Related Research Articles

A finite-state machine (FSM) or finite-state automaton, finite automaton, or simply a state machine, is a mathematical model of computation. It is an abstract machine that can be in exactly one of a finite number of states at any given time. The FSM can change from one state to another in response to some inputs; the change from one state to another is called a transition. An FSM is defined by a list of its states, its initial state, and the inputs that trigger each transition. Finite-state machines are of two types—deterministic finite-state machines and non-deterministic finite-state machines. For any non-deterministic finite-state machine, an equivalent deterministic one can be constructed.

In machine learning, a neural network is a model inspired by the structure and function of biological neural networks in animal brains.
Reinforcement learning (RL) is an interdisciplinary area of machine learning and optimal control concerned with how an intelligent agent ought to take actions in a dynamic environment in order to maximize the cumulative reward. Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.
Automata theory is the study of abstract machines and automata, as well as the computational problems that can be solved using them. It is a theory in theoretical computer science with close connections to mathematical logic. The word automata comes from the Greek word αὐτόματος, which means "self-acting, self-willed, self-moving". An automaton is an abstract self-propelled computing device which follows a predetermined sequence of operations automatically. An automaton with a finite number of states is called a finite automaton (FA) or finite-state machine (FSM). The figure on the right illustrates a finite-state machine, which is a well-known type of automaton. This automaton consists of states and transitions. As the automaton sees a symbol of input, it makes a transition to another state, according to its transition function, which takes the previous state and current input symbol as its arguments.
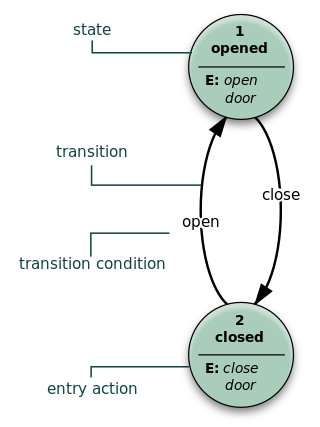
A state diagram is used in computer science and related fields to describe the behavior of systems. State diagrams require that the system is composed of a finite number of states. Sometimes, this is indeed the case, while at other times this is a reasonable abstraction. Many forms of state diagrams exist, which differ slightly and have different semantics.

In the theory of computation, a branch of theoretical computer science, a deterministic finite automaton (DFA)—also known as deterministic finite acceptor (DFA), deterministic finite-state machine (DFSM), or deterministic finite-state automaton (DFSA)—is a finite-state machine that accepts or rejects a given string of symbols, by running through a state sequence uniquely determined by the string. Deterministic refers to the uniqueness of the computation run. In search of the simplest models to capture finite-state machines, Warren McCulloch and Walter Pitts were among the first researchers to introduce a concept similar to finite automata in 1943.
A finite-state transducer (FST) is a finite-state machine with two memory tapes, following the terminology for Turing machines: an input tape and an output tape. This contrasts with an ordinary finite-state automaton, which has a single tape. An FST is a type of finite-state automaton (FSA) that maps between two sets of symbols. An FST is more general than an FSA. An FSA defines a formal language by defining a set of accepted strings, while an FST defines a relation between sets of strings.
In mathematics, a Markov decision process (MDP) is a discrete-time stochastic control process. It provides a mathematical framework for modeling decision making in situations where outcomes are partly random and partly under the control of a decision maker. MDPs are useful for studying optimization problems solved via dynamic programming. MDPs were known at least as early as the 1950s; a core body of research on Markov decision processes resulted from Ronald Howard's 1960 book, Dynamic Programming and Markov Processes. They are used in many disciplines, including robotics, automatic control, economics and manufacturing. The name of MDPs comes from the Russian mathematician Andrey Markov as they are an extension of Markov chains.
Q-learning is a model-free reinforcement learning algorithm to learn the value of an action in a particular state. It does not require a model of the environment, and it can handle problems with stochastic transitions and rewards without requiring adaptations.

In probability theory and machine learning, the multi-armed bandit problem is a problem in which a decision maker iteratively selects one of multiple fixed choices when the properties of each choice are only partially known at the time of allocation, and may become better understood as time passes. A fundamental aspect of bandit problems is that choosing an arm does not affect the properties of the arm or other arms.
In quantum computing, quantum finite automata (QFA) or quantum state machines are a quantum analog of probabilistic automata or a Markov decision process. They provide a mathematical abstraction of real-world quantum computers. Several types of automata may be defined, including measure-once and measure-many automata. Quantum finite automata can also be understood as the quantization of subshifts of finite type, or as a quantization of Markov chains. QFAs are, in turn, special cases of geometric finite automata or topological finite automata.
In mathematics and computer science, the probabilistic automaton (PA) is a generalization of the nondeterministic finite automaton; it includes the probability of a given transition into the transition function, turning it into a transition matrix. Thus, the probabilistic automaton also generalizes the concepts of a Markov chain and of a subshift of finite type. The languages recognized by probabilistic automata are called stochastic languages; these include the regular languages as a subset. The number of stochastic languages is uncountable.
Automata-based programming is a programming technology. Its defining characteristic is the use of finite state machines to describe program behavior. The transition graphs of state machines are used in all stages of software development. Automata-based programming technology was introduced by Anatoly Shalyto in 1991. Switch-technology was developed to support automata-based programming. Automata-based programming is considered to be rather general purpose program development methodology than just another one finite state machine implementation.

In automata theory, DFA minimization is the task of transforming a given deterministic finite automaton (DFA) into an equivalent DFA that has a minimum number of states. Here, two DFAs are called equivalent if they recognize the same regular language. Several different algorithms accomplishing this task are known and described in standard textbooks on automata theory.
Input/output automata provide a formal model, applicable in describing most types of an asynchronous concurrent system. On its own, the I/O automaton model contains a very basic structure that enables it to model various types of distributed systems. To describe specific types of asynchronous systems, additional structure must be added to this basic model. The model presents an explicit method for describing and reasoning about system components such as processes and message channels that interact with one another, operating at arbitrary relative speeds. The I/O automata were first introduced by Nancy A. Lynch and Mark R. Tuttle in "Hierarchical correctness proofs for distributed algorithms", 1987.
Stochastic cellular automata or probabilistic cellular automata (PCA) or random cellular automata or locally interacting Markov chains are an important extension of cellular automaton. Cellular automata are a discrete-time dynamical system of interacting entities, whose state is discrete.
In computational learning theory, induction of regular languages refers to the task of learning a formal description of a regular language from a given set of example strings. Although E. Mark Gold has shown that not every regular language can be learned this way, approaches have been investigated for a variety of subclasses. They are sketched in this article. For learning of more general grammars, see Grammar induction.
Adversarial machine learning is the study of the attacks on machine learning algorithms, and of the defenses against such attacks. A survey from May 2020 exposes the fact that practitioners report a dire need for better protecting machine learning systems in industrial applications.
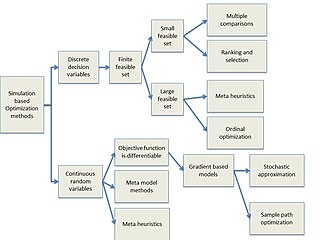
Simulation-based optimization integrates optimization techniques into simulation modeling and analysis. Because of the complexity of the simulation, the objective function may become difficult and expensive to evaluate. Usually, the underlying simulation model is stochastic, so that the objective function must be estimated using statistical estimation techniques.
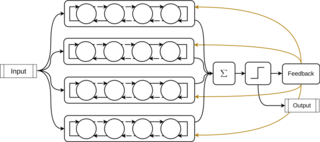
A Tsetlin machine is an Artificial Intelligence algorithm based on propositional logic.
References
- ↑ (Narendra, Thathachar, 1974) p.325 left
- ↑ (Narendra, Thathachar, 1974) p.325 right
- ↑ JieGH (2019-11-11), JieGH/The-Ruler-of-Tsetlin-Automaton , retrieved 2020-07-22
- ↑ "The-Ruler-of-Tsetlin-Automaton". www.youtube.com. Retrieved 2020-07-22.
- ↑ Thathachar, M.A.L.; Sastry, P.S. (December 2002). "Varieties of learning automata: an overview" (PDF). IEEE Transactions on Systems, Man, and Cybernetics - Part B: Cybernetics. 32 (6): 711–722. doi:10.1109/TSMCB.2002.1049606. PMID 18244878.