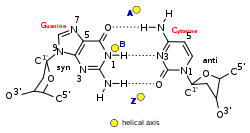
Z-DNA is one of the many possible double helical structures of DNA. It is a left-handed double helical structure in which the helix winds to the left in a zigzag pattern, instead of to the right, like the more common B-DNA form. Z-DNA is thought to be one of three biologically active double-helical structures along with A-DNA and B-DNA.
Left-handed DNA was first proposed by Robert Wells and colleagues, as the structure of a repeating polymer of inosine–cytosine.[1] They observed a "reverse" circular dichroism spectrum for such DNAs, and interpreted this incorrectly to mean that the strands wrapped around one another in a left-handed fashion. The relationship between Z-DNA and the more familiar B-DNA was indicated by the work of Pohl and Jovin,[2] who showed that the ultraviolet circular dichroism of poly(dG-dC) was nearly inverted in 4Msodium chloride solution and that the structure of poly d(I–C)·poly d(I–C) was in fact a right-handed D-DNA conformation. The suspicion that this was the result of a conversion from B-DNA to Z-DNA was confirmed by examining the Raman spectra of these solutions and the Z-DNA crystals.[3] Subsequently, a crystal structure of "Z-DNA" was published which turned out to be the first single-crystal X-ray structure of a DNA fragment (a self-complementary DNA hexamer d(CG)3). It was resolved as a left-handed double helix with two antiparallel chains that were held together by Watson–Crick base pairs (see X-ray crystallography). It was solved by Andrew H. J. Wang, Alexander Rich, and coworkers in 1979 at MIT.[4] The crystallisation of a B- to Z-DNA junction in 2005[5] provided a better understanding of the potential role Z-DNA plays in cells. Whenever a segment of Z-DNA forms, there must be B–Z junctions at its two ends, interfacing it to the B-form of DNA found in the rest of the genome.
In 2007, the RNA version of Z-DNA, Z-RNA, was described as a transformed version of an A-RNA double helix into a left-handed helix.[6] The transition from A-RNA to Z-RNA, however, was already described in 1984.[7]
Structure
B–Z junction bound to a Z-DNA binding domain. Note the two highlighted extruded bases. From PDB: 2ACJ.
Z-DNA is quite different from the right-handed forms. In fact, Z-DNA is often compared against B-DNA in order to illustrate the major differences. The Z-DNA helix is left-handed and has a structure that repeats every other base pair. The major and minor grooves, unlike A- and B-DNA, show little difference in width. Formation of this structure is generally unfavourable, although certain conditions can promote it; such as alternating purine–pyrimidine sequence (especially poly(dGC)2), negative DNA supercoiling or high salt and some cations (all at physiological temperature, 37°C, and pH 7.3–7.4). Z-DNA can form a junction with B-DNA (called a "B-to-Z junction box") in a structure which involves the extrusion of a base pair.[8] The Z-DNA conformation has been difficult to study because it does not exist as a stable feature of the double helix. Instead, it is a transient structure that is occasionally induced by biological activity and then quickly disappears.[9]
Predicting Z-DNA structure
It is possible to predict the likelihood of a DNA sequence forming a Z-DNA structure. An algorithm for predicting the propensity of DNA to flip from the B-form to the Z-form, ZHunt, was written by P. Shing Ho in 1984 at MIT.[10] This algorithm was later developed by Tracy Camp, P. Christoph Champ, Sandor Maurice, and Jeffrey M. Vargason for genome-wide mapping of Z-DNA (with Ho as the principal investigator).[11]
Pathway of formation of Z-DNA from B-DNA
Since the discovery and crystallization of Z-DNA in 1979, the configuration has left scientists puzzled about the pathway and mechanism from the B-DNA configuration to the Z-DNA configuration.[12] The conformational change from B-DNA to the Z-DNA structure was unknown at the atomic level, but in 2010, computer simulations conducted by Lee et al. were able to computationally determine that the step-wise propagation of a B-to-Z transition would provide a lower energy barrier than the previously hypothesized concerted mechanism.[13] Since this was computationally proven, the pathway would still need to be tested experimentally in the lab for further confirmation and validity, in which Lee et al. specifically states in their journal article, "The current [computational] result could be tested by Single-molecule FRET (smFRET) experiments in the future."[13] In 2018, the pathway from B-DNA to Z-DNA was experimentally proven using smFRET assays.[14] This was performed by measuring the intensity values between the donor and acceptor fluorescent dyes, also known as Fluorophores, in relation to each other as they exchange electrons, while tagged onto a DNA molecule.[15][16] The distances between the fluorophores could be used to quantitatively calculate the changes in proximity of the dyes and conformational changes in the DNA. A Z-DNA high affinity binding protein, hZαADAR1,[17] was used at varying concentrations to induce the transformation from B-DNA to Z-DNA.[14] The smFRET assays revealed a B* transition state, which formed as the binding of hZαADAR1 accumulated on the B-DNA structure and stabilized it.[14] This step occurs to avoid high junction energy, in which the B-DNA structure is allowed to undergo a conformational change to the Z-DNA structure without a major, disruptive change in energy. This result coincides with the computational results of Lee et al. proving the mechanism to be step-wise and its purpose being that it provides a lower energy barrier for the conformational change from the B-DNA to Z-DNA configuration.[13] Contrary to the previous notion, the binding proteins do not actually stabilize the Z-DNA conformation after it is formed, but instead they actually promote the formation of the Z-DNA directly from the B* conformation, which is formed by the B-DNA structure being bound by high affinity proteins.[14]
Biological significance
A biological role for Z-DNA in the regulation of type I interferon responses has been confirmed in studies of three well-characterized rare Mendelian Diseases: Dyschromatosis Symmetrica Hereditaria (OMIM: 127400), Aicardi-Goutières syndrome (OMIM: 615010) and Bilateral Striatal Necrosis/Dystonia. Families with haploid ADAR transcriptome enabled mapping of Zα variants directly to disease, showing that genetic information is encoded in DNA by both shape and sequence.[18] A role in regulating type I interferon responses in cancer is also supported by findings that 40% of a panel of tumors were dependent on the ADAR enzyme for survival.[19]
In previous studies, Z-DNA was linked to both Alzheimer's disease and systemic lupus erythematosus. To showcase this, a study was conducted on the DNA found in the hippocampus of brains that were normal, moderately affected with Alzheimer's disease, and severely affected with Alzheimer's disease. Through the use of circular dichroism, this study showed the presence of Z-DNA in the DNA of those severely affected.[20] In this study it was also found that major portions of the moderately affected DNA was in the B-Z intermediate conformation. This is significant because from these findings it was concluded that the transition from B-DNA to Z-DNA is dependent on the progression of Alzheimer's disease.[20] Additionally, Z-DNA is associated with systemic lupus erythematosus (SLE) through the presence of naturally occurring antibodies. Significant amounts of anti Z-DNA antibodies were found in SLE patients and were not present in other rheumatic diseases.[21] There are two types of these antibodies. Through radioimmunoassay, it was found that one interacts with the bases exposed on the surface of Z-DNA and denatured DNA, while the other exclusively interacts with the zig-zag backbone of only Z-DNA. Similar to that found in Alzheimer's disease, the antibodies vary depending on the stage of the disease, with maximal antibodies in the most active stages of SLE.
Z-DNA in transcription
Z-DNA is commonly believed to provide torsional strain relief during transcription, and it is associated with negative supercoiling.[5][22] However, while supercoiling is associated with both DNA transcription and replication, Z-DNA formation is primarily linked to the rate of transcription.[23]
A study of human chromosome 22 showed a correlation between Z-DNA forming regions and promoter regions for nuclear factor I. This suggests that transcription in some human genes may be regulated by Z-DNA formation and nuclear factor I activation.[11]
Z-DNA sequences upstream of promoter regions have been shown to stimulate transcription. The greatest increase in activity is observed when the Z-DNA sequence is placed three helical turns after the promoter sequence. Furthermore, using micrococcal nuclease-crosslinking technique,[24] Z-DNA is unlikely to form nucleosomes, which are often located before and/or after a Z-DNA forming sequence. Because of this property, Z-DNA is hypothesized to code for the boundary in nucleosome positioning. Since the placement of nucleosomes influences the binding of transcription factors, Z-DNA is thought to regulate the rate of transcription.[24]
Developed behind the pathway of RNA polymerase through negative supercoiling, Z-DNA formed via active transcription has been shown to increase genetic instability, creating a propensity towards mutagenesis near promoters.[25] A study on Escherichia coli found that gene deletions spontaneously occur in plasmid regions containing Z-DNA-forming sequences.[26] In mammalian cells, the presence of such sequences was found to produce large genomic fragment deletions due to chromosomal double-strand breaks. Both of these genetic modifications have been linked to the gene translocations found in cancers such as leukemia and lymphoma, since breakage regions in tumor cells have been plotted around Z-DNA-forming sequences.[25] However, the smaller deletions in bacterial plasmids have been associated with replication slippage, while the larger deletions associated with mammalian cells are caused by non-homologous end-joining repair, which is known to be prone to error.[25][26]
The toxic effect of ethidium bromide (EtBr) on trypanosomas is caused by shift of their kinetoplastid DNA to Z-form. The shift is caused by intercalation of EtBr and subsequent loosening of DNA structure that leads to unwinding of DNA, shift to Z-form and inhibition of DNA replication.[27]
Discovery of the Zα domain
The first domain to bind Z-DNA with high affinity was discovered in ADAR1 using an approach developed by Alan Herbert.[28][29]Crystallographic and NMR studies confirmed the biochemical findings that this domain bound Z-DNA in a non-sequence-specific manner.[30][31][32] Related domains were identified in a number of other proteins through sequence homology.[29] The identification of the Zα domain provided a tool for other crystallographic studies that lead to the characterization of Z-RNA and the B–Z junction. Biological studies suggested that the Z-DNA binding domain of ADAR1 may localize this enzyme that modifies the sequence of the newly formed RNA to sites of active transcription.[33][34] A role for Zα, Z-DNA and Z-RNA in defense of the genome against the invasion of Alu retro-elements in humans has evolved into a mechanism for the regulation of innate immune responses to dsRNA. Mutations in Zα are causal for human interferonopathies such as the Mendelian Aicardi-Goutières Syndrome.[35][18]Additionally, Zα domains are demonstrated to localize at the stress granules because of their innate ability in binding nucleic acid. Furthermore, different Zα domains bind to the Z conformation of nucleic acid differently providing important avenues for specific targeting in drug discovery.
Consequences of Z-DNA binding to vaccinia E3L protein
As Z-DNA has been researched more thoroughly, it has been discovered that the structure of Z-DNA can bind to Z-DNA binding proteins through van der Waal forces and hydrogen bonding.[36] One example of a Z-DNA binding protein is the vaccinia E3L protein, which is a product of the E3L gene and mimics a mammalian protein that binds Z-DNA.[37][38] Not only does the E3L protein have affinity to Z-DNA, it has also been found to play a role in the level of severity of virulence in mice caused by vaccinia virus, a type of poxvirus. Two critical components to the E3L protein that determine virulence are the N-terminus and the C-terminus. The N-terminus is made of up a sequence similar to that of the Zα domain, also called Adenosine deaminase z-alpha domain, while the C-terminus is composed of a double stranded RNA binding motif.[37] Through research done by Kim, Y. et al. at the Massachusetts Institute of Technology, it was shown that replacing the N-terminus of the E3L protein with a Zα domain sequence, containing 14 Z-DNA binding residues similar to E3L, had little to no effect on pathogenicity of the virus in mice.[37] In Contrast, Kim, Y. et al. also found that deleting all 83 residues of the E3L N-terminus resulted in decreased virulence. This supports their claim that the N-terminus containing the Z-DNA binding residues is necessary for virulence.[37] Overall, these findings show that the similar Z-DNA binding residues within the N-terminus of the E3L protein and the Zα domain are the most important structural factors determining virulence caused by the vaccinia virus, while amino acid residues not involved in Z-DNA binding have little to no effect. A future implication of these findings includes reducing Z-DNA binding of E3L in vaccines containing the vaccinia virus so negative reactions to the virus can be minimized in humans.[37]
Furthermore, Alexander Rich and Jin-Ah Kwon found that E3L acts as a transactivator for human IL-6, NF-AT, and p53 genes. Their results show that HeLa cells containing E3L had increased expression of human IL-6, NF-AT, and p53 genes and point mutations or deletions of certain Z-DNA binding amino acid residues decreased that expression.[36] Specifically, mutations in Tyr 48 and Pro 63 were found to reduce transactivation of the previously mentioned genes, as a result of loss of hydrogen bonding and london dispersion forces between E3L and the Z-DNA.[36] Overall, these results show that decreasing the bonds and interactions between Z-DNA and Z-DNA binding proteins decreases both virulence and gene expression, hence showing the importance of having bonds between Z-DNA and the E3L binding protein.
Comparison geometries of some DNA forms
Side view of A-, B-, and Z-DNA.The helix axis of A-, B-, and Z-DNA.
Geometry attributes of A-, B, and Z-DNA[39][40][41]
↑ Mitsui, Y.; Langridge, R.; Shortle, B. E.; Cantor, C. R.; Grant, R. C.; Kodama, M.; Wells, R. D. (1970). "Physical and enzymatic studies on poly d(I–C)·poly d(I–C), an unusual double-helical DNA". Nature. 228 (5277): 1166–1169. Bibcode:1970Natur.228.1166M. doi:10.1038/2281166a0. PMID4321098. S2CID4248932.
↑ Pohl, F. M.; Jovin, T. M. (1972). "Salt-induced co-operative conformational change of a synthetic DNA: equilibrium and kinetic studies with poly(dG-dC)". Journal of Molecular Biology. 67 (3): 375–396. doi:10.1016/0022-2836(72)90457-3. PMID5045303.
↑ Wang, A. H.; Quigley, G. J.; Kolpak, F. J.; Crawford, J. L.; van Boom, J. H.; van der Marel, G.; Rich, A. (1979). "Molecular structure of a left-handed double helical DNA fragment at atomic resolution". Nature. 282 (5740): 680–686. Bibcode:1979Natur.282..680W. doi:10.1038/282680a0. PMID514347. S2CID4337955.
↑ Wang, Andrew H.-J.; Quigley, Gary J.; Kolpak, Francis J.; Crawford, James L.; van Boom, Jacques H.; van der Marel, Gijs; Rich, Alexander (December 1979). "Molecular structure of a left-handed double helical DNA fragment at atomic resolution". Nature. 282 (5740): 680–686. Bibcode:1979Natur.282..680W. doi:10.1038/282680a0. ISSN0028-0836. PMID514347. S2CID4337955.
1 2 3 Lee, Juyong; Kim, Yang-Gyun; Kim, Kyeong Kyu; Seok, Chaok (2010-08-05). "Transition between B-DNA and Z-DNA: Free Energy Landscape for the B−Z Junction Propagation". The Journal of Physical Chemistry B. 114 (30): 9872–9881. CiteSeerX10.1.1.610.1717. doi:10.1021/jp103419t. ISSN1520-6106. PMID20666528.
1 2 Suram, Anitha; Rao, Jagannatha K. S.; S., Latha K.; A., Viswamitra M. (2002). "First Evidence to Show the Topological Change of DNA from B-DNA to Z-DNA Conformation in the Hippocampus of Alzheimer's Brain". NeuroMolecular Medicine. 2 (3): 289–298. doi:10.1385/nmm:2:3:289. ISSN1535-1084. PMID12622407. S2CID29059186.
↑ Schwartz, T.; Rould, M. A.; Lowenhaupt, K.; Herbert, A.; Rich, A. (1999). "Crystal structure of the Zα domain of the human editing enzyme ADAR1 bound to left-handed Z-DNA". Science. 284 (5421): 1841–1845. doi:10.1126/science.284.5421.1841. PMID10364558.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.