Definitions
The literature knows two major definitions of the order of a kernel:
Definition 1
Let be an integer. Then, is a kernel of order if the functions are integrable and satisfy [2]
In statistics, the order of a kernel is the degree of the first non-zero moment of a kernel. [1]
The literature knows two major definitions of the order of a kernel:
Let be an integer. Then, is a kernel of order if the functions are integrable and satisfy [2]
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.
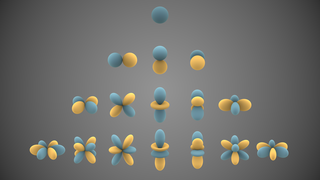
In mathematics and physical science, spherical harmonics are special functions defined on the surface of a sphere. They are often employed in solving partial differential equations in many scientific fields.
In probability theory and statistics, a Gaussian process is a stochastic process, such that every finite collection of those random variables has a multivariate normal distribution, i.e. every finite linear combination of them is normally distributed. The distribution of a Gaussian process is the joint distribution of all those random variables, and as such, it is a distribution over functions with a continuous domain, e.g. time or space.
In mathematical analysis, a function of bounded variation, also known as BV function, is a real-valued function whose total variation is bounded (finite): the graph of a function having this property is well behaved in a precise sense. For a continuous function of a single variable, being of bounded variation means that the distance along the direction of the y-axis, neglecting the contribution of motion along x-axis, traveled by a point moving along the graph has a finite value. For a continuous function of several variables, the meaning of the definition is the same, except for the fact that the continuous path to be considered cannot be the whole graph of the given function, but can be every intersection of the graph itself with a hyperplane parallel to a fixed x-axis and to the y-axis.
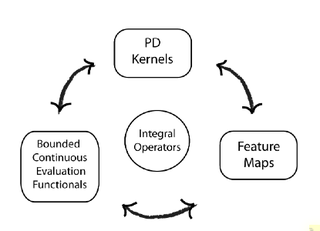
In functional analysis, a reproducing kernel Hilbert space (RKHS) is a Hilbert space of functions in which point evaluation is a continuous linear functional. Roughly speaking, this means that if two functions and in the RKHS are close in norm, i.e., is small, then and are also pointwise close, i.e., is small for all . The reverse does not need to be true.
In linear algebra, the Gram matrix of a set of vectors in an inner product space is the Hermitian matrix of inner products, whose entries are given by the inner product . If the vectors are the columns of matrix then the Gram matrix is in the general case that the vector coordinates are complex numbers, which simplifies to for the case that the vector coordinates are real numbers.
In mathematics, and specifically in potential theory, the Poisson kernel is an integral kernel, used for solving the two-dimensional Laplace equation, given Dirichlet boundary conditions on the unit disk. The kernel can be understood as the derivative of the Green's function for the Laplace equation. It is named for Siméon Poisson.
In complex analysis, functional analysis and operator theory, a Bergman space is a function space of holomorphic functions in a domain D of the complex plane that are sufficiently well-behaved at the boundary that they are absolutely integrable. Specifically, for 0 < p < ∞, the Bergman space Ap(D) is the space of all holomorphic functions in D for which the p-norm is finite:
In statistics, a semiparametric model is a statistical model that has parametric and nonparametric components.
Nonparametric regression is a category of regression analysis in which the predictor does not take a predetermined form but is constructed according to information derived from the data. That is, no parametric form is assumed for the relationship between predictors and dependent variable. Nonparametric regression requires larger sample sizes than regression based on parametric models because the data must supply the model structure as well as the model estimates.
In statistics, semiparametric regression includes regression models that combine parametric and nonparametric models. They are often used in situations where the fully nonparametric model may not perform well or when the researcher wants to use a parametric model but the functional form with respect to a subset of the regressors or the density of the errors is not known. Semiparametric regression models are a particular type of semiparametric modelling and, since semiparametric models contain a parametric component, they rely on parametric assumptions and may be misspecified and inconsistent, just like a fully parametric model.
In probability theory, heavy-tailed distributions are probability distributions whose tails are not exponentially bounded: that is, they have heavier tails than the exponential distribution. In many applications it is the right tail of the distribution that is of interest, but a distribution may have a heavy left tail, or both tails may be heavy.
The term kernel is used in statistical analysis to refer to a window function. The term "kernel" has several distinct meanings in different branches of statistics.
In statistics, Kernel regression is a non-parametric technique to estimate the conditional expectation of a random variable. The objective is to find a non-linear relation between a pair of random variables X and Y.
A kernel smoother is a statistical technique to estimate a real valued function as the weighted average of neighboring observed data. The weight is defined by the kernel, such that closer points are given higher weights. The estimated function is smooth, and the level of smoothness is set by a single parameter.
In mathematical analysis, the Pólya–Szegő inequality states that the Sobolev energy of a function in a Sobolev space does not increase under symmetric decreasing rearrangement. The inequality is named after the mathematicians George Pólya and Gábor Szegő.
Fractional wavelet transform (FRWT) is a generalization of the classical wavelet transform (WT). This transform is proposed in order to rectify the limitations of the WT and the fractional Fourier transform (FRFT). The FRWT inherits the advantages of multiresolution analysis of the WT and has the capability of signal representations in the fractional domain which is similar to the FRFT.
In machine learning, the kernel embedding of distributions comprises a class of nonparametric methods in which a probability distribution is represented as an element of a reproducing kernel Hilbert space (RKHS). A generalization of the individual data-point feature mapping done in classical kernel methods, the embedding of distributions into infinite-dimensional feature spaces can preserve all of the statistical features of arbitrary distributions, while allowing one to compare and manipulate distributions using Hilbert space operations such as inner products, distances, projections, linear transformations, and spectral analysis. This learning framework is very general and can be applied to distributions over any space on which a sensible kernel function may be defined. For example, various kernels have been proposed for learning from data which are: vectors in , discrete classes/categories, strings, graphs/networks, images, time series, manifolds, dynamical systems, and other structured objects. The theory behind kernel embeddings of distributions has been primarily developed by Alex Smola, Le Song , Arthur Gretton, and Bernhard Schölkopf. A review of recent works on kernel embedding of distributions can be found in.
Regularized least squares (RLS) is a family of methods for solving the least-squares problem while using regularization to further constrain the resulting solution.
In the study of artificial neural networks (ANNs), the neural tangent kernel (NTK) is a kernel that describes the evolution of deep artificial neural networks during their training by gradient descent. It allows ANNs to be studied using theoretical tools from kernel methods.
| | This statistics-related article is a stub. You can help Wikipedia by expanding it. |




