Related Research Articles
Distributed computing is a field of computer science that studies distributed systems. A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another from any system. The components interact with one another in order to achieve a common goal. Three significant characteristics of distributed systems are: concurrency of components, lack of a global clock, and independent failure of components. It deals with a central challenge that, when components of a system fails, it doesn't imply the entire system fails. Examples of distributed systems vary from SOA-based systems to massively multiplayer online games to peer-to-peer applications.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.

Leslie B. Lamport is an American computer scientist. Lamport is best known for his seminal work in distributed systems, and as the initial developer of the document preparation system LaTeX and the author of its first manual. Leslie Lamport was the winner of the 2013 Turing Award for imposing clear, well-defined coherence on the seemingly chaotic behavior of distributed computing systems, in which several autonomous computers communicate with each other by passing messages. He devised important algorithms and developed formal modeling and verification protocols that improve the quality of real distributed systems. These contributions have resulted in improved correctness, performance, and reliability of computer systems.
In computer science, the happened-before relation is a relation between the result of two events, such that if one event should happen before another event, the result must reflect that, even if those events are in reality executed out of order. This involves ordering events based on the potential causal relationship of pairs of events in a concurrent system, especially asynchronous distributed systems. It was formulated by Leslie Lamport.
Self-stabilization is a concept of fault-tolerance in distributed systems. Given any initial state, a self-stabilizing distributed system will end up in a correct state in a finite number of execution steps.

In computer science, concurrency is the ability of different parts or units of a program, algorithm, or problem to be executed out-of-order or in partial order, without affecting the final outcome. This allows for parallel execution of the concurrent units, which can significantly improve overall speed of the execution in multi-processor and multi-core systems. In more technical terms, concurrency refers to the decomposability of a program, algorithm, or problem into order-independent or partially-ordered components or units of computation.
Clock synchronization is a topic in computer science and engineering that aims to coordinate otherwise independent clocks. Even when initially set accurately, real clocks will differ after some amount of time due to clock drift, caused by clocks counting time at slightly different rates. There are several problems that occur as a result of clock rate differences and several solutions, some being more appropriate than others in certain contexts.
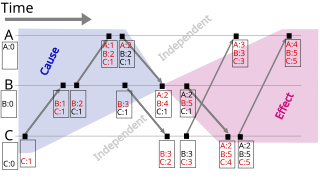
A vector clock is a data structure used for determining the partial ordering of events in a distributed system and detecting causality violations. Just as in Lamport timestamps, inter-process messages contain the state of the sending process's logical clock. A vector clock of a system of N processes is an array/vector of N logical clocks, one clock per process; a local "largest possible values" copy of the global clock-array is kept in each process.
Eventual consistency is a consistency model used in distributed computing to achieve high availability that informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. Eventual consistency, also called optimistic replication, is widely deployed in distributed systems, and has origins in early mobile computing projects. A system that has achieved eventual consistency is often said to have converged, or achieved replica convergence. Eventual consistency is a weak guarantee – most stronger models, like linearizability, are trivially eventually consistent.
The Lamport timestamp algorithm is a simple logical clock algorithm used to determine the order of events in a distributed computer system. As different nodes or processes will typically not be perfectly synchronized, this algorithm is used to provide a partial ordering of events with minimal overhead, and conceptually provide a starting point for the more advanced vector clock method. The algorithm is named after its creator, Leslie Lamport.
Concurrent computing is a form of computing in which several computations are executed concurrently—during overlapping time periods—instead of sequentially—with one completing before the next starts.
The Ricart–Agrawala algorithm is an algorithm for mutual exclusion on a distributed system. This algorithm is an extension and optimization of Lamport's Distributed Mutual Exclusion Algorithm, by removing the need for messages. It was developed by Glenn Ricart and Ashok Agrawala.
Causal consistency is one of the major memory consistency models. In concurrent programming, where concurrent processes are accessing a shared memory, a consistency model restricts which accesses are legal. This is useful for defining correct data structures in distributed shared memory or distributed transactions.
In fault-tolerant distributed computing, an atomic broadcast or total order broadcast is a broadcast where all correct processes in a system of multiple processes receive the same set of messages in the same order; that is, the same sequence of messages. The broadcast is termed "atomic" because it either eventually completes correctly at all participants, or all participants abort without side effects. Atomic broadcasts are an important distributed computing primitive.
Lamport's Distributed Mutual Exclusion Algorithm is a contention-based algorithm for mutual exclusion on a distributed system.
A matrix clock is a mechanism for capturing chronological and causal relationships in a distributed system.
Reverse computation is a software application of the concept of reversible computing.
In a distributed computing system, a failure detector is a computer application or a subsystem that is responsible for the detection of node failures or crashes. Failure detectors were first introduced in 1996 by Chandra and Toueg in their book Unreliable Failure Detectors for Reliable Distributed Systems. The book depicts the failure detector as a tool to improve consensus and atomic broadcast in the distributed system. In other word, failure detectors seek for errors in the process, and the system will maintain a level of reliability. In practice, after failure detectors spot crashes, the system will ban the processes that are making mistakes to prevent any further serious crashes or errors.
A distributed operating system is system software over a collection of independent, networked, communicating, and physically separate computational nodes. They handle jobs which are serviced by multiple CPUs. Each individual node holds a specific software subset of the global aggregate operating system. Each subset is a composite of two distinct service provisioners. The first is a ubiquitous minimal kernel, or microkernel, that directly controls that node's hardware. Second is a higher-level collection of system management components that coordinate the node's individual and collaborative activities. These components abstract microkernel functions and support user applications.
In distributed computing, shared-memory systems and message-passing systems are two means of interprocess communication which have been heavily studied. In shared-memory systems, processes communicate by accessing shared data structures. A shared (read/write) register, sometimes just called a register, is a fundamental type of shared data structure which stores a value and has two operations: read, which returns the value stored in the register, and write, which updates the value stored. Other types of shared data structures include read–modify–write, test-and-set, compare-and-swap etc. The memory location which is concurrently accessed is sometimes called a register.
References
- ↑ "Distributed Systems 3rd edition (2017)". DISTRIBUTED-SYSTEMS.NET. Retrieved 2021-03-20.
- ↑ Chapter 3: Logical Time // Ajay Kshemkalyani and Mukesh Singhal, Distributed Computing: Principles, Algorithms, and Systems, Cambridge University Press, 2008