In reliability engineering, the term availability has the following meanings:
Depending on the field, maintainability can have slightly different meanings:

Fault tree analysis (FTA) is a type of failure analysis in which an undesired state of a system is examined. This analysis method is mainly used in safety engineering and reliability engineering to understand how systems can fail, to identify the best ways to reduce risk and to determine event rates of a safety accident or a particular system level (functional) failure. FTA is used in the aerospace, nuclear power, chemical and process, pharmaceutical, petrochemical and other high-hazard industries; but is also used in fields as diverse as risk factor identification relating to social service system failure. FTA is also used in software engineering for debugging purposes and is closely related to cause-elimination technique used to detect bugs.

The technical meaning of maintenance involves functional checks, servicing, repairing or replacing of necessary devices, equipment, machinery, building infrastructure, and supporting utilities in industrial, business, and residential installations. Over time, this has come to include multiple wordings that describe various cost-effective practices to keep equipment operational; these activities occur either before or after a failure.
In systems engineering, dependability is a measure of a system's availability, reliability, maintainability, and in some cases, other characteristics such as durability, safety and security. In real-time computing, dependability is the ability to provide services that can be trusted within a time-period. The service guarantees must hold even when the system is subject to attacks or natural failures.
Failure mode and effects analysis is the process of reviewing as many components, assemblies, and subsystems as possible to identify potential failure modes in a system and their causes and effects. For each component, the failure modes and their resulting effects on the rest of the system are recorded in a specific FMEA worksheet. There are numerous variations of such worksheets. An FMEA can be a qualitative analysis, but may be put on a quantitative basis when mathematical failure rate models are combined with a statistical failure mode ratio database. It was one of the first highly structured, systematic techniques for failure analysis. It was developed by reliability engineers in the late 1950s to study problems that might arise from malfunctions of military systems. An FMEA is often the first step of a system reliability study.
In engineering, damage tolerance is a property of a structure relating to its ability to sustain defects safely until repair can be effected. The approach to engineering design to account for damage tolerance is based on the assumption that flaws can exist in any structure and such flaws propagate with usage. This approach is commonly used in aerospace engineering, mechanical engineering, and civil engineering to manage the extension of cracks in structure through the application of the principles of fracture mechanics. A structure is considered to be damage tolerant if a maintenance program has been implemented that will result in the detection and repair of accidental damage, corrosion and fatigue cracking before such damage reduces the residual strength of the structure below an acceptable limit.
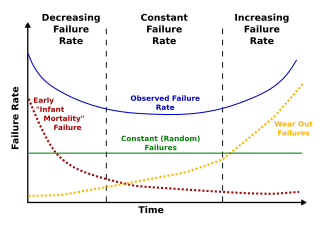
The bathtub curve is a particular shape of a failure rate graph. This graph is used in reliability engineering and deterioration modeling. The 'bathtub' refers to the shape of a line that curves up at both ends, similar in shape to a bathtub. The bathtub curve has 3 regions:
- The first region has a decreasing failure rate due to early failures.
- The middle region is a constant failure rate due to random failures.
- The last region is an increasing failure rate due to wear-out failures.
Failure rate is the frequency with which an engineered system or component fails, expressed in failures per unit of time. It is usually denoted by the Greek letter λ (lambda) and is often used in reliability engineering.
Prognostics is an engineering discipline focused on predicting the time at which a system or a component will no longer perform its intended function. This lack of performance is most often a failure beyond which the system can no longer be used to meet desired performance. The predicted time then becomes the remaining useful life (RUL), which is an important concept in decision making for contingency mitigation. Prognostics predicts the future performance of a component by assessing the extent of deviation or degradation of a system from its expected normal operating conditions. The science of prognostics is based on the analysis of failure modes, detection of early signs of wear and aging, and fault conditions. An effective prognostics solution is implemented when there is sound knowledge of the failure mechanisms that are likely to cause the degradations leading to eventual failures in the system. It is therefore necessary to have initial information on the possible failures in a product. Such knowledge is important to identify the system parameters that are to be monitored. Potential uses for prognostics is in condition-based maintenance. The discipline that links studies of failure mechanisms to system lifecycle management is often referred to as prognostics and health management (PHM), sometimes also system health management (SHM) or—in transportation applications—vehicle health management (VHM) or engine health management (EHM). Technical approaches to building models in prognostics can be categorized broadly into data-driven approaches, model-based approaches, and hybrid approaches.
Reliability engineering is a sub-discipline of systems engineering that emphasizes the ability of equipment to function without failure. Reliability describes the ability of a system or component to function under stated conditions for a specified period of time. Reliability is closely related to availability, which is typically described as the ability of a component or system to function at a specified moment or interval of time.

In engineering, redundancy is the intentional duplication of critical components or functions of a system with the goal of increasing reliability of the system, usually in the form of a backup or fail-safe, or to improve actual system performance, such as in the case of GNSS receivers, or multi-threaded computer processing.
Fault tolerance is the property that enables a system to continue operating properly in the event of the failure of one or more faults within some of its components. If its operating quality decreases at all, the decrease is proportional to the severity of the failure, as compared to a naively designed system, in which even a small failure can cause total breakdown. Fault tolerance is particularly sought after in high-availability, mission-critical, or even life-critical systems. The ability of maintaining functionality when portions of a system break down is referred to as graceful degradation.
Environmental stress screening (ESS) refers to the process of exposing a newly manufactured or repaired product or component to stresses such as thermal cycling and vibration in order to force latent defects to manifest themselves by permanent or catastrophic failure during the screening process. The surviving population, upon completion of screening, can be assumed to have a higher reliability than a similar unscreened population.
Maintenance-free operating period (MFOP) is an alternative measure of performance to the mean time between failures (MTBF), defined as the time period during which a device will be able to perform each of its intended functions, requiring only a minimal degree of maintenance. It was originally proposed in 1996 by the United Kingdom's Ministry of Defence, with intended application to military aircraft.
An intermittent fault, often called simply an "intermittent", is a malfunction of a device or system that occurs at intervals, usually irregular, in a device or system that functions normally at other times. Intermittent faults are common to all branches of technology, including computer software. An intermittent fault is caused by several contributing factors, some of which may be effectively random, which occur simultaneously. The more complex the system or mechanism involved, the greater the likelihood of an intermittent fault.
Integrated vehicle health management (IVHM) or integrated system health management (ISHM) is the unified capability of systems to assess the current or future state of the member system health and integrate that picture of system health within a framework of available resources and operational demand.
A captive power plant, also called autoproducer or embedded generation, is an electricity generation facility used and managed by an industrial or commercial energy user for their own energy consumption. Captive power plants can operate off-grid or they can be connected to the electric grid to exchange excess generation.

A domino effect accident is an accident in which a primary undesired event sequentially or simultaneously triggers one or more secondary undesired events in nearby equipment or facilities, leading to secondary accidents more severe than the primary event. Thus, a domino effect accident is actually a chain of multiple events, which can be likened to a falling row of dominoes. The term knock-on accident is also used.
In the mathematical theory of probability, a generalized renewal process (GRP) or G-renewal process is a stochastic point process used to model failure/repair behavior of repairable systems in reliability engineering. Poisson point process is a particular case of GRP.
