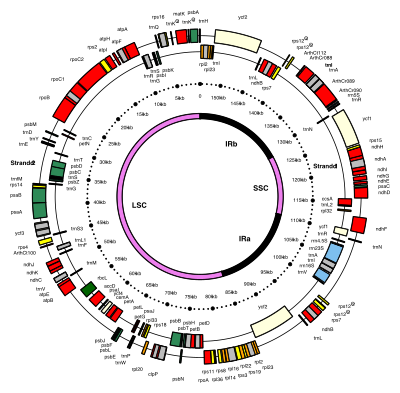
Chloroplast DNA Interactive gene map of chloroplast DNA from Nicotiana tabacum. Segments with labels on the inside reside on the B strand of DNA, segments with labels on the outside are on the A strand. Notches indicate introns.
The 154 kb chloroplast DNA map of a model flowering plant (Arabidopsis thaliana: Brassicaceae) showing genes and inverted repeats.
Chloroplast DNAs are circular, and are typically 120,000–170,000 base pairs long.[7][8][9] They can have a contour length of around 30–60 micrometers, and have a mass of about 80–130 million daltons.[10]
Most chloroplasts have their entire chloroplast genome combined into a single large ring, though those of dinophyte algae are a notable exception—their genome is broken up into about forty small plasmids, each 2,000–10,000 base pairs long.[11] Each minicircle contains one to three genes,[11] but blank plasmids, with no coding DNA, have also been found.
Chloroplast DNA has long been thought to have a circular structure, but some evidence suggests that chloroplast DNA more commonly takes a linear shape.[12] Over 95% of the chloroplast DNA in corn chloroplasts has been observed to be in branched linear form rather than individual circles.[11]
Inverted repeats
Many chloroplast DNAs contain two inverted repeats, which separate a long single copy section (LSC) from a short single copy section (SSC).[9]
The inverted repeats vary wildly in length, ranging from 4,000 to 25,000 base pairs long each.[11] Inverted repeats in plants tend to be at the upper end of this range, each being 20,000–25,000 base pairs long.[9][13] The inverted repeat regions usually contain three ribosomal RNA and two tRNA genes, but they can be expanded or reduced to contain as few as four or as many as over 150 genes.[11] While a given pair of inverted repeats are rarely completely identical, they are always very similar to each other, apparently resulting from concerted evolution.[11]
The inverted repeat regions are highly conserved among land plants, and accumulate few mutations.[9][13] Similar inverted repeats exist in the genomes of cyanobacteria and the other two chloroplast lineages (glaucophyta and rhodophyceæ), suggesting that they predate the chloroplast,[11] though some chloroplast DNAs like those of peas and a few red algae[11] have since lost the inverted repeats.[13][14] Others, like the red alga Porphyra flipped one of its inverted repeats (making them direct repeats).[11] It is possible that the inverted repeats help stabilize the rest of the chloroplast genome, as chloroplast DNAs which have lost some of the inverted repeat segments tend to get rearranged more.[14]
Nucleoids
Each chloroplast contains around 100 copies of its DNA in young leaves, declining to 15–20 copies in older leaves.[15] They are usually packed into nucleoids which can contain several identical chloroplast DNA rings. Many nucleoids can be found in each chloroplast.[10]
Though chloroplast DNA is not associated with true histones,[16] in red algae, a histone-like chloroplast protein (HC) coded by the chloroplast DNA that tightly packs each chloroplast DNA ring into a nucleoid has been found.[17]
In primitive red algae, the chloroplast DNA nucleoids are clustered in the center of a chloroplast, while in green plants and green algae, the nucleoids are dispersed throughout the stroma.[17]
More than 33,000 chloroplast genomes have been sequenced and are accessible via the NCBI organelle genome database.[18] The first chloroplast genomes were sequenced in 1986, from tobacco (Nicotiana tabacum)[19] and liverwort (Marchantia polymorpha).[20] Comparison of the gene sequences of the cyanobacteria Synechocystis to those of the chloroplast genome of Arabidopsis provided confirmation of the endosymbiotic origin of the chloroplast.[21][22] It also demonstrated the significant extent of gene transfer from the cyanobacterial ancestor to the nuclear genome.
In most plant species, the chloroplast genome encodes approximately 120 genes.[23][24] The genes primarily encode core components of the photosynthetic machinery and factors involved in their expression and assembly.[25] Across species of land plants, the set of genes encoded by the chloroplast genome is fairly conserved. This includes four ribosomal RNAs, approximately 30 tRNAs, 21 ribosomal proteins, and 4 subunits of the plastid-encoded RNA polymerase complex that are involved in plastid gene expression.[25] The large Rubisco subunit and 28 photosynthetic thylakoid proteins are encoded within the chloroplast genome.[25]
Chloroplast genome reduction and gene transfer
Over time, many parts of the chloroplast genome were transferred to the nuclear genome of the host,[7][8][26] a process called endosymbiotic gene transfer. As a result, the chloroplast genome is heavily reduced compared to that of free-living cyanobacteria. Chloroplasts may contain 60–100 genes whereas cyanobacteria often have more than 1500 genes in their genome.[27] The parasitic Pilostyles have even lost their plastid genes for tRNA.[28] Contrarily, there are only a few known instances where genes have been transferred to the chloroplast from various donors, including bacteria.[29][30][31]
Endosymbiotic gene transfer is how we know about the lost chloroplasts in many chromalveolate lineages. Even if a chloroplast is eventually lost, the genes it donated to the former host's nucleus persist, providing evidence for the lost chloroplast's existence. For example, while diatoms (a heterokontophyte) now have a red algal derived chloroplast, the presence of many green algal genes in the diatom nucleus provide evidence that the diatom ancestor (probably the ancestor of all chromalveolates too) had a green algal derived chloroplast at some point, which was subsequently replaced by the red chloroplast.[32]
In land plants, some 11–14% of the DNA in their nuclei can be traced back to the chloroplast,[33] up to 18% in Arabidopsis, corresponding to about 4,500 protein-coding genes.[34] There have been a few recent transfers of genes from the chloroplast DNA to the nuclear genome in land plants.[8]
Proteins encoded by the chloroplast
Of the approximately three-thousand proteins found in chloroplasts, some 95% of them are encoded by nuclear genes. Many of the chloroplast's protein complexes consist of subunits from both the chloroplast genome and the host's nuclear genome. As a result, protein synthesis must be coordinated between the chloroplast and the nucleus. The chloroplast is mostly under nuclear control, though chloroplasts can also give out signals regulating gene expression in the nucleus, called retrograde signaling.[35]
Protein synthesis within chloroplasts relies on an RNA polymerase coded by the chloroplast's own genome, which is related to RNA polymerases found in bacteria. Chloroplasts also contain a mysterious second RNA polymerase that is encoded by the plant's nuclear genome. The two RNA polymerases may recognize and bind to different kinds of promoters within the chloroplast genome.[36] The ribosomes in chloroplasts are similar to bacterial ribosomes.[37]
This section needs expansionwith: Genome size differences between algae and land plants, chloroplast stuff coded by the nucleus, DNA replication, NADPH redox, special tRNA synthetases, etc.. You can help by adding to it. (January 2013)
RNA editing in plastids
RNA editing is the insertion, deletion, and substitution of nucleotides in a mRNA transcript prior to translation to protein. The highly oxidative environment inside chloroplasts increases the rate of mutation so post-transcription repairs are needed to conserve functional sequences. The chloroplast editosome substitutes C -> U and U -> C at very specific locations on the transcript. This can change the codon for an amino acid or restore a non-functional pseudogene by adding an AUG start codon or removing a premature UAA stop codon.[38]
The editosome recognizes and binds to cis sequence upstream of the editing site. The distance between the binding site and editing site varies by gene and proteins involved in the editosome. Hundreds of different PPR proteins from the nuclear genome are involved in the RNA editing process. These proteins consist of 35-mer repeated amino acids, the sequence of which determines the cis binding site for the edited transcript.[38]
Basal land plants such as liverworts, mosses and ferns have hundreds of different editing sites while flowering plants typically have between thirty and forty. Parasitic plants such as Epifagus virginiana show a loss of RNA editing resulting in a loss of function for photosynthesis genes.[39]
DNA replication
Leading model of cpDNA replication
Chloroplast DNA replication via multiple D loop mechanisms. Adapted from Krishnan NM, Rao BJ's paper "A comparative approach to elucidate chloroplast genome replication."
The mechanism for chloroplast DNA (cpDNA) replication has not been conclusively determined, but two main models have been proposed. Scientists have attempted to observe chloroplast replication via electron microscopy since the 1970s.[40][41] The results of the microscopy experiments led to the idea that chloroplast DNA replicates using a double displacement loop (D-loop). As the D-loop moves through the circular DNA, it adopts a theta intermediary form, also known as a Cairns replication intermediate, and completes replication with a rolling circle mechanism.[40][12] Replication starts at specific points of origin. Multiple replication forks open up, allowing replication machinery to replicate the DNA. As replication continues, the forks grow and eventually converge. The new cpDNA structures separate, creating daughter cpDNA chromosomes.
In addition to the early microscopy experiments, this model is also supported by the amounts of deamination seen in cpDNA.[40] Deamination occurs when an amino group is lost and is a mutation that often results in base changes. When adenine is deaminated, it becomes hypoxanthine (H). Hypoxanthine can bind to cytosine, and when the HC base pair is replicated, it becomes a GC (thus, an A → G base change).[42]
Over time, base changes in the DNA sequence can arise from deamination mutations. When adenine is deaminated, it becomes hypoxanthine, which can pair with cytosine. During replication, the cytosine will pair with guanine, causing an A → G base change.
In cpDNA, there are several A → G deamination gradients. DNA becomes susceptible to deamination events when it is single stranded. When replication forks form, the strand not being copied is single stranded, and thus at risk for A → G deamination. Therefore, gradients in deamination indicate that replication forks were most likely present and the direction that they initially opened (the highest gradient is most likely nearest the start site because it was single stranded for the longest amount of time).[40] This mechanism is still the leading theory today; however, a second theory suggests that most cpDNA is actually linear and replicates through homologous recombination. It further contends that only a minority of the genetic material is kept in circular chromosomes while the rest is in branched, linear, or other complex structures.[40][12]
Alternative model of replication
One of the main competing models for cpDNA asserts that most cpDNA is linear and participates in homologous recombination and replication structures similar to bacteriophage T4.[12] It has been established that some plants have linear cpDNA, such as maize, and that more still contain complex structures that scientists do not yet understand;[12] however, the predominant view today is that most cpDNA is circular. When the original experiments on cpDNA were performed, scientists did notice linear structures; however, they attributed these linear forms to broken circles.[12] If the branched and complex structures seen in cpDNA experiments are real and not artifacts of concatenated circular DNA or broken circles, then a D-loop mechanism of replication is insufficient to explain how those structures would replicate.[12] At the same time, homologous recombination does not explain the multiple A → G gradients seen in plastomes.[40] This shortcoming is one of the biggest for the linear structure theory.
The movement of so many chloroplast genes to the nucleus means that many chloroplast proteins that were supposed to be translated in the chloroplast are now synthesized in the cytoplasm. This means that these proteins must be directed back to the chloroplast, and imported through at least two chloroplast membranes.[43]
Curiously, around half of the protein products of transferred genes aren't even targeted back to the chloroplast. Many became exaptations, taking on new functions like participating in cell division, protein routing, and even disease resistance. A few chloroplast genes found new homes in the mitochondrial genome—most became nonfunctional pseudogenes, though a few tRNA genes still work in the mitochondrion.[27] Some transferred chloroplast DNA protein products get directed to the secretory pathway[27] (though many secondary plastids are bounded by an outermost membrane derived from the host's cell membrane, and therefore topologically outside of the cell, because to reach the chloroplast from the cytosol, you have to cross the cell membrane, just like if you were headed for the extracellular space. In those cases, chloroplast-targeted proteins do initially travel along the secretory pathway).[44]
Polypeptides, the precursors of proteins, are chains of amino acids. The two ends of a polypeptide are called the N-terminus, or amino end, and the C-terminus, or carboxyl end.[45] For many (but not all)[46] chloroplast proteins encoded by nuclear genes, cleavable transit peptides are added to the N-termini of the polypeptides, which are used to help direct the polypeptide to the chloroplast for import[43][47] (N-terminal transit peptides are also used to direct polypeptides to plant mitochondria).[48] N-terminal transit sequences are also called presequences[43] because they are located at the "front" end of a polypeptide—ribosomes synthesize polypeptides from the N-terminus to the C-terminus.[45]
Not all chloroplast proteins include a N-terminal cleavable transit peptide though.[43] Some include the transit sequence within the functional part of the protein itself.[43] A few have their transit sequence appended to their C-terminus instead.[49] Most of the polypeptides that lack N-terminal targeting sequences are the ones that are sent to the outer chloroplast membrane, plus at least one sent to the inner chloroplast membrane.[43]
Phosphorylation changes the polypeptide's shape,[50] making it easier for 14-3-3 proteins to attach to the polypeptide.[43][51] In plants, 14-3-3 proteins only bind to chloroplast preproteins.[48] It is also bound by the heat shock proteinHsp70 that keeps the polypeptide from folding prematurely.[43] This is important because it prevents chloroplast proteins from assuming their active form and carrying out their chloroplast functions in the wrong place—the cytosol.[48][51] At the same time, they have to keep just enough shape so that they can be recognized and imported into the chloroplast.[48]
The heat shock protein and the 14-3-3 proteins together form a cytosolic guidance complex that makes it easier for the chloroplast polypeptide to get imported into the chloroplast.[43]
Alternatively, if a chloroplast preprotein's transit peptide is not phosphorylated, a chloroplast preprotein can still attach to a heat shock protein or Toc159. These complexes can bind to the TOC complex on the outer chloroplast membrane using GTP energy.[43]
The translocon on the outer chloroplast membrane (TOC)
The first three proteins form a core complex that consists of one Toc159, four to five Toc34s, and four Toc75s that form four holes in a disk 13 nanometers across. The whole core complex weighs about 500 kilodaltons. The other two proteins, Toc64 and Toc12, are associated with the core complex but are not part of it.[46]
Toc34 and 33
Toc34 from a pea plant. Toc34 has three almost identical molecules (shown in slightly different shades of green), each of which forms a dimer with one of its adjacent molecules. Part of a GDP molecule binding site is highlighted in pink.[52]
Toc34's job is to catch some chloroplast preproteins in the cytosol and hand them off to the rest of the TOC complex.[43] When GTP, an energy molecule similar to ATP attaches to Toc34, the protein becomes much more able to bind to many chloroplast preproteins in the cytosol.[43] The chloroplast preprotein's presence causes Toc34 to break GTP into guanosine diphosphate (GDP) and inorganic phosphate. This loss of GTP makes the Toc34 protein release the chloroplast preprotein, handing it off to the next TOC protein.[43] Toc34 then releases the depleted GDP molecule, probably with the help of an unknown GDP exchange factor. A domain of Toc159 might be the exchange factor that carry out the GDP removal. The Toc34 protein can then take up another molecule of GTP and begin the cycle again.[43]
Toc34 can be turned off through phosphorylation. A protein kinase drifting around on the outer chloroplast membrane can use ATP to add a phosphate group to the Toc34 protein, preventing it from being able to receive another GTP molecule, inhibiting the protein's activity. This might provide a way to regulate protein import into chloroplasts.[43][51]
Arabidopsis thaliana has two homologous proteins, AtToc33 and AtToc34 (The At stands for Arabidopsis thaliana),[43][51] which are each about 60% identical in amino acid sequence to Toc34 in peas (called psToc34).[51] AtToc33 is the most common in Arabidopsis,[51] and it is the functional analogue of Toc34 because it can be turned off by phosphorylation. AtToc34 on the other hand cannot be phosphorylated.[43][51]
Toc159 probably works a lot like Toc34, recognizing proteins in the cytosol using GTP. It can be regulated through phosphorylation, but by a different protein kinase than the one that phosphorylates Toc34.[46] Its M-domain forms part of the tunnel that chloroplast preproteins travel through, and seems to provide the force that pushes preproteins through, using the energy from GTP.[43]
Toc159 is not always found as part of the TOC complex—it has also been found dissolved in the cytosol. This suggests that it might act as a shuttle that finds chloroplast preproteins in the cytosol and carries them back to the TOC complex. There isn't a lot of direct evidence for this behavior though.[43]
A family of Toc159 proteins, Toc159, Toc132, Toc120, and Toc90 have been found in Arabidopsis thaliana. They vary in the length of their A-domains, which is completely gone in Toc90. Toc132, Toc120, and Toc90 seem to have specialized functions in importing stuff like nonphotosynthetic preproteins, and can't replace Toc159.[43]
Toc75
β-barrel The general shape of a β-barrel is a hollow cylinder lined by multiple β-sheets. Note that the protein depicted is not Toc75 specifically.
Toc75 is the most abundant protein on the outer chloroplast envelope. It is a transmembrane tube that forms most of the TOC pore itself. Toc75 is a β-barrel channel lined by 16 β-pleated sheets.[43] The hole it forms is about 2.5 nanometers wide at the ends, and shrinks to about 1.4–1.6 nanometers in diameter at its narrowest point—wide enough to allow partially folded chloroplast preproteins to pass through.[43]
Toc75 can also bind to chloroplast preproteins, but is a lot worse at this than Toc34 or Toc159.[43]
The translocon on the inner chloroplast membrane (TIC)
The TIC translocon, or translocon on the inner chloroplast membrane translocon[43] is another protein complex that imports proteins across the inner chloroplast envelope. Chloroplast polypeptide chains probably often travel through the two complexes at the same time, but the TIC complex can also retrieve preproteins lost in the intermembrane space.[43]
Tic100 is a nuclear encoded protein that's 871 amino acids long. The 871 amino acids collectively weigh slightly less than 100 thousand daltons, and since the mature protein probably doesn't lose any amino acids when itself imported into the chloroplast (it has no cleavable transit peptide), it was named Tic100. Tic100 is found at the edges of the 1 million dalton complex on the side that faces the chloroplast intermembrane space.[54]
Tic56
Tic56 is also a nuclear encoded protein. The preprotein its gene encodes is 527 amino acids long, weighing close to 62 thousand daltons; the mature form probably undergoes processing that trims it down to something that weighs 56 thousand daltons when it gets imported into the chloroplast. Tic56 is largely embedded inside the 1 million dalton complex.[54]
Tic56 and Tic100 are highly conserved among land plants, but they don't resemble any protein whose function is known. Neither has any transmembrane domains.[54]
1 2 3 4 Shaw J, Lickey EB, Schilling EE, Small RL (March 2007). "Comparison of whole chloroplast genome sequences to choose noncoding regions for phylogenetic studies in angiosperms: the tortoise and the hare III". American Journal of Botany. 94 (3): 275–88. doi:10.3732/ajb.94.3.275. PMID21636401. S2CID30501148.
↑ Tillich M, Krause K (July 2010). "The ins and outs of editing and splicing of plastid RNAs: lessons from parasitic plants". New Biotechnology. Special Issue: Biotechnology Annual Review 2010RNA Basics and Biotechnology Applications. 27 (3): 256–66. doi:10.1016/j.nbt.2010.02.020. PMID20206308.
↑ Sun YJ, Forouhar F, Li Hm HM, Tu SL, Yeh YH, Kao S, Shr HL, Chou CC, Chen C, Hsiao CD (February 2002). "Crystal structure of pea Toc34, a novel GTPase of the chloroplast protein translocon". Nature Structural Biology. 9 (2): 95–100. doi:10.1038/nsb744. PMID11753431. S2CID21855733.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.