "A Superoptimizer Analysis of Multiway Branch Code Generation" (PDF). Proceedings of the GCC Developers' Summit: 103–116. Retrieved 26 November 2015.