The subset sum problem (SSP) is a decision problem in computer science. In its most general formulation, there is a multiset of integers and a target-sum , and the question is to decide whether any subset of the integers sum to precisely . The problem is known to be NP. Moreover, some restricted variants of it are NP-complete too, for example:
An adaptive filter is a system with a linear filter that has a transfer function controlled by variable parameters and a means to adjust those parameters according to an optimization algorithm. Because of the complexity of the optimization algorithms, almost all adaptive filters are digital filters. Adaptive filters are required for some applications because some parameters of the desired processing operation are not known in advance or are changing. The closed loop adaptive filter uses feedback in the form of an error signal to refine its transfer function.
A roundoff error, also called rounding error, is the difference between the result produced by a given algorithm using exact arithmetic and the result produced by the same algorithm using finite-precision, rounded arithmetic. Rounding errors are due to inexactness in the representation of real numbers and the arithmetic operations done with them. This is a form of quantization error. When using approximation equations or algorithms, especially when using finitely many digits to represent real numbers, one of the goals of numerical analysis is to estimate computation errors. Computation errors, also called numerical errors, include both truncation errors and roundoff errors.

Association rule learning is a rule-based machine learning method for discovering interesting relations between variables in large databases. It is intended to identify strong rules discovered in databases using some measures of interestingness. In any given transaction with a variety of items, association rules are meant to discover the rules that determine how or why certain items are connected.
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set. False positive matches are possible, but false negatives are not – in other words, a query returns either "possibly in set" or "definitely not in set". Elements can be added to the set, but not removed ; the more items added, the larger the probability of false positives.
Apriori is an algorithm for frequent item set mining and association rule learning over relational databases. It proceeds by identifying the frequent individual items in the database and extending them to larger and larger item sets as long as those item sets appear sufficiently often in the database. The frequent item sets determined by Apriori can be used to determine association rules which highlight general trends in the database: this has applications in domains such as market basket analysis.

The leaky bucket is an algorithm based on an analogy of how a bucket with a constant leak will overflow if either the average rate at which water is poured in exceeds the rate at which the bucket leaks or if more water than the capacity of the bucket is poured in all at once. It can be used to determine whether some sequence of discrete events conforms to defined limits on their average and peak rates or frequencies, e.g. to limit the actions associated with these events to these rates or delay them until they do conform to the rates. It may also be used to check conformance or limit to an average rate alone, i.e. remove any variation from the average.
Histograms are most commonly used as visual representations of data. However, Database systems use histograms to summarize data internally and provide size estimates for queries. These histograms are not presented to users or displayed visually, so a wider range of options are available for their construction. Simple or exotic histograms are defined by four parameters, Sort Value, Source Value, Partition Class and Partition Rule. The most basic histogram is the equi-width histogram, where each bucket represents the same range of values. That histogram would be defined as having a Sort Value of Value, a Source Value of Frequency, be in the Serial Partition Class and have a Partition Rule stating that all buckets have the same range.
The approximate counting algorithm allows the counting of a large number of events using a small amount of memory. Invented in 1977 by Robert Morris of Bell Labs, it uses probabilistic techniques to increment the counter. It was fully analyzed in the early 1980s by Philippe Flajolet of INRIA Rocquencourt, who coined the name approximate counting, and strongly contributed to its recognition among the research community. When focused on high quality of approximation and low probability of failure, Nelson and Yu showed that a very slight modification to the Morris Counter is asymptotically optimal amongst all algorithms for the problem. The algorithm is considered one of the precursors of streaming algorithms, and the more general problem of determining the frequency moments of a data stream has been central to the field.
In computer science, streaming algorithms are algorithms for processing data streams in which the input is presented as a sequence of items and can be examined in only a few passes. In most models, these algorithms have access to limited memory. They may also have limited processing time per item.
Samplesort is a sorting algorithm that is a divide and conquer algorithm often used in parallel processing systems. Conventional divide and conquer sorting algorithms partitions the array into sub-intervals or buckets. The buckets are then sorted individually and then concatenated together. However, if the array is non-uniformly distributed, the performance of these sorting algorithms can be significantly throttled. Samplesort addresses this issue by selecting a sample of size s from the n-element sequence, and determining the range of the buckets by sorting the sample and choosing p−1 < s elements from the result. These elements then divide the array into p approximately equal-sized buckets. Samplesort is described in the 1970 paper, "Samplesort: A Sampling Approach to Minimal Storage Tree Sorting", by W. D. Frazer and A. C. McKellar.
A locally decodable code (LDC) is an error-correcting code that allows a single bit of the original message to be decoded with high probability by only examining a small number of bits of a possibly corrupted codeword. This property could be useful, say, in a context where information is being transmitted over a noisy channel, and only a small subset of the data is required at a particular time and there is no need to decode the entire message at once. Note that locally decodable codes are not a subset of locally testable codes, though there is some overlap between the two.
In computer science and data mining, MinHash is a technique for quickly estimating how similar two sets are. The scheme was invented by Andrei Broder (1997), and initially used in the AltaVista search engine to detect duplicate web pages and eliminate them from search results. It has also been applied in large-scale clustering problems, such as clustering documents by the similarity of their sets of words.
In computing, the count–min sketch is a probabilistic data structure that serves as a frequency table of events in a stream of data. It uses hash functions to map events to frequencies, but unlike a hash table uses only sub-linear space, at the expense of overcounting some events due to collisions. The count–min sketch was invented in 2003 by Graham Cormode and S. Muthu Muthukrishnan and described by them in a 2005 paper.
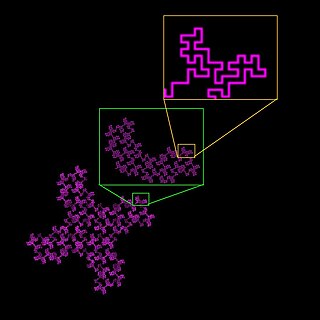
Box counting is a method of gathering data for analyzing complex patterns by breaking a dataset, object, image, etc. into smaller and smaller pieces, typically "box"-shaped, and analyzing the pieces at each smaller scale. The essence of the process has been compared to zooming in or out using optical or computer based methods to examine how observations of detail change with scale. In box counting, however, rather than changing the magnification or resolution of a lens, the investigator changes the size of the element used to inspect the object or pattern. Computer based box counting algorithms have been applied to patterns in 1-, 2-, and 3-dimensional spaces. The technique is usually implemented in software for use on patterns extracted from digital media, although the fundamental method can be used to investigate some patterns physically. The technique arose out of and is used in fractal analysis. It also has application in related fields such as lacunarity and multifractal analysis.
HyperLogLog is an algorithm for the count-distinct problem, approximating the number of distinct elements in a multiset. Calculating the exact cardinality of the unique elements of a multiset requires an amount of memory proportional to the cardinality, which is impractical for very large data sets. Probabilistic cardinality estimators, such as the HyperLogLog algorithm, use significantly less memory than this, at the cost of obtaining only an approximation of the cardinality. The HyperLogLog algorithm is able to estimate cardinalities of > 109 with a typical accuracy (standard error) of 2%, using 1.5 kB of memory. HyperLogLog is an extension of the earlier LogLog algorithm, itself deriving from the 1984 Flajolet–Martin algorithm.
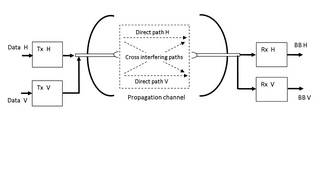
XPIC, or cross-polarization interference cancelling technology, is an algorithm to suppress mutual interference between two received streams in a Polarization-division multiplexing communication system.
A cuckoo filter is a space-efficient probabilistic data structure that is used to test whether an element is a member of a set, like a Bloom filter does. False positive matches are possible, but false negatives are not – in other words, a query returns either "possibly in set" or "definitely not in set". A cuckoo filter can also delete existing items, which is not supported by Bloom filters. In addition, for applications that store many items and target moderately low false positive rates, cuckoo filters can achieve lower space overhead than space-optimized Bloom filters.
Interpolation sort is a kind of bucket sort. It uses an interpolation formula to assign data to the bucket. A general interpolation formula is:
In the bin covering problem, items of different sizes must be packed into a finite number of bins or containers, each of which must contain at least a certain given total size, in a way that maximizes the number of bins used.


