
Genetics is a branch of biology concerned with the study of genes, genetic variation, and heredity in organisms.
In biology, a mutation is an alteration in the nucleic acid sequence of the genome of an organism, virus, or extrachromosomal DNA. Viral genomes contain either DNA or RNA. Mutations result from errors during DNA or viral replication, mitosis, or meiosis or other types of damage to DNA, which then may undergo error-prone repair, cause an error during other forms of repair, or cause an error during replication. Mutations may also result from insertion or deletion of segments of DNA due to mobile genetic elements.
A microsatellite is a tract of repetitive DNA in which certain DNA motifs are repeated, typically 5–50 times. Microsatellites occur at thousands of locations within an organism's genome. They have a higher mutation rate than other areas of DNA leading to high genetic diversity. Microsatellites are often referred to as short tandem repeats (STRs) by forensic geneticists and in genetic genealogy, or as simple sequence repeats (SSRs) by plant geneticists.

Molecular evolution is the process of change in the sequence composition of cellular molecules such as DNA, RNA, and proteins across generations. The field of molecular evolution uses principles of evolutionary biology and population genetics to explain patterns in these changes. Major topics in molecular evolution concern the rates and impacts of single nucleotide changes, neutral evolution vs. natural selection, origins of new genes, the genetic nature of complex traits, the genetic basis of speciation, evolution of development, and ways that evolutionary forces influence genomic and phenotypic changes.
The neutral theory of molecular evolution holds that most evolutionary changes occur at the molecular level, and most of the variation within and between species are due to random genetic drift of mutant alleles that are selectively neutral. The theory applies only for evolution at the molecular level, and is compatible with phenotypic evolution being shaped by natural selection as postulated by Charles Darwin. The neutral theory allows for the possibility that most mutations are deleterious, but holds that because these are rapidly removed by natural selection, they do not make significant contributions to variation within and between species at the molecular level. A neutral mutation is one that does not affect an organism's ability to survive and reproduce. The neutral theory assumes that most mutations that are not deleterious are neutral rather than beneficial. Because only a fraction of gametes are sampled in each generation of a species, the neutral theory suggests that a mutant allele can arise within a population and reach fixation by chance, rather than by selective advantage.
Population genetics is a subfield of genetics that deals with genetic differences within and between populations, and is a part of evolutionary biology. Studies in this branch of biology examine such phenomena as adaptation, speciation, and population structure.
A genetic screen or mutagenesis screen is an experimental technique used to identify and select for individuals who possess a phenotype of interest in a mutagenized population. Hence a genetic screen is a type of phenotypic screen. Genetic screens can provide important information on gene function as well as the molecular events that underlie a biological process or pathway. While genome projects have identified an extensive inventory of genes in many different organisms, genetic screens can provide valuable insight as to how those genes function.
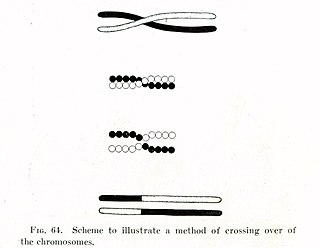
In evolutionary genetics, Muller's ratchet is a process through which, in the absence of recombination, an accumulation of irreversible deleterious mutations results. This happens due to the fact that in the absence of recombination, and assuming reverse mutations are rare, offspring bear at least as much mutational load as their parents. Muller proposed this mechanism as one reason why sexual reproduction may be favored over asexual reproduction, as sexual organisms benefit from recombination and consequent elimination of deleterious mutations. The negative effect of accumulating irreversible deleterious mutations may not be prevalent in organisms which, while they reproduce asexually, also undergo other forms of recombination. This effect has also been observed in those regions of the genomes of sexual organisms that do not undergo recombination.
Genetic variation is the difference in DNA among individuals or the differences between populations. The multiple sources of genetic variation include mutation and genetic recombination. Mutations are the ultimate sources of genetic variation, but other mechanisms, such as sexual reproduction and genetic drift, contribute to it, as well.
Gene duplication is a major mechanism through which new genetic material is generated during molecular evolution. It can be defined as any duplication of a region of DNA that contains a gene. Gene duplications can arise as products of several types of errors in DNA replication and repair machinery as well as through fortuitous capture by selfish genetic elements. Common sources of gene duplications include ectopic recombination, retrotransposition event, aneuploidy, polyploidy, and replication slippage.

In genetics, a single-nucleotide polymorphism is a germline substitution of a single nucleotide at a specific position in the genome. Although certain definitions require the substitution to be present in a sufficiently large fraction of the population, many publications do not apply such a frequency threshold.
The effective population size (Ne) is the number of individuals that an idealised population would need to have in order for some specified quantity of interest to be the same as in the real population. Idealised populations are based on unrealistic but convenient simplifications such as random mating, simultaneous birth of each new generation, constant population size, and equal numbers of children per parent. In some simple scenarios, the effective population size is the number of breeding individuals in the population. However, for most quantities of interest and most real populations, the census population size N of a real population is usually larger than the effective population size Ne. The same population may have multiple effective population sizes, for different properties of interest, including for different genetic loci.
Gene conversion is the process by which one DNA sequence replaces a homologous sequence such that the sequences become identical after the conversion event. Gene conversion can be either allelic, meaning that one allele of the same gene replaces another allele, or ectopic, meaning that one paralogous DNA sequence converts another.
Coalescent theory is a model of how alleles sampled from a population may have originated from a common ancestor. In the simplest case, coalescent theory assumes no recombination, no natural selection, and no gene flow or population structure, meaning that each variant is equally likely to have been passed from one generation to the next. The model looks backward in time, merging alleles into a single ancestral copy according to a random process in coalescence events. Under this model, the expected time between successive coalescence events increases almost exponentially back in time. Variance in the model comes from both the random passing of alleles from one generation to the next, and the random occurrence of mutations in these alleles.
Genetic hitchhiking, also called genetic draft or the hitchhiking effect, is when an allele changes frequency not because it itself is under natural selection, but because it is near another gene that is undergoing a selective sweep and that is on the same DNA chain. When one gene goes through a selective sweep, any other nearby polymorphisms that are in linkage disequilibrium will tend to change their allele frequencies too. Selective sweeps happen when newly appeared mutations are advantageous and increase in frequency. Neutral or even slightly deleterious alleles that happen to be close by on the chromosome 'hitchhike' along with the sweep. In contrast, effects on a neutral locus due to linkage disequilibrium with newly appeared deleterious mutations are called background selection. Both genetic hitchhiking and background selection are stochastic (random) evolutionary forces, like genetic drift.
The fixation index (FST) is a measure of population differentiation due to genetic structure. It is frequently estimated from genetic polymorphism data, such as single-nucleotide polymorphisms (SNP) or microsatellites. Developed as a special case of Wright's F-statistics, it is one of the most commonly used statistics in population genetics.

In biology, a gene is a basic unit of heredity and a sequence of nucleotides in DNA that encodes the synthesis of a gene product, either RNA or protein.
In population genetics, the Watterson estimator is a method for describing the genetic diversity in a population. It was developed by Margaret Wu and G. A. Watterson in the 1970s. It is estimated by counting the number of polymorphic sites. It is a measure of the "population mutation rate" from the observed nucleotide diversity of a population. , where is the effective population size and is the per-generation mutation rate of the population of interest. The assumptions made are that there is a sample of haploid individuals from the population of interest, that there are infinitely many sites capable of varying, and that . Because the number of segregating sites counted will increase with the number of sequences looked at, the correction factor is used.
In population genetics, fixation is the change in a gene pool from a situation where there exists at least two variants of a particular gene (allele) in a given population to a situation where only one of the alleles remains. In the absence of mutation or heterozygote advantage, any allele must eventually be lost completely from the population or fixed. Whether a gene will ultimately be lost or fixed is dependent on selection coefficients and chance fluctuations in allelic proportions. Fixation can refer to a gene in general or particular nucleotide position in the DNA chain (locus).
The HKA Test, named after Richard R. Hudson, Martin Kreitman, and Montserrat Aguadé, is a statistical test used in genetics to evaluate the predictions of the Neutral Theory of molecular evolution. By comparing the polymorphism within each species and the divergence observed between two species at two or more loci, the test can determine whether the observed difference is likely due to neutral evolution or rather due to adaptive evolution. Developed in 1987, the HKA test is a precursor to the McDonald-Kreitman test, which was derived in 1991. The HKA test is best used to look for balancing selection, recent selective sweeps or other variation-reducing forces.





