Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value. A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a "reasonable" way.
In machine learning, support-vector machines are supervised learning models with associated learning algorithms that analyze data for classification and regression analysis. Developed at AT&T Bell Laboratories by Vapnik with colleagues, SVMs are one of the most robust prediction methods, being based on statistical learning frameworks or VC theory proposed by Vapnik and Chervonenkis (1974) and Vapnik. Given a set of training examples, each marked as belonging to one of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other, making it a non-probabilistic binary linear classifier. An SVM maps training examples to points in space so as to maximise the width of the gap between the two categories. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.
In the field of machine learning, the goal of statistical classification is to use an object's characteristics to identify which class it belongs to. A linear classifier achieves this by making a classification decision based on the value of a linear combination of the characteristics. An object's characteristics are also known as feature values and are typically presented to the machine in a vector called a feature vector. Such classifiers work well for practical problems such as document classification, and more generally for problems with many variables (features), reaching accuracy levels comparable to non-linear classifiers while taking less time to train and use.
Pattern recognition is the automated recognition of patterns and regularities in data. It has applications in statistical data analysis, signal processing, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. Pattern recognition has its origins in statistics and engineering; some modern approaches to pattern recognition include the use of machine learning, due to the increased availability of big data and a new abundance of processing power. However, these activities can be viewed as two facets of the same field of application, and together they have undergone substantial development over the past few decades. A modern definition of pattern recognition is:
The field of pattern recognition is concerned with the automatic discovery of regularities in data through the use of computer algorithms and with the use of these regularities to take actions such as classifying the data into different categories.
In machine learning, the perceptron is an algorithm for supervised learning of binary classifiers. A binary classifier is a function which can decide whether or not an input, represented by a vector of numbers, belongs to some specific class. It is a type of linear classifier, i.e. a classification algorithm that makes its predictions based on a linear predictor function combining a set of weights with the feature vector.
Chemometrics is the science of extracting information from chemical systems by data-driven means. Chemometrics is inherently interdisciplinary, using methods frequently employed in core data-analytic disciplines such as multivariate statistics, applied mathematics, and computer science, in order to address problems in chemistry, biochemistry, medicine, biology and chemical engineering. In this way, it mirrors other interdisciplinary fields, such as psychometrics and econometrics.
The curse of dimensionality refers to various phenomena that arise when analyzing and organizing data in high-dimensional spaces that do not occur in low-dimensional settings such as the three-dimensional physical space of everyday experience. The expression was coined by Richard E. Bellman when considering problems in dynamic programming.
Linear discriminant analysis (LDA), normal discriminant analysis (NDA), or discriminant function analysis is a generalization of Fisher's linear discriminant, a method used in statistics and other fields, to find a linear combination of features that characterizes or separates two or more classes of objects or events. The resulting combination may be used as a linear classifier, or, more commonly, for dimensionality reduction before later classification.
In computer science and machine learning, cellular neural networks (CNN) or cellular nonlinear networks (CNN) are a parallel computing paradigm similar to neural networks, with the difference that communication is allowed between neighbouring units only. Typical applications include image processing, analyzing 3D surfaces, solving partial differential equations, reducing non-visual problems to geometric maps, modelling biological vision and other sensory-motor organs.
Multivariate analysis (MVA) is based on the principles of multivariate statistics, which involves observation and analysis of more than one statistical outcome variable at a time. Typically, MVA is used to address the situations where multiple measurements are made on each experimental unit and the relations among these measurements and their structures are important. A modern, overlapping categorization of MVA includes:
Neural coding is a neuroscience field concerned with characterising the hypothetical relationship between the stimulus and the individual or ensemble neuronal responses and the relationship among the electrical activity of the neurons in the ensemble. Based on the theory that sensory and other information is represented in the brain by networks of neurons, it is thought that neurons can encode both digital and analog information.
Multivariate optical computing, also known as molecular factor computing, is an approach to the development of compressed sensing spectroscopic instruments, particularly for industrial applications such as process analytical support. "Conventional" spectroscopic methods often employ multivariate and chemometric methods, such as multivariate calibration, pattern recognition, and classification, to extract analytical information from data collected at many different wavelengths. Multivariate optical computing uses an optical computer to analyze the data as it is collected. The goal of this approach is to produce instruments which are simple and rugged, yet retain the benefits of multivariate techniques for the accuracy and precision of the result.
In statistics and machine learning, ensemble methods use multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone. Unlike a statistical ensemble in statistical mechanics, which is usually infinite, a machine learning ensemble consists of only a concrete finite set of alternative models, but typically allows for much more flexible structure to exist among those alternatives.
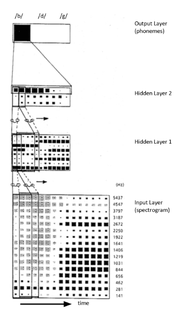
Time delay neural network (TDNN) is a multilayer artificial neural network architecture whose purpose is to 1) classify patterns with shift-invariance, and 2) model context at each layer of the network.
Multispectral remote sensing is the collection and analysis of reflected, emitted, or back-scattered energy from an object or an area of interest in multiple bands of regions of the electromagnetic spectrum. Subcategories of multispectral remote sensing include hyperspectral, in which hundreds of bands are collected and analyzed, and ultraspectral remote sensing where many hundreds of bands are used. The main purpose of multispectral imaging is the potential to classify the image using multispectral classification. This is a much faster method of image analysis than is possible by human interpretation.
There are many types of artificial neural networks (ANN).
Sparse distributed memory (SDM) is a mathematical model of human long-term memory introduced by Pentti Kanerva in 1988 while he was at NASA Ames Research Center. It is a generalized random-access memory (RAM) for long binary words. These words serve as both addresses to and data for the memory. The main attribute of the memory is sensitivity to similarity, meaning that a word can be read back not only by giving the original write address but also by giving one close to it, as measured by the number of mismatched bits.
In machine learning, feature learning or representation learning is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task.
Sparse coding is a representation learning method which aims at finding a sparse representation of the input data in the form of a linear combination of basic elements as well as those basic elements themselves. These elements are called atoms and they compose a dictionary. Atoms in the dictionary are not required to be orthogonal, and they may be an over-complete spanning set. This problem setup also allows the dimensionality of the signals being represented to be higher than the one of the signals being observed. The above two properties lead to having seemingly redundant atoms that allow multiple representations of the same signal but also provide an improvement in sparsity and flexibility of the representation.