Related Research Articles

A graphical user interface, or GUI, is a form of user interface that allows users to interact with electronic devices through graphical icons and visual indicators such as secondary notation. In many applications, GUIs are used instead of text-based UIs, which are based on typed command labels or text navigation. GUIs were introduced in reaction to the perceived steep learning curve of command-line interfaces (CLIs), which require commands to be typed on a computer keyboard.
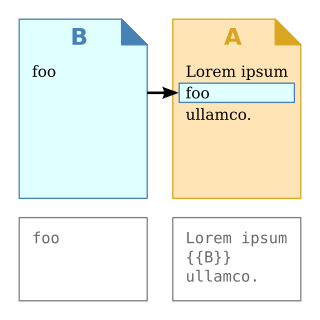
In computer science, transclusion is the inclusion of part or all of an electronic document into one or more other documents by reference via hypertext. Transclusion is usually performed when the referencing document is displayed, and is normally automatic and transparent to the end user. The result of transclusion is a single integrated document made of parts assembled dynamically from separate sources, possibly stored on different computers in disparate places.

The World Wide Web is an information system that enables content sharing over the Internet through user-friendly ways meant to appeal to users beyond IT specialists and hobbyists. It allows documents and other web resources to be accessed over the Internet according to specific rules of the Hypertext Transfer Protocol (HTTP).
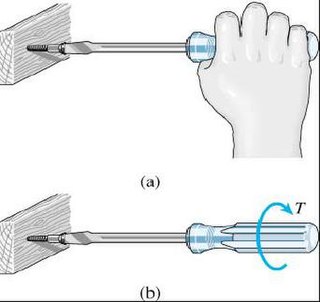
Usability can be described as the capacity of a system to provide a condition for its users to perform the tasks safely, effectively, and efficiently while enjoying the experience. In software engineering, usability is the degree to which a software can be used by specified consumers to achieve quantified objectives with effectiveness, efficiency, and satisfaction in a quantified context of use.

Digitization is the process of converting information into a digital format. The result is the representation of an object, image, sound, document, or signal obtained by generating a series of numbers that describe a discrete set of points or samples. The result is called digital representation or, more specifically, a digital image, for the object, and digital form, for the signal. In modern practice, the digitized data is in the form of binary numbers, which facilitates processing by digital computers and other operations, but digitizing simply means "the conversion of analog source material into a numerical format"; the decimal or any other number system can be used instead.

File Explorer, previously known as Windows Explorer, is a file manager application and default desktop environment that is included with releases of the Microsoft Windows operating system from Windows 95 onwards. It provides a graphical user interface for accessing the file systems, as well as user interface elements such as the taskbar and desktop.
In library and archival science, digital preservation is a formal process to ensure that digital information of continuing value remains accessible and usable in the long term. It involves planning, resource allocation, and application of preservation methods and technologies, and combines policies, strategies and actions to ensure access to reformatted and "born-digital" content, regardless of the challenges of media failure and technological change. The goal of digital preservation is the accurate rendering of authenticated content over time.

Web 2.0 refers to websites that emphasize user-generated content, ease of use, participatory culture and interoperability for end users.
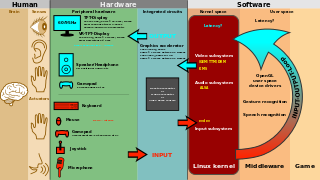
User interface (UI) design or user interface engineering is the design of user interfaces for machines and software, such as computers, home appliances, mobile devices, and other electronic devices, with the focus on maximizing usability and the user experience. In computer or software design, user interface (UI) design primarily focuses on information architecture. It is the process of building interfaces that clearly communicate to the user what's important. UI design refers to graphical user interfaces and other forms of interface design. The goal of user interface design is to make the user's interaction as simple and efficient as possible, in terms of accomplishing user goals.

In computing, a news aggregator, also termed a feed aggregator, content aggregator, feed reader, news reader, RSS reader, or simply an aggregator, is client software or a web application that aggregates digital content such as online newspapers, blogs, podcasts, and video blogs (vlogs) in one location for easy viewing. The updates distributed may include journal tables of contents, podcasts, videos, and news items.
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may directly access the World Wide Web using the Hypertext Transfer Protocol or a web browser. While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis.
As the next version of Windows NT after Windows 2000, as well as the successor to Windows Me, Windows XP introduced many new features but it also removed some others.

A search engine is a software system that finds web pages that match a web search. They search the World Wide Web in a systematic way for particular information specified in a textual web search query. The search results are generally presented in a line of results, often referred to as search engine results pages (SERPs). The information may be a mix of hyperlinks to web pages, images, videos, infographics, articles, and other types of files. Some search engines also mine data available in databases or open directories. Unlike web directories and social bookmarking sites, which are maintained by human editors, search engines also maintain real-time information by running an algorithm on a web crawler. Any internet-based content that cannot be indexed and searched by a web search engine falls under the category of deep web. Modern search engines are based on techniques and methods developed in the field of Information retrieval.
User experience design defines the experience a user would go through when interacting with a company, its services, and its products. User experience design is a user centered design approach because it considers the user's experience when using a product or platform. Research, data analysis, and test results drive design decisions in UX design rather than aesthetic preferences and opinions. Unlike user interface design, which focuses solely on the design of a computer interface, UX design encompasses all aspects of a user's perceived experience with a product or website, such as its usability, usefulness, desirability, brand perception, and overall performance. UX design is also an element of the customer experience (CX), and encompasses all aspects and stages of a customer's experience and interaction with a company.

Metadata is "data that provides information about other data", but not the content of the data itself, such as the text of a message or the image itself. There are many distinct types of metadata, including:
A digital library, also called an online library, an internet library, a digital repository, a library without walls, or a digital collection, is an online database of digital objects that can include text, still images, audio, video, digital documents, or other digital media formats or a library accessible through the internet. Objects can consist of digitized content like print or photographs, as well as originally produced digital content like word processor files or social media posts. In addition to storing content, digital libraries provide means for organizing, searching, and retrieving the content contained in the collection. Digital libraries can vary immensely in size and scope, and can be maintained by individuals or organizations. The digital content may be stored locally, or accessed remotely via computer networks. These information retrieval systems are able to exchange information with each other through interoperability and sustainability.
The Handle System is the Corporation for National Research Initiatives's proprietary registry assigning persistent identifiers, or handles, to information resources, and for resolving "those handles into the information necessary to locate, access, and otherwise make use of the resources".
Cognition Network Technology (CNT), also known as Definiens Cognition Network Technology, is an object-based image analysis method developed by Nobel laureate Gerd Binnig together with a team of researchers at Definiens AG in Munich, Germany. It serves for extracting information from images using a hierarchy of image objects, as opposed to traditional pixel processing methods.

An application programming interface (API) is a way for two or more computer programs to communicate with each other. It is a type of software interface, offering a service to other pieces of software. A document or standard that describes how to build or use such a connection or interface is called an API specification. A computer system that meets this standard is said to implement or expose an API. The term API may refer either to the specification or to the implementation. Whereas a system's user interface dictates how its end-users interact with the system in question, its API dictates how to write code that takes advantage of that system's capabilities.
A Collections Management System (CMS), sometimes called a Collections Information System, is software used by the collections staff of a collecting institution or by individual private collectors and collecting hobbyists or enthusiasts. Collecting institutions are primarily museums and archives and cover a very broad range from huge, international institutions, to very small or niche-specialty institutions such as local historical museums and preservation societies. Secondarily, libraries and galleries are also collecting institutions. Collections Management Systems (CMSs) allow individuals or collecting institutions to organize, control, and manage their collections' objects by “tracking all information related to and about” those objects. In larger institutions, the CMS may be used by collections staff such as registrars, collections managers, and curators to record information such as object locations, provenance, curatorial information, conservation reports, professional appraisals, and exhibition histories. All of this recorded information is then also accessed and used by other institutional departments such as “education, membership, accounting, and administration."
References
- ↑ "THE DIGITAL LIBRARY PROJECT VOLUME 1: The World of Knowbots (DRAFT) - An open architecture for a digital library system and a plan for its development" (PDF).
- ↑ "Archived copy". Archived from the original on 2016-03-04. Retrieved 2015-09-30.
{{cite web}}: CS1 maint: archived copy as title (link) - ↑ "What is knowbot? - Definition from WhatIs.com". Archived from the original on 2015-11-19. Retrieved 2015-11-04.
| | This Web-software-related article is a stub. You can help Wikipedia by expanding it. |