The decibel is a relative unit of measurement equal to one tenth of a bel (B). It expresses the ratio of two values of a power or root-power quantity on a logarithmic scale. Two signals whose levels differ by one decibel have a power ratio of 101/10 or root-power ratio of 101⁄20.

Frequency modulation (FM) is the encoding of information in a carrier wave by varying the instantaneous frequency of the wave. The technology is used in telecommunications, radio broadcasting, signal processing, and computing.
A fricative is a consonant produced by forcing air through a narrow channel made by placing two articulators close together. These may be the lower lip against the upper teeth, in the case of ; the back of the tongue against the soft palate in the case of German ; or the side of the tongue against the molars, in the case of Welsh. This turbulent airflow is called frication.
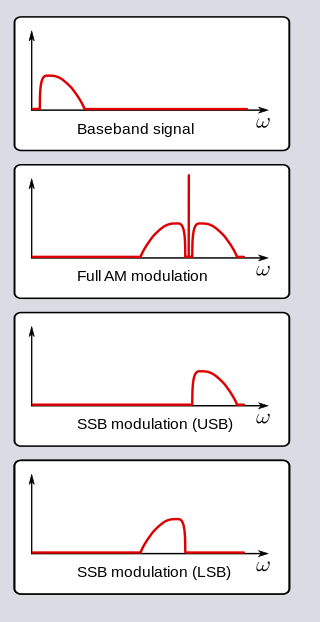
In radio communications, single-sideband modulation (SSB) or single-sideband suppressed-carrier modulation (SSB-SC) is a type of modulation used to transmit information, such as an audio signal, by radio waves. A refinement of amplitude modulation, it uses transmitter power and bandwidth more efficiently. Amplitude modulation produces an output signal the bandwidth of which is twice the maximum frequency of the original baseband signal. Single-sideband modulation avoids this bandwidth increase, and the power wasted on a carrier, at the cost of increased device complexity and more difficult tuning at the receiver.

The human voice consists of sound made by a human being using the vocal tract, including talking, singing, laughing, crying, screaming, shouting, humming or yelling. The human voice frequency is specifically a part of human sound production in which the vocal folds are the primary sound source.
Signal-to-noise ratio is a measure used in science and engineering that compares the level of a desired signal to the level of background noise. SNR is defined as the ratio of signal power to noise power, often expressed in decibels. A ratio higher than 1:1 indicates more signal than noise.
The field of articulatory phonetics is a subfield of phonetics that studies articulation and ways that humans produce speech. Articulatory phoneticians explain how humans produce speech sounds via the interaction of different physiological structures. Generally, articulatory phonetics is concerned with the transformation of aerodynamic energy into acoustic energy. Aerodynamic energy refers to the airflow through the vocal tract. Its potential form is air pressure; its kinetic form is the actual dynamic airflow. Acoustic energy is variation in the air pressure that can be represented as sound waves, which are then perceived by the human auditory system as sound.
In phonetics, nasalization is the production of a sound while the velum is lowered, so that some air escapes through the nose during the production of the sound by the mouth. Examples of archetypal nasal sounds include and.
Esophageal speech, also known as esophageal voice, is an airstream mechanism for speech that involves oscillation of the esophagus. This contrasts with traditional laryngeal speech, which involves oscillation of the vocal folds. In esophageal speech, pressurized air is injected into the upper esophagus and then released in a controlled manner to create the airstream necessary for speech. Esophageal speech is a learned skill that requires speech training and much practice. On average it takes 6 months to a year to learn this form of speech. Because of the high level of difficulty in learning esophageal speech, some patients are unable to master the skill.

The acoustic reflex is an involuntary muscle contraction that occurs in the middle ear in response to loud sound stimuli or when the person starts to vocalize.

Audiometry is a branch of audiology and the science of measuring hearing acuity for variations in sound intensity and pitch and for tonal purity, involving thresholds and differing frequencies. Typically, audiometric tests determine a subject's hearing levels with the help of an audiometer, but may also measure ability to discriminate between different sound intensities, recognize pitch, or distinguish speech from background noise. Acoustic reflex and otoacoustic emissions may also be measured. Results of audiometric tests are used to diagnose hearing loss or diseases of the ear, and often make use of an audiogram.

Kenneth Noble Stevens was the Clarence J. LeBel Professor of Electrical Engineering and Computer Science, and professor of health sciences and technology at the research laboratory of electronics at MIT. Stevens was head of the speech communication group in MIT's research laboratory of electronics (RLE), and was one of the world's leading scientists in acoustic phonetics.
Velopharyngeal inadequacy is a malfunction of a velopharyngeal mechanism which is responsible for directing the transmission of sound energy and air pressure in both the oral cavity and the nasal cavity. When this mechanism is impaired in some way, the valve does not fully close, and a condition known as 'velopharyngeal inadequacy' can develop. VPI can either be congenital or acquired later in life.

A palatal obturator is a prosthesis that totally occludes an opening such as an oronasal fistula. They are similar to dental retainers, but without the front wire. Palatal obturators are typically short-term prosthetics used to close defects of the hard/soft palate that may affect speech production or cause nasal regurgitation during feeding. Following surgery, there may remain a residual orinasal opening on the palate, alveolar ridge, or vestibule of the larynx. A palatal obturator may be used to compensate for hypernasality and to aid in speech therapy targeting correction of compensatory articulation caused by the cleft palate. In simpler terms, a palatal obturator covers any fistulas in the roof of the mouth that lead to the nasal cavity, providing the wearer with a plastic/acrylic, removable roof of the mouth, which aids in speech, eating, and proper air flow.
Velopharyngeal insufficiency is a disorder of structure that causes a failure of the velum to close against the posterior pharyngeal wall during speech in order to close off the nose during oral speech production. This is important because speech requires sound and airflow to be directed into the oral cavity (mouth) for the production of all speech sound with the exception of nasal sounds. If complete closure does not occur during speech, this can cause hypernasality and/or audible nasal emission during speech. In addition, there may be inadequate airflow to produce most consonants, making them sound weak or omitted.
Nasometry refers to measurement of the modulation of the area of the velopharyngeal opening, using movements of the velum and pharyngeal walls, in speech and singing. The velopharyngeal opening connects the oral air passageway with the nasal air passageway. The size of this velopharyngeal opening generally controls the nasality of the resulting speech or singing.

An audio analyzer is a test and measurement instrument used to objectively quantify the audio performance of electronic and electro-acoustical devices. Audio quality metrics cover a wide variety of parameters, including level, gain, noise, harmonic and intermodulation distortion, frequency response, relative phase of signals, interchannel crosstalk, and more. In addition, many manufacturers have requirements for behavior and connectivity of audio devices that require specific tests and confirmations.

Hypernasal speech is a disorder that causes abnormal resonance in a human's voice due to increased airflow through the nose during speech. It is caused by an open nasal cavity resulting from an incomplete closure of the soft palate and/or velopharyngeal sphincter. In normal speech, nasality is referred to as nasalization and is a linguistic category that can apply to vowels or consonants in a specific language. The primary underlying physical variable determining the degree of nasality in normal speech is the opening and closing of a velopharyngeal passage way between the oral vocal tract and the nasal vocal tract. In the normal vocal tract anatomy, this opening is controlled by lowering and raising the velum or soft palate, to open or close, respectively, the velopharyngeal passageway.

A velopharyngeal fricative, also known as a posterior nasal fricative, is a sound produced by some children with speech disorders, including some with a cleft palate, as a substitute for sibilants, which cannot be produced with a cleft palate. It results from "the approximation but inadequate closure of the upper border of the velum and the posterior pharyngeal wall." To produce a velopharyngeal fricative, the soft palate approaches the pharyngeal wall and narrows the velopharyngeal port, such that the restricted port creates fricative turbulence in air forced through it into the nasal cavity. The articulation may be aided by a posterior positioning of the tongue and may involve velar flutter.
Temporal envelope (ENV) and temporal fine structure (TFS) are changes in the amplitude and frequency of sound perceived by humans over time. These temporal changes are responsible for several aspects of auditory perception, including loudness, pitch and timbre perception and spatial hearing.
