A microsatellite is a tract of repetitive DNA in which certain DNA motifs are repeated, typically 5–50 times. Microsatellites occur at thousands of locations within an organism's genome. They have a higher mutation rate than other areas of DNA leading to high genetic diversity. Microsatellites are often referred to as short tandem repeats (STRs) by forensic geneticists and in genetic genealogy, or as simple sequence repeats (SSRs) by plant geneticists.
An inverted repeat is a single stranded sequence of nucleotides followed downstream by its reverse complement. The intervening sequence of nucleotides between the initial sequence and the reverse complement can be any length including zero. For example, 5'---TTACGnnnnnnCGTAA---3' is an inverted repeat sequence. When the intervening length is zero, the composite sequence is a palindromic sequence.
In a chain-like biological molecule, such as a protein or nucleic acid, a structural motif is a common three-dimensional structure that appears in a variety of different, evolutionarily unrelated molecules. A structural motif does not have to be associated with a sequence motif; it can be represented by different and completely unrelated sequences in different proteins or RNA.

Helicases are a class of enzymes thought to be vital to all organisms. Their main function is to unpack an organism's genetic material. Helicases are motor proteins that move directionally along a nucleic acid phosphodiester backbone, separating two hybridized nucleic acid strands, using energy from ATP hydrolysis. There are many helicases, representing the great variety of processes in which strand separation must be catalyzed. Approximately 1% of eukaryotic genes code for helicases.

In genetics and bioinformatics, a single-nucleotide polymorphism is a germline substitution of a single nucleotide at a specific position in the genome that is present in a sufficiently large fraction of the population.
Satellite DNA consists of very large arrays of tandemly repeating, non-coding DNA. Satellite DNA is the main component of functional centromeres, and form the main structural constituent of heterochromatin.
DNA gyrase, or simply gyrase, is an enzyme within the class of topoisomerase and is a subclass of Type II topoisomerases that reduces topological strain in an ATP dependent manner while double-stranded DNA is being unwound by elongating RNA-polymerase or by helicase in front of the progressing replication fork. It is the only known enzyme to actively contribute negative supercoiling to DNA, while it also is capable of relaxing positive supercoils. It does so by looping the template to form a crossing, then cutting one of the double helices and passing the other through it before releasing the break, changing the linking number by two in each enzymatic step. This process occurs in bacteria, whose single circular DNA is cut by DNA gyrase and the two ends are then twisted around each other to form supercoils. Gyrase is also found in eukaryotic plastids: it has been found in the apicoplast of the malarial parasite Plasmodium falciparum and in chloroplasts of several plants. Bacterial DNA gyrase is the target of many antibiotics, including nalidixic acid, novobiocin, albicidin, and ciprofloxacin.

Helix-turn-helix is a DNA-binding protein (DBP). The helix-turn-helix (HTH) is a major structural motif capable of binding DNA. Each monomer incorporates two α helices, joined by a short strand of amino acids, that bind to the major groove of DNA. The HTH motif occurs in many proteins that regulate gene expression. It should not be confused with the helix–loop–helix motif.

Triple-stranded DNA is a DNA structure in which three oligonucleotides wind around each other and form a triple helix. In triple-stranded DNA, the third strand binds to a B-form DNA double helix by forming Hoogsteen base pairs or reversed Hoogsteen hydrogen bonds.

In molecular biology, the term double helix refers to the structure formed by double-stranded molecules of nucleic acids such as DNA. The double helical structure of a nucleic acid complex arises as a consequence of its secondary structure, and is a fundamental component in determining its tertiary structure. The term entered popular culture with the publication in 1968 of The Double Helix: A Personal Account of the Discovery of the Structure of DNA by James Watson.

A leucine zipper is a common three-dimensional structural motif in proteins. They were first described by Landschulz and collaborators in 1988 when they found that an enhancer binding protein had a very characteristic 30-amino acid segment and the display of these amino acid sequences on an idealized alpha helix revealed a periodic repetition of leucine residues at every seventh position over a distance covering eight helical turns. The polypeptide segments containing these periodic arrays of leucine residues were proposed to exist in an alpha-helical conformation and the leucine side chains from one alpha helix interdigitate with those from the alpha helix of a second polypeptide, facilitating dimerization.
A DNA-binding domain (DBD) is an independently folded protein domain that contains at least one structural motif that recognizes double- or single-stranded DNA. A DBD can recognize a specific DNA sequence or have a general affinity to DNA. Some DNA-binding domains may also include nucleic acids in their folded structure.

In molecular biology, G-quadruplex secondary structures (G4) are formed in nucleic acids by sequences that are rich in guanine. They are helical in shape and contain guanine tetrads that can form from one, two or four strands. The unimolecular forms often occur naturally near the ends of the chromosomes, better known as the telomeric regions, and in transcriptional regulatory regions of multiple genes, both in microbes and across vertebrates including oncogenes in humans. Four guanine bases can associate through Hoogsteen hydrogen bonding to form a square planar structure called a guanine tetrad, and two or more guanine tetrads can stack on top of each other to form a G-quadruplex.

Histone H2A is one of the five main histone proteins involved in the structure of chromatin in eukaryotic cells.

A leucine-rich repeat (LRR) is a protein structural motif that forms an α/β horseshoe fold. It is composed of repeating 20–30 amino acid stretches that are unusually rich in the hydrophobic amino acid leucine. These tandem repeats commonly fold together to form a solenoid protein domain, termed leucine-rich repeat domain. Typically, each repeat unit has beta strand-turn-alpha helix structure, and the assembled domain, composed of many such repeats, has a horseshoe shape with an interior parallel beta sheet and an exterior array of helices. One face of the beta sheet and one side of the helix array are exposed to solvent and are therefore dominated by hydrophilic residues. The region between the helices and sheets is the protein's hydrophobic core and is tightly sterically packed with leucine residues.
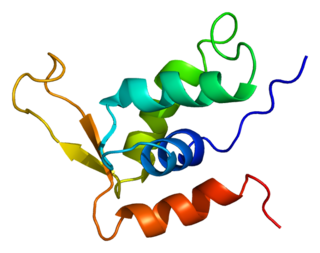
Forkhead box protein K2 is a protein that in humans is encoded by the FOXK2 gene.
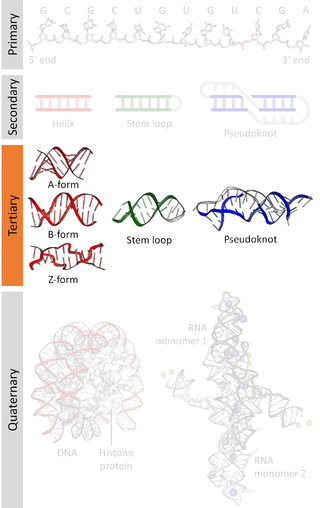
Nucleic acid tertiary structure is the three-dimensional shape of a nucleic acid polymer. RNA and DNA molecules are capable of diverse functions ranging from molecular recognition to catalysis. Such functions require a precise three-dimensional structure. While such structures are diverse and seemingly complex, they are composed of recurring, easily recognizable tertiary structural motifs that serve as molecular building blocks. Some of the most common motifs for RNA and DNA tertiary structure are described below, but this information is based on a limited number of solved structures. Many more tertiary structural motifs will be revealed as new RNA and DNA molecules are structurally characterized.
Histone variants are proteins that substitute for the core canonical histones in nucleosomes in eukaryotes and often confer specific structural and functional features. The term might also include a set of linker histone (H1) variants, which lack a distinct canonical isoform. The differences between the core canonical histones and their variants can be summarized as follows: (1) canonical histones are replication-dependent and are expressed during the S-phase of cell cycle whereas histone variants are replication-independent and are expressed during the whole cell cycle; (2) in animals, the genes encoding canonical histones are typically clustered along the chromosome, are present in multiple copies and are among the most conserved proteins known, whereas histone variants are often single-copy genes and show high degree of variation among species; (3) canonical histone genes lack introns and use a stem loop structure at the 3’ end of their mRNA, whereas histone variant genes may have introns and their mRNA tail is usually polyadenylated. Complex multicellular organisms typically have a large number of histone variants providing a variety of different functions. Recent data are accumulating about the roles of diverse histone variants highlighting the functional links between variants and the delicate regulation of organism development.

An array of protein tandem repeats is defined as several adjacent copies having the same or similar sequence motifs. These periodic sequences are generated by internal duplications in both coding and non-coding genomic sequences. Repetitive units of protein tandem repeats are considerably diverse, ranging from the repetition of a single amino acid to domains of 100 or more residues.
Retrozymes are a family of retrotransposons first discovered in the genomes of plants but now also known in genomes of animals. Retrozymes contain a hammerhead ribozyme (HHR) in their sequences, although they do not possess any coding regions. Retrozymes are nonautonomous retroelements, and so borrow proteins from other elements to move into new regions of a genome. Retrozymes are actively transcribed into covalently closed circular RNAs and are detected in both polarities, which may indicate the use of rolling circle replication in their lifecycle.