Jackson structured programming (JSP) is a method for structured programming developed by British software consultant Michael A. Jackson. It was described in his 1975 book Principles of Program Design.[1] The technique of JSP is to analyze the data structures of the files that a program must read as input and produce as output, and then produce a program design based on those data structures, so that the program control structure handles those data structures in a natural and intuitive way.
JSP describes structures (of both data and programs) using three basic structures – sequence, iteration, and selection (or alternatives). These structures are diagrammed as (in effect) a visual representation of a regular expression.
Introduction
Michael A. Jackson originally developed JSP in the 1970s. He documented the system in his 1975 book Principles of Program Design.[1] In a 2001 conference talk,[2] he provided a retrospective analysis of the original driving forces behind the method, and related it to subsequent software engineering developments. Jackson's aim was to make COBOLbatch file processing programs easier to modify and maintain, but the method can be used to design programs for any programming language that has structured control constructs—sequence, iteration, and selection ("if/then/else").
Jackson Structured Programming was similar to Warnier/Orr structured programming[3][4] although JSP considered both input and output data structures while the Warnier/Orr method focused almost exclusively on the structure of the output stream.
Motivation for the method
At the time that JSP was developed, most programs were batch COBOL programs that processed sequential files stored on tape. A typical program read through its input file as a sequence of records, so that all programs had the same structure— a single main loop that processed all of the records in the file, one at a time. Jackson asserted that this program structure was almost always wrong, and encouraged programmers to look for more complex data structures. In Chapter 3 of Principles of Program Design[1] Jackson presents two versions of a program, one designed using JSP, the other using the traditional single-loop structure. Here is his example, translated from COBOL into Java. The purpose of these two programs is to recognize groups of repeated records (lines) in a sorted file, and to produce an output file listing each record and the number of times that it occurs in the file.
Here is the traditional, single-loop version of the program.
Stringline=null;intcount=0;StringfirstLineOfGroup=null;// begin single main loopwhile((line=in.readLine())!=null){if(firstLineOfGroup==null||!line.equals(firstLineOfGroup)){if(firstLineOfGroup!=null){System.out.printf("%s %d%n",firstLineOfGroup,count);}count=0;firstLineOfGroup=line;}count++;}if(firstLineOfGroup!=null){System.out.printf("%s %d%n",firstLineOfGroup,count);}
Here is a JSP-style version of the same program. Note that (unlike the traditional program) it has two loops, one nested inside the other. The outer loop processes groups of repeating records, while the inner loop processes the individual records in a group.
intnumberOfLinesInGroup=0;Stringline=in.readLine();// begin outer loop: process 1 groupwhile(line!=null){numberOfLinesInGroup=0;StringfirstLineOfGroup=line;// begin inner loop: process 1 record in the groupwhile(line!=null&&line.equals(firstLineOfGroup)){numberOfLinesInGroup++;line=in.readLine();}System.out.printf("%s %d%n",firstLineOfGroup,count);}
Jackson criticises the traditional single-loop version for failing to process the structure of the input file (a sequence of groups containing repeating records) in a natural way. One sign of its unnatural design is that, in order to work properly, it is forced to include special code for handling the first and last record of the file.
The basic method
JSP uses semi-formal steps to capture the existing structure of a program's inputs and outputs in the structure of the program itself.
The intent is to create programs which are easy to modify over their lifetime. Jackson's major insight was that requirement changes are usually minor tweaks to the existing structures. For a program constructed using JSP, the inputs, the outputs, and the internal structures of the program all match, so small changes to the inputs and outputs should translate into small changes to the program.
JSP structures programs in terms of four component types:
fundamental operations
sequences
iterations
selections
The method begins by describing a program's inputs in terms of the four fundamental component types. It then goes on to describe the program's outputs in the same way. Each input and output is modelled as a separate Data Structure Diagram (DSD). To make JSP work for compute-intensive applications, such as digital signal processing (DSP) it is also necessary to draw algorithm structure diagrams, which focus on internal data structures rather than input and output ones.
The input and output structures are then unified or merged into a final program structure, known as a Program Structure Diagram (PSD). This step may involve the addition of a small amount of high-level control structure to marry up the inputs and outputs. Some programs process all the input before doing any output, whilst others read in one record, write one record and iterate. Such approaches have to be captured in the PSD.
The PSD, which is language neutral, is then implemented in a programming language. JSP is geared towards programming at the level of control structures, so the implemented designs use just primitive operations, sequences, iterations and selections. JSP is not used to structure programs at the level of classes and objects, although it can helpfully structure control flow within a class's methods.
JSP uses a diagramming notation to describe the structure of inputs, outputs and programs, with diagram elements for each of the fundamental component types.
A simple operation is drawn as a box.
An operation
A sequence of operations is represented by boxes connected with lines. In the example below, A is a sequence consisting of operations B, C and D.
A sequence
An iteration is again represented with joined boxes. In addition the iterated operation has a star in the top right corner of its box. In the example below, A is an iteration of zero or more invocations of operation B.
An iteration
Selection is similar to a sequence, but with a circle drawn in the top right hand corner of each optional operation. In the example, A is a selection of one and only one of operations B, C or D.
A selection
Note that it in the above diagrams, it is element A that is the sequence or iteration, not the elements B, C or D (which in the above diagrams are all elementary). Jackson gives the 'Look-down rule' to determine what an element is, i.e. look at the elements below an element to find out what it is.
A worked example
As an example, here is how a JSP programmer would design and code a run length encoder. A run length encoder is a program whose input is a stream of bytes which can be viewed as occurring in runs, where a run consists of one or more occurrences of bytes of the same value. The output of the program is a stream of byte pairs, where each byte pair is a compressed description of a run. In each pair, the first byte is the value of the repeated byte in a run and the second byte is a number indicating the number of times that that value was repeated in the run. For example, a run of eight occurrences of the letter "A" in the input stream ("AAAAAAAA") would produce "A8" as a byte pair in the output stream. Run length encoders are often used for crudely compressing bitmaps.
With JSP, the first step is to describe the data structure(s) of a program's input stream(s). The program has only one input stream, consisting of zero or more runs of the same byte value. Here is the JSP data structure diagram for the input stream.
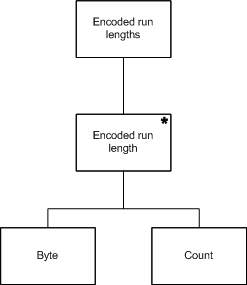
The second step is to describe the output data structure, which in this case consists of zero or more iterations of byte pairs.
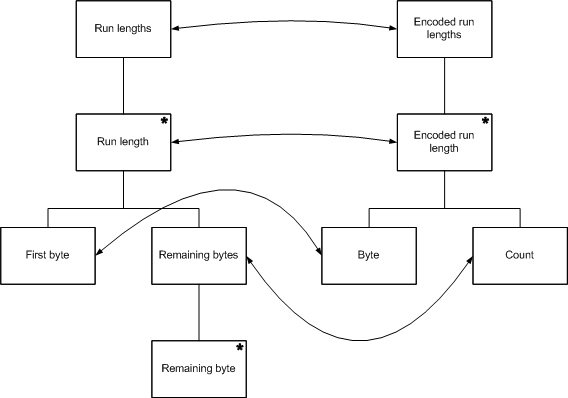
The next step is to describe the correspondences between the components of the input and output structures.
The next step is to use the correspondences between the two data structures to create a program structure that is capable of processing the input data structure and producing the output data structure. (Sometimes this isn't possible. See the discussion of structure clashes, below.)
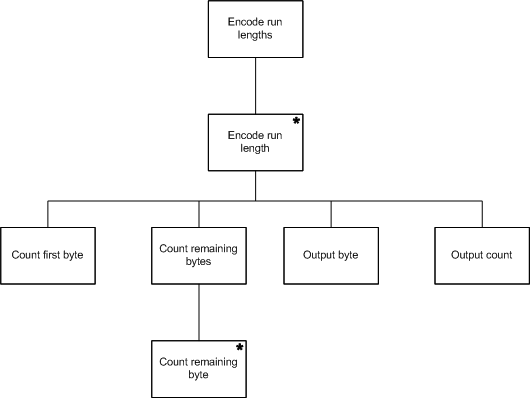
Once the program structure is finished, the programmer creates a list of the computational operations that the program must perform, and the program structure diagram is fleshed out by hanging those operations off of the appropriate structural components.
read a byte
remember byte
set counter to zero
increment counter
output remembered byte
output counter
Also, at this stage conditions on iterations (loops) and selections (if-then-else or case statements) are listed and added to the program structure diagram.
while there are more bytes
while there are more bytes and this byte is the same as the run's first byte and the count will still fit in a byte
Once the diagram is finished, it can be translated into whatever programming language is being used. Here is a translation into C.
#include<stdio.h>#include<stdlib.h>intmain(intargc,char*argv[]){charfirst_byte;intcount=0;charc=getchar();// get first bytewhile(c!=EOF){// process the first byte in the runfirst_byte=c;count=1;c=getchar();// get next byte// process the succeeding bytes in the runwhile(c!=EOF&&c==first_byte&&count<255){// process one byte of the same valuecount++;c=getchar();// get next byte}putchar(first_byte);putchar(count);}returnEXIT_SUCCESS;}
Techniques for handling difficult design problems
In Principles of Program Design Jackson recognized situations that posed specific kinds of design problems, and provided techniques for handling them.
One of these situations is a case in which a program processes two input files, rather than one. In 1975, one of the standard "wicked problems" was how to design a transaction-processing program. In such a program, a sequential file of update records is run against a sequential master file, producing an updated master file as output. (For example, at night a bank would run a batch program that would update the balances in its customers' accounts based on records of the deposits and withdrawals that they had made that day.) Principles of Program Design provided a standard solution for that problem, along with an explanation of the logic behind the design.
Another kind of problem involved what Jackson called "recognition difficulties" and today we would call parsing problems. The basic JSP design technique was supplemented by POSIT and QUIT operations to allow the design of what we would now call a backtracking parser.
JSP also recognized three situations that are called "structure clashes"— a boundary clash, an ordering clash, and an interleaving clash— and provided techniques for dealing with them. In structure clash situations the input and output data structures are so incompatible that it is not possible to produce the output file from the input file. It is necessary, in effect, to write two programs— the first processes the input stream, breaks it down into smaller chunks, and writes those chunks to an intermediate file. The second program reads the intermediate file and produces the desired output.
JSP and object-oriented design
JSP was developed long before object-oriented technologies became available. It and its successor method JSD do not treat what now would be called "objects" as collections of more or less independent methods. Instead, following the work of C. A. R. Hoare, JSP and JSD describe software objects as co-routines.[5][6]
123Jackson, MA (1975), Principles of Program Design, Academic.
↑Jackson, MA (2001), JSP in Perspective(PDF), sd&m Pioneers’ Conference, Bonn, June 2001, archived(PDF) from the original on 2017-05-16, retrieved 2017-01-26{{citation}}: CS1 maint: location (link) CS1 maint: location missing publisher (link)
↑Warnier, JD (1974), Logical Construction of Programs, NY: Van Nostrand Reinhold
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.