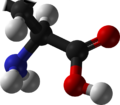
Proline (symbol Pro or P)[4] is an organic acid classed as a proteinogenic amino acid (used in the biosynthesis of proteins), although it does not contain the amino group-NH 2 but is rather a secondary amine. The secondary amine nitrogen is in the protonated form (NH2+) under biological conditions, while the carboxyl group is in the deprotonated −COO− form. The "side chain" from the α carbon connects to the nitrogen forming a pyrrolidine loop, classifying it as a aliphaticamino acid. It is non-essential in humans, meaning the body can synthesize it from the non-essential amino acid L-glutamate. It is encoded by all the codons starting with CC (CCU, CCC, CCA, and CCG).
Proline is the only proteinogenic amino acid which is a secondary amine, as the nitrogen atom is attached both to the α-carbon and to a chain of three carbons that together form a five-membered ring.
History and etymology
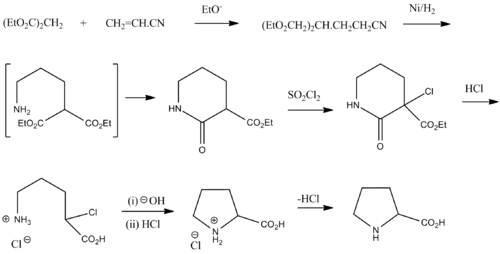
Proline was first isolated in 1900 by Richard Willstätter who obtained the amino acid while studying N-methylproline, and synthesized proline by the reaction of sodium salt of diethyl malonate with 1,3-dibromopropane. The next year, Emil Fischer isolated proline from casein and the decomposition products of γ-phthalimido-propylmalonic ester,[5] and published the synthesis of proline from phthalimide propylmalonic ester.[6]
The name proline comes from pyrrolidine, one of its constituents.[7]
A diet rich in proline was linked to an increased risk of depression in humans in a study from 2022 that was tested on a limited pre-clinical trial on humans and primarily in other organisms. Results were significant in the other organisms.[16]
Properties in protein structure
The distinctive cyclic structure of proline's side chain gives proline an exceptional conformational rigidity compared to other amino acids. It also affects the rate of peptide bond formation between proline and other amino acids. When proline is bound as an amide in a peptide bond, its nitrogen is not bound to any hydrogen, meaning it cannot act as a hydrogen bond donor, but can be a hydrogen bond acceptor.
Peptide bond formation with incoming Pro-tRNAPro in the ribosome is considerably slower than with any other tRNAs, which is a general feature of N-alkylamino acids.[17] Peptide bond formation is also slow between an incoming tRNA and a chain ending in proline; with the creation of proline-proline bonds slowest of all.[18]
The exceptional conformational rigidity of proline affects the secondary structure of proteins near a proline residue and may account for proline's higher prevalence in the proteins of thermophilic organisms. Protein secondary structure can be described in terms of the dihedral anglesφ, ψ and ω[broken anchor] of the protein backbone. The cyclic structure of proline's side chain locks the angle φ at approximately −65°.[19]
Proline acts as a structural disruptor in the middle of regular secondary structure elements such as alpha helices and beta sheets; however, proline is commonly found as the first residue of an alpha helix and also in the edge strands of beta sheets. Proline is also commonly found in turns (another kind of secondary structure), and aids in the formation of beta turns. This may account for the curious fact that proline is usually solvent-exposed, despite having a completely aliphatic side chain.
Multiple prolines and/or hydroxyprolines in a row can create a polyproline helix, the predominant secondary structure in collagen. The hydroxylation of proline by prolyl hydroxylase (or other additions of electron-withdrawing substituents such as fluorine) increases the conformational stability of collagen significantly.[20] Hence, the hydroxylation of proline is a critical biochemical process for maintaining the connective tissue of higher organisms. Severe diseases such as scurvy can result from defects in this hydroxylation, e.g., mutations in the enzyme prolyl hydroxylase or lack of the necessary ascorbate (vitamin C) cofactor.
Cis–trans isomerization
Peptide bonds to proline, and to other N-substituted amino acids (such as sarcosine), are able to populate both the cis and trans isomers. Most peptide bonds overwhelmingly adopt the trans isomer (typically 99.9% under unstrained conditions), chiefly because the amide hydrogen (trans isomer) offers less steric repulsion to the preceding Cα atom than does the following Cα atom (cis isomer). By contrast, the cis and trans isomers of the X-Pro peptide bond (where X represents any amino acid) both experience steric clashes with the neighboring substitution and have a much lower energy difference. Hence, the fraction of X-Pro peptide bonds in the cis isomer under unstrained conditions is significantly elevated, with cis fractions typically in the range of 3-10%.[21] However, these values depend on the preceding amino acid, with Gly[22] and aromatic[23] residues yielding increased fractions of the cis isomer. Cis fractions up to 40% have been identified for aromatic–proline peptide bonds.[24]
From a kinetic standpoint, cis–trans proline isomerization is a very slow process that can impede the progress of protein folding by trapping one or more proline residues crucial for folding in the non-native isomer, especially when the native protein requires the cis isomer. This is because proline residues are exclusively synthesized in the ribosome as the trans isomer form. All organisms possess prolyl isomeraseenzymes to catalyze this isomerization, and some bacteria have specialized prolyl isomerases associated with the ribosome. However, not all prolines are essential for folding, and protein folding may proceed at a normal rate despite having non-native conformers of many X–Pro peptide bonds.
Proline is one of the two amino acids that do not follow along with the typical Ramachandran plot, along with glycine. Due to the ring formation connected to the beta carbon, the ψ and φ angles about the peptide bond have fewer allowable degrees of rotation. As a result, it is often found in "turns" of proteins as its free entropy (ΔS) is not as comparatively large to other amino acids and thus in a folded form vs. unfolded form, the change in entropy is smaller. Furthermore, proline is rarely found in α and β structures as it would reduce the stability of such structures, because its side chain α-nitrogen can only form one nitrogen bond.
Additionally, proline is the only amino acid that does not form a red-purple colour when developed by spraying with ninhydrin for uses in chromatography. Proline, instead, produces an orange-yellow colour.
↑ Plimmer RH (1912) [1908], Plimmer RH, Hopkins FG (eds.), The chemical composition of the proteins, Monographs on biochemistry, vol.Part I. Analysis (2nded.), London: Longmans, Green and Co., p.130, retrieved September 20, 2010
↑ Thomas KM, Naduthambi D, Zondlo NJ (February 2006). "Electronic control of amide cis–trans isomerism via the aromatic-prolyl interaction". Journal of the American Chemical Society. 128 (7): 2216–2217. doi:10.1021/ja057901y. PMID16478167.
↑ Siebert KJ. "Haze and Foam". Cornell AgriTech. Archived from the original on 2010-07-11. Retrieved 2010-07-13. Accessed July 12, 2010.
↑ Pazuki A, Asghari J, Sohani MM, Pessarakli M, Aflaki F (2015). "Effects of Some Organic Nitrogen Sources and Antibiotics on Callus Growth of Indica Rice Cultivars". Journal of Plant Nutrition. 38 (8): 1231–1240. Bibcode:2015JPlaN..38.1231P. doi:10.1080/01904167.2014.983118. S2CID84495391.
Balbach J, Schmid FX (2000). "Proline isomerization and its catalysis in protein folding". In Pain RH (ed.). Mechanisms of Protein Folding (2nded.). Oxford University Press. pp.212–249. ISBN978-0-19-963788-1..
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.